1) Indekso samprata
Indeksas yra įrankis, suteikiantis greitą prieigą prie lentelės eilučių pagal vieno ar kelių stulpelių reikšmes.
Šis operatorius yra labai įvairus, nes jis nėra standartizuotas, nes standartai nesprendžia našumo problemų.
2) Indeksų kūrimas
KURTI RODYKLĄ
ĮJUNGTA ()
3) Indeksų keitimas ir trynimas
Indekso veiklai valdyti naudojamas operatorius:
ALTER INDEX
Norėdami pašalinti indeksą, naudokite operatorių:
NURODYTI INDEKSO
a) Lentelių pasirinkimo taisyklės
1. Patartina indeksuoti lenteles, kuriose pasirinkta ne daugiau kaip 5% eilučių.
2. Lentelės, neturinčios SELECT sakinio WHERE dublikatų, turėtų būti indeksuojamos.
3. Nepraktiška indeksuoti dažnai atnaujinamas lenteles.
4. Nedera indeksuoti lenteles, kurios užima ne daugiau kaip 2 puslapius (Oracle tai yra mažiau nei 300 eilučių), nes visas jos nuskaitymas neužtrunka ilgiau.
b) Stulpelių pasirinkimo taisyklės
1. Pirminiai ir išoriniai raktai – dažnai naudojami lentelėms sujungti, duomenims gauti ir paieškai. Tai visada unikalūs indeksai su maksimaliu naudingumu
2. Kai naudojate nuorodos vientisumo parinktis, FK visada reikia rodyklės.
3. Stulpeliai, pagal kuriuos dažnai rūšiuojami ir (arba) grupuojami duomenys.
4. Stulpeliai, kurių dažnai ieškoma SELECT sakinio WHERE sąlygoje.
5. Neturėtumėte kurti indeksų ant ilgų aprašomųjų stulpelių.
c) Sudėtinių indeksų kūrimo principai
1. Sudėtiniai indeksai yra geri, jei atskiri stulpeliai turi keletą unikalių reikšmių, tačiau sudėtinis indeksas suteikia daugiau unikalumo.
2. Jei visos SELECT teiginiu parinktos reikšmės priklauso sudėtiniam indeksui, tada reikšmės parenkamos iš indekso.
3. Sudėtinis indeksas turėtų būti sukurtas, jei WHERE sąlyga naudoja dvi ar daugiau reikšmių, sujungtų su AND operatoriumi.
d) Nerekomenduojama kurti
Nerekomenduojama kurti indeksų stulpeliuose, įskaitant sudėtinius, kurie:
1. Retai naudojamas ieškant, sujungiant ir rūšiuojant užklausų rezultatus.
2. Įtraukite dažnai besikeičiančias reikšmes, kurios reikalauja dažni atnaujinimai indeksas sulėtina duomenų bazės veikimą.
3. Turi būti nedaug unikalių verčių (mažiau nei 10 % m/f) arba vyraujantis skaičius eilučių su viena ar dviem reikšmėmis (tiekėjo gyvenamasis miestas yra Maskva).
4. WHERE sakinyje joms taikomos funkcijos ar išraiška, o indeksas neveikia.
e) Mes neturime pamiršti
Turėtumėte stengtis sumažinti indeksų skaičių, nes didelis jų skaičius sumažina duomenų atnaujinimo greitį. Taigi MS SQL serveris rekomenduoja sukurti ne daugiau kaip 16 indeksų vienoje lentelėje.
Paprastai indeksai kuriami užklausos tikslais ir nuorodos vientisumui palaikyti.
Jei indeksas nenaudojamas užklausoms, jis turėtų būti ištrintas ir nuorodos vientisumas turi būti užtikrintas naudojant trigerius.
Pateikti greita prieiga Indeksai naudojami Oracle DBMS lentelės eilutėse. Indeksai suteikia greitą prieigą prie duomenų atliekant operacijas, kuriose pasirenkamas palyginti mažas lentelės eilučių skaičius.
Nors „Oracle“ leidžia neribotą skaičių indeksų lentelėje, indeksai naudingi tik tada, kai jie naudojami užklausoms paspartinti. Priešingu atveju jie tik užima vietą ir sumažina serverio našumą atnaujinant indeksuotus stulpelius. Norėdami nustatyti, kaip indeksai naudojami jūsų užklausose, turite naudoti funkciją EXPLAIN PLAN (vykdymo ir statistikos planas). Kartais, jei indeksas nenaudojamas pagal numatytuosius nustatymus, norėdami naudoti indeksą, galite naudoti užklausos patarimus.
Sukurkite indeksus įdėję lentelės duomenis
Paprastai prieš kurdami indeksus duomenis įterpiate arba įkeliate į lentelę. Priešingu atveju, indeksų atnaujinimo išlaidos sulėtins įterpimo arba įkėlimo operacijas. Vienintelė šios taisyklės išimtis yra klasterio rakto indeksas. Jį galima sukurti tik tuščiam klasteriui.
Perjunkite į laikiną stalo erdvę, kad išvengtumėte problemų laisva vieta, kurdami indeksus
Kuriant rodyklę lentelėje, kurioje jau yra duomenų, Oracle reikalauja papildomos atminties rūšiavimui. Tam naudojama rūšiavimo atminties sritis, skirta indekso kūrėjui (kiekvienam vartotojui skirta suma nustatoma inicijavimo parametru SORT_AREA_SIZE), be to, Oracle serveris turi išplauti ir sukeisti informaciją iš laikinų segmentų, skirtų kuriant indeksą. Jei indeksas labai didelis, rekomenduojama atlikti šiuos veiksmus:
- Sukurkite naują laikiną lentelės erdvę naudodami teiginį CREATE TABLESPACE.
- Nurodykite šią naują laikiną erdvę teiginio ALTER USER parametre TEMPORARY TABLESPACE.
- Sukurkite indeksą naudodami CREATE INDEX teiginį.
- Išmeskite šią lentelės sritį naudodami komandą DROP TABLESPACE. Tada naudokite teiginį ALTER USER, kad atkurtumėte pradinę lentelės sritį kaip laikiną.
Pasirinkite tinkamas lenteles ir stulpelius indeksavimui
Norėdami nustatyti, kada sukurti indeksą, vadovaukitės šiomis gairėmis.
- Sukurkite indeksą, jei dažnai iš didelės lentelės nuskaitote palyginti nedidelį skaičių (mažiau nei 15%) eilučių. Šis procentas labai priklauso nuo santykinio lentelės nuskaitymo greičio ir nuo eilutės duomenų sugrupavimo indekso rakte. Kuo didesnis naršymo greitis, tuo mažesnis procentas; kuo labiau sugrupuoti eilutės duomenys, tuo didesnis procentas.
- Indekso stulpeliai, naudojami sujungimuose, siekiant pagerinti kelių lentelių sujungimo našumą.
- Indeksai sukuriami automatiškai, remiantis pirminiais ir unikaliais raktais.
- Mažų lentelių indeksuoti nereikia. Jei pastebėsite, kad užklausos vykdymo laikas žymiai pailgėjo, greičiausiai jis tapo didelis.
- stulpelio reikšmės yra palyginti unikalios;
- didelis verčių diapazonas (tinka įprastiems indeksams);
- mažas reikšmių diapazonas (tinka bitų indeksams);
- labai reti stulpeliai (daug neapibrėžtų, „tuščių“ reikšmių), tačiau užklausos dažniausiai susijusios su prasmingomis eilėmis. Šiuo atveju pageidautina palyginti visas nenulines reikšmes:
WHERE COL_X > -9,99 *galia(10, 125), o ne
WHERE COL_X NOT NULL Taip yra todėl, kad pirmuoju atveju naudojamas COL_X indeksas (darant prielaidą, kad COL_X stulpelis yra skaitinio tipo).
Apribokite indeksų skaičių vienoje lentelėje
Kuo daugiau indeksų, tuo didesnės pridėtinės išlaidos keičiant lentelę. Kai eilutės pridedamos arba ištrinamos, atnaujinami visi lentelės indeksai. Kai stulpelis atnaujinamas, visi indeksai, kuriuose jis dalyvauja, taip pat turi būti atnaujinti.
Indeksų atveju turite pasverti užklausų našumo padidėjimą ir našumo nuobaudas už atnaujinimus. Pavyzdžiui, jei lentelė iš esmės yra tik skaitoma, galite plačiai naudoti indeksus; bet jei lentelė dažnai atnaujinama, patartina kuo labiau sumažinti indeksų naudojimą.
Pasirinkite sudėtinių indeksų stulpelių tvarką
Nors sakinyje CREATE INDEX stulpelius galima nurodyti bet kokia tvarka, CREATE INDEX sakinio stulpelių tvarka gali turėti įtakos užklausos našumui. Paprastai stulpeliai, kurie bus naudojami dažniausiai, pateikiami pirmieji indekse. Galite sukurti sudėtinį indeksą (naudodami kelis stulpelius), kurį galite naudoti užklausai dėl visų į indeksą įtrauktų stulpelių arba tik kai kurių.
Surinkite statistiką, kad tinkamai naudotumėte indeksus
Rodyklės gali būti naudojamos efektyviau, jei duomenų bazėje renkama ir palaikoma statistika apie užklausose naudojamas lenteles. Kurdami indeksą galite rinkti statistiką nurodydami raktažodį APSKAIČIUOTI STATISTIKĄ sakinyje CREATE INDEX. Kadangi duomenys nuolat atnaujinami, o reikšmių pasiskirstymas kinta, statistika turėtų būti periodiškai atnaujinama naudojant DBMS_STATS.GATHER_TABLE_STATISTICS ir DBMS_STATS.GATHER_SCHEMA_STATISTICS procedūras.
Sunaikinkite nereikalingus indeksus
Indeksas ištrinamas šiais atvejais:
- jei indekso naudojimas nepagerina užklausos našumo. Ši situacija atsiranda, jei lentelė yra per maža arba jei lentelėje yra daug eilučių, tačiau kelios iš jų yra indekso įrašai;
- jei jūsų prašymuose pateikti pasiūlymus nenaudojamas indeksas;
- jei indeksas taip pat nuleidžiamas prieš jį atkuriant.
Indeksai kuriami lentelės ir rodinio stulpeliuose. Indeksai suteikia galimybę greitai ieškoti duomenų pagal tų stulpelių reikšmes. Pavyzdžiui, jei sukuriate pirminio rakto indeksą ir tada ieškote duomenų eilutės naudodami pirminio rakto reikšmes, tada SQL serveris pirmiausia suras indekso reikšmę, o tada naudos indeksą, kad greitai surastų visą duomenų eilutę. Be indekso bus atliktas visas lentelės eilučių nuskaitymas, o tai gali turėti didelės įtakos našumui.
Daugumoje lentelės arba rodinio stulpelių galite sukurti indeksą. Išimtis daugiausia yra stulpeliai su duomenų tipais dideliems objektams saugoti ( LOB), toks kaip vaizdas, tekstą arba varchar (maks.). Taip pat galite kurti indeksus stulpeliuose, skirtuose duomenims saugoti tokiu formatu XML, tačiau šių indeksų struktūra šiek tiek skiriasi nuo standartinių ir jų svarstymas nepatenka į šio straipsnio taikymo sritį. Be to, straipsnyje nekalbama stulpelių parduotuvė indeksai. Vietoj to, aš sutelkiu dėmesį į tuos indeksus, kurie dažniausiai naudojami duomenų bazėse SQL serveris.
Rodyklė susideda iš puslapių rinkinio, indekso mazgų, kurie yra suskirstyti į medžio struktūrą - subalansuotas medis. Ši struktūra yra hierarchinio pobūdžio ir prasideda šaknies mazgu hierarchijos viršuje, o lapų mazgais – apačioje, kaip parodyta paveikslėlyje: 
Kai pateikiate užklausą indeksuotame stulpelyje, užklausos variklis paleidžiamas šakninio mazgo viršuje ir juda žemyn per tarpinius mazgus, o kiekviename tarpiniame sluoksnyje yra daugiau nei Detali informacija apie duomenis. Užklausos variklis ir toliau juda per indekso mazgus, kol pasiekia apatinį indekso lapų lygį. Pavyzdžiui, jei indeksuotame stulpelyje ieškote reikšmės 123, užklausos variklis pirmiausia nustatys puslapį pirmame tarpiniame pagrindinio lygmens lygyje. Tokiu atveju pirmasis puslapis nurodo reikšmę nuo 1 iki 100, o antrasis – nuo 101 iki 200, todėl užklausos variklis pasieks antrąjį šio vidutinio lygio puslapį. Toliau pamatysite, kad turėtumėte atsiversti trečią kito vidutinio lygio puslapį. Iš čia užklausos posistemis nuskaitys paties indekso reikšmę žemesniu lygiu. Rodyklės lapuose gali būti arba patys lentelės duomenys, arba tiesiog rodyklė į eilutes su duomenimis lentelėje, atsižvelgiant į indekso tipą: sugrupuotas indeksas arba negrupuotas indeksas.
Sugrupuotas indeksas
Sugrupuotas indeksas saugo faktines duomenų eilutes indekso lapuose. Grįžtant prie ankstesnio pavyzdžio, tai reiškia, kad duomenų eilutė, susieta su rakto reikšme 123, bus saugoma pačiame indekse. Svarbi savybė Sugrupuotas indeksas reiškia, kad visos reikšmės yra rūšiuojamos tam tikra tvarka, didėjančia arba mažėjančia tvarka. Todėl lentelė arba rodinys gali turėti tik vieną sugrupuotą indeksą. Be to, reikia pažymėti, kad duomenys lentelėje saugomi surūšiuota forma tik tuo atveju, jei šioje lentelėje buvo sukurtas sugrupuotas indeksas.Lentelė, kurioje nėra sugrupuoto indekso, vadinama krūva.
Nesugrupuotas indeksas
Skirtingai nuo sugrupuoto indekso, negrupuoto indekso lapuose yra tik tie stulpeliai ( Raktas), pagal kurį nustatomas šis indeksas, taip pat yra rodyklė į lentelės eilutes su tikrais duomenimis. Tai reiškia, kad antrinės užklausos sistemai reikia atlikti papildomą operaciją, kad būtų galima rasti ir gauti reikiamus duomenis. Duomenų rodyklės turinys priklauso nuo to, kaip duomenys saugomi: sugrupuota lentelė ar krūva. Jei žymeklis nurodo į sugrupuotą lentelę, ji nurodo sugrupuotą indeksą, kurį galima naudoti norint rasti tikruosius duomenis. Jei žymeklis nurodo krūvą, tada jis nurodo konkretų duomenų eilutės identifikatorių. Nesugrupuotų indeksų negalima rūšiuoti kaip sugrupuotų indeksų, tačiau lentelėje ar rodinyje galite sukurti daugiau nei vieną negrupuotą indeksą iki 999. Tai nereiškia, kad turėtumėte sukurti kuo daugiau indeksų. Indeksai gali pagerinti arba pabloginti sistemos veikimą. Be galimybės sukurti kelis nesugrupuotus indeksus, taip pat galite įtraukti papildomų stulpelių ( įtrauktas stulpelis) į savo indeksą: indekso lapuose bus saugoma ne tik pačių indeksuotų stulpelių reikšmė, bet ir šių neindeksuotų papildomų stulpelių reikšmės. Šis metodas leis jums apeiti kai kuriuos indeksui taikomus apribojimus. Pavyzdžiui, galite įtraukti neindeksuojamą stulpelį arba apeiti indekso ilgio ribą (daugeliu atvejų 900 baitų).Indeksų tipai
Be to, kad indeksas yra sugrupuotas arba negrupuotas, jį galima konfigūruoti kaip sudėtinį indeksą, unikalų indeksą arba apimantį indeksą.Sudėtinis indeksas
Tokiame indekse gali būti daugiau nei vienas stulpelis. Į indeksą galite įtraukti iki 16 stulpelių, bet bendras jų ilgis ribojamas iki 900 baitų. Tiek sugrupuoti, tiek negrupuoti indeksai gali būti sudėtiniai.Unikalus indeksas
Šis indeksas užtikrina, kad kiekviena indeksuoto stulpelio reikšmė yra unikali. Jei indeksas yra sudėtinis, unikalumas taikomas visiems indekso stulpeliams, bet ne kiekvienam atskiram stulpeliui. Pavyzdžiui, jei stulpeliuose sukuriate unikalų indeksą VARDAS Ir PAVARDĖ, Tai pilnas vardas turi būti unikalus, tačiau galimi vardo ar pavardės dublikatai.Unikalus indeksas automatiškai sukuriamas, kai apibrėžiate stulpelio apribojimą: pirminį raktą arba unikalios vertės apribojimą:
- Pirminis raktas
Kai apibrėžiate pirminio rakto apribojimą viename ar daugiau stulpelių, tada SQL serveris automatiškai sukuria unikalų sugrupuotą indeksą, jei sugrupuotas indeksas nebuvo sukurtas anksčiau (šiuo atveju unikalus nesugrupuotas indeksas sukuriamas pirminiame rakte) - Vertybių unikalumas
Kai apibrėžiate vertybių unikalumo apribojimą, tada SQL serveris automatiškai sukuria unikalų nesugrupuotą indeksą. Galite nurodyti, kad būtų sukurtas unikalus sugrupuotas indeksas, jei lentelėje dar nebuvo sukurtas sugrupuotas indeksas
Dengimo indeksas
Toks indeksas leidžia konkrečiai užklausai iš karto gauti visus reikiamus duomenis iš indekso lapų be papildomos prieigos prie pačios lentelės įrašų.Indeksų projektavimas
Kad ir kokie būtų naudingi indeksai, jie turi būti kruopščiai sukurti. Kadangi indeksai gali užimti daug vietos diske, nenorite kurti daugiau indeksų nei reikia. Be to, indeksai automatiškai atnaujinami, kai atnaujinama pati duomenų eilutė, o tai gali sukelti papildomų išteklių sąnaudų ir našumo pablogėjimo. Kuriant indeksus, reikia atsižvelgti į keletą duomenų, susijusių su duomenų baze ir jos užklausomis.Duomenų bazė
Kaip minėta anksčiau, indeksai gali pagerinti sistemos našumą, nes jie suteikia užklausų varikliui greitą duomenų paieškos būdą. Tačiau taip pat turėtumėte atsižvelgti į tai, kaip dažnai ketinate įterpti, atnaujinti arba ištrinti duomenis. Kai keičiate duomenis, indeksai taip pat turi būti pakeisti, kad atspindėtų atitinkamus veiksmus su duomenimis, o tai gali žymiai sumažinti sistemos našumą. Planuodami indeksavimo strategiją, atsižvelkite į šias gaires:- Lentelėms, kurios dažnai atnaujinamos, naudokite kuo mažiau indeksų.
- Jei lentelėje yra daug duomenų, bet pakeitimai yra nedideli, naudokite tiek indeksų, kiek reikia, kad pagerintumėte užklausų našumą. Tačiau gerai pagalvokite prieš naudodami indeksus mažose lentelėse, nes... Gali būti, kad naudojant rodyklės paiešką gali užtrukti ilgiau nei tiesiog nuskaityti visas eilutes.
- Stenkitės, kad sugrupuotų indeksų laukai būtų kuo trumpesni. Geriausias būdas naudos sugrupuotą indeksą stulpeliuose su unikaliomis reikšmėmis ir neleis naudoti NULL. Štai kodėl pirminis raktas dažnai naudojamas kaip grupinis indeksas.
- Stulpelio verčių unikalumas turi įtakos indekso veikimui. Apskritai, kuo daugiau dublikatų turite stulpelyje, tuo prasčiau veikia indeksas. Kita vertus, kuo daugiau unikalių verčių, tuo geresnis indekso našumas. Jei įmanoma, naudokite unikalų indeksą.
- Sudėtinio indekso atveju atsižvelkite į indekso stulpelių tvarką. Stulpeliai, naudojami išraiškose KUR(Pavyzdžiui, WHERE FirstName = "Čarlis") turi būti pirmas indekse. Vėlesni stulpeliai turėtų būti išvardyti pagal jų verčių unikalumą (stulpeliai su didžiausiu unikalių reikšmių skaičiumi pateikiami pirmi).
- Taip pat galite nurodyti indeksą apskaičiuotuose stulpeliuose, jei jie atitinka tam tikrus reikalavimus. Pavyzdžiui, išraiškos, naudojamos stulpelio reikšmei gauti, turi būti deterministinės (visada pateikia tą patį rezultatą tam tikram įvesties parametrų rinkiniui).
Duomenų bazių užklausos
Kitas aspektas kuriant indeksus yra tai, kokios užklausos vykdomos duomenų bazėje. Kaip minėta anksčiau, turite apsvarstyti, kaip dažnai keičiasi duomenys. Be to, reikėtų vadovautis šiais principais:- Pabandykite įterpti arba modifikuoti kuo daugiau eilučių vienoje užklausoje, o ne tai daryti keliose atskirose užklausose.
- Sukurkite nesugrupuotą indeksą stulpeliuose, kurie dažnai naudojami kaip paieškos terminai jūsų užklausose. KUR ir jungtys viduje PRISIJUNK.
- Apsvarstykite galimybę indeksuoti stulpelius, naudojamus eilučių paieškos užklausose, kad būtų galima tiksliai atitikti vertes.
O dabar iš tikrųjų:
14 klausimų apie SQL serverio indeksus, kuriuos jums buvo gėda užduoti
Kodėl lentelėje negali būti dviejų sugrupuotų indeksų?
Norite trumpo atsakymo? Sugrupuotas indeksas yra lentelė. Kai kuriate lentelėje sugrupuotą indeksą, saugojimo modulis rūšiuoja visas lentelės eilutes didėjančia arba mažėjančia tvarka pagal indekso apibrėžimą. Sugrupuotas indeksas nėra atskiras subjektas, kaip ir kiti indeksai, o mechanizmas, skirtas rūšiuoti duomenis lentelėje ir palengvinti greitą prieigą prie duomenų eilučių.Įsivaizduokime, kad turite lentelę, kurioje yra pardavimo operacijų istorija. Pardavimo lentelėje pateikiama tokia informacija kaip užsakymo ID, produkto padėtis užsakyme, prekės numeris, prekės kiekis, užsakymo numeris ir data ir kt. Stulpeliuose sukuriate sugrupuotą indeksą Užsakymo ID Ir Linijos ID, surūšiuoti didėjančia tvarka, kaip parodyta toliau T-SQL kodas:
KURTI UNIKALĄ KLASTERINĘ RODEKĄ ix_oriderid_lineid DBO.Pardavimai(Užsakymo ID, Eilutės ID);
Kai paleisite šį scenarijų, visos lentelės eilutės bus fiziškai surūšiuotos pagal stulpelį OrderID, o po to pagal eilutės ID, tačiau patys duomenys liks viename loginiame bloke – lentelėje. Dėl šios priežasties negalite sukurti dviejų sugrupuotų indeksų. Gali būti tik viena lentelė su vienais duomenimis ir ta lentelė gali būti rūšiuojama tik vieną kartą tam tikra tvarka.
Jei sugrupuota lentelė suteikia daug privalumų, kam tada naudoti krūvą?
Tu teisus. Sugrupuotos lentelės yra puikios ir dauguma jūsų užklausų bus našesnės lentelėse, kuriose yra sugrupuotas indeksas. Tačiau kai kuriais atvejais stalus gali tekti palikti natūralią, nesugadintą, t.y. krūvos pavidalu ir kurkite tik nesugrupuotus indeksus, kad užklausos būtų vykdomos.Krūva, kaip prisimenate, saugo duomenis atsitiktine tvarka. Paprastai saugyklos posistemis prideda duomenis į lentelę ta tvarka, kuria jie įterpiami, tačiau saugyklos posistemis taip pat mėgsta perkelti eilutes, kad saugojimas būtų efektyvesnis. Dėl to jūs neturite galimybės numatyti, kokia tvarka bus saugomi duomenys.
Jei užklausos moduliui reikia rasti duomenų be negrupuoto indekso pranašumų, jis atliks visą lentelės nuskaitymą, kad surastų jam reikalingas eilutes. Ant labai mažų stalų tai paprastai nėra problema, tačiau didėjant krūvos dydžiui, našumas greitai krenta. Žinoma, gali padėti ir nesugrupuotas indeksas, naudojant rodyklę į failą, puslapį ir eilutę, kurioje saugomi reikalingi duomenys – dažniausiai tai yra daug geresnė lentelės nuskaitymo alternatyva. Nepaisant to, sunku palyginti sugrupuoto indekso naudą svarstant užklausos našumą.
Tačiau krūva gali padėti pagerinti našumą tam tikrose situacijose. Apsvarstykite lentelę su didelė sumaįterpimai, bet retai atnaujinami ar ištrinami duomenys. Pavyzdžiui, lentelė, kurioje saugomas žurnalas, pirmiausia naudojama reikšmėms įterpti, kol ji nėra archyvuojama. Krūvoje nematysite puslapių ieškojimo ir duomenų suskaidymo, kaip tai darytumėte su grupuotu indeksu, nes eilutės tiesiog pridedamos prie krūvos pabaigos. Per didelis puslapių padalijimas gali turėti didelės įtakos našumui, bet ne į gerą pusę. Apskritai, krūva leidžia palyginti neskausmingai įterpti duomenis ir jums nereikės susidurti su saugojimo ir priežiūros pridėtinėmis išlaidomis, kurios būtų patirtos naudojant sugrupuotą indeksą.
Tačiau duomenų atnaujinimo ir ištrynimo trūkumas neturėtų būti laikomas vienintele priežastimi. Duomenų atrankos metodas taip pat yra svarbus veiksnys. Pavyzdžiui, neturėtumėte naudoti krūvos, jei dažnai teikiate užklausas dėl duomenų diapazonų arba užklausų duomenis dažnai reikia rūšiuoti arba sugrupuoti.
Visa tai reiškia, kad turėtumėte apsvarstyti galimybę naudoti krūvą tik tada, kai dirbate su labai mažomis lentelėmis arba visa jūsų sąveika su lentele apsiriboja duomenų įterpimu, o jūsų užklausos yra labai paprastos (ir jūs naudojate nesugrupuotus indeksus šiaip). Kitu atveju laikykitės gerai suplanuoto sugrupuoto indekso, pvz., apibrėžto paprastame didėjančio klavišo lauke, pvz., plačiai naudojamą stulpelį su TAPATYBĖ.
Kaip pakeisti numatytąjį indekso užpildymo koeficientą?
Numatytojo indekso užpildymo koeficiento keitimas yra vienas dalykas. Kitas dalykas yra suprasti, kaip veikia numatytasis santykis. Tačiau pirmiausia ženkite kelis žingsnius atgal. Indekso užpildymo koeficientas nustato, kiek puslapyje yra vietos indeksui saugoti apatiniame lygyje (lapo lygyje) prieš pradedant pildyti. naujas puslapis. Pavyzdžiui, jei koeficientas nustatytas į 90, tada, kai indeksas augs, jis užims 90% puslapio ir tada pereis į kitą puslapį.Pagal numatytuosius nustatymus indekso užpildymo faktoriaus reikšmė yra SQL serveris yra 0, o tai yra 100. Todėl visi nauji indeksai automatiškai paveldi šį nustatymą, nebent kode konkrečiai nurodysite reikšmę, kuri skiriasi nuo standartinės sistemos reikšmės arba pakeisite numatytąją elgseną. Tu gali naudoti SQL serverio valdymo studija norėdami pakoreguoti numatytąją reikšmę arba paleisti sistemoje saugomą procedūrą sp_configure. Pavyzdžiui, šis rinkinys T-SQL Komandos nustato koeficiento reikšmę į 90 (pirmiausia turite pereiti į išplėstinių nustatymų režimą):
EXEC sp_configure "rodyti išplėstines parinktis", 1; EITI REKONFIGŪRUOTI; GO EXEC sp_configure "užpildymo koeficientas", 90; EITI REKONFIGŪRUOTI; EIK
Pakeitę indekso užpildymo koeficiento reikšmę, turite iš naujo paleisti paslaugą SQL serveris. Dabar galite patikrinti nustatytą reikšmę paleisdami sp_configure be nurodyto antrojo argumento:
EXEC sp_configure "užpildymo faktorius" GO
Ši komanda turėtų grąžinti 90 reikšmę. Dėl to visi naujai sukurti indeksai naudos šią reikšmę. Galite tai patikrinti sukurdami indeksą ir užklausę užpildymo koeficiento vertės:
NAUDOTI AdventureWorks2012; -- jūsų duomenų bazė GO CREATE NONCLUSTERED INDEX ix_žmonių_pavardė ON Asmuo.Asmuo(Pavardė); EITI PASIRINKTI užpildymo_faktorius FROM sys.indexes WHERE objekto_id = objekto_id("Asmuo.Asmuo") AND name = "ix_žmonių_pavardė";
IN šiame pavyzdyje lentelėje sukūrėme nesugrupuotą indeksą Asmuo duomenų bazėje AdventureWorks2012. Sukūrę indeksą, užpildymo faktoriaus reikšmę galime gauti iš sys.indexes sistemos lentelių. Užklausa turėtų pateikti 90.
Tačiau įsivaizduokime, kad ištrynėme indeksą ir vėl sukūrėme, bet dabar nurodėme konkrečią užpildymo koeficiento reikšmę:
CREATE NONCLUSTERED INDEX ix_žmonių_pavardė ON Asmuo.Asmuo(Pavardė) WITH (užpildymo faktorius=80); EITI PASIRINKTI užpildymo_faktorius FROM sys.indexes WHERE objekto_id = objekto_id("Asmuo.Asmuo") AND name = "ix_žmonių_pavardė";
Šį kartą pridėjome instrukcijas SU ir variantas užpildymo faktorius mūsų indekso kūrimo operacijai KURTI RODYKLĄ ir nurodė reikšmę 80. Operatorius PASIRINKTI dabar grąžina atitinkamą reikšmę.
Iki šiol viskas buvo gana paprasta. Viso šio proceso metu tikrai galite susideginti, kai sukuriate indeksą, kuris naudoja numatytąją koeficiento reikšmę, darant prielaidą, kad tą reikšmę žinote. Pavyzdžiui, kažkas tvarko serverio nustatymus ir yra toks užsispyręs, kad nustato indekso užpildymo koeficientą į 20. Tuo tarpu jūs ir toliau kuriate indeksus, darydami prielaidą, kad numatytoji reikšmė yra 0. Deja, jūs neturite galimybės sužinoti užpildymo. veiksnys tol, kol nesukursite indekso ir patikrinkite vertę, kaip tai darėme savo pavyzdžiuose. Priešingu atveju turėsite palaukti momento, kai užklausos našumas taip sumažės, kad pradėsite kažką įtarti.
Kita problema, kurią turėtumėte žinoti, yra indeksų atkūrimas. Kaip ir kurdami indeksą, jį kurdami iš naujo galite nurodyti indekso užpildymo faktoriaus reikšmę. Tačiau, skirtingai nei komanda sukurti indeksą, rebuild nenaudoja numatytųjų serverio nustatymų, nepaisant to, kaip tai gali atrodyti. Dar daugiau, jei konkrečiai nenurodote indekso užpildymo koeficiento vertės, tada SQL serveris naudos koeficiento vertę, su kuria šis indeksas egzistavo iki jo restruktūrizavimo. Pavyzdžiui, ši operacija ALTER INDEX atkuria ką tik sukurtą indeksą:
ALTER INDEX ix_žmonių_pavardė ON Asmuo.Asmuo REBUILD; EITI PASIRINKTI užpildymo_faktorius FROM sys.indexes WHERE objekto_id = objekto_id("Asmuo.Asmuo") AND name = "ix_žmonių_pavardė";
Kai patikrinsime darbo ciklo vertę, gausime reikšmę, lygią 80, nes būtent tai nurodėme kada paskutinis kūrinys indeksas. Numatytoji reikšmė nepaisoma.
Kaip matote, pakeisti indekso užpildymo koeficiento reikšmę nėra taip sunku. Daug sunkiau žinoti esamą vertę ir suprasti, kada ji taikoma. Jei kurdami ir perkurdami indeksus visada konkrečiai nurodote koeficientą, visada žinote konkretų rezultatą. Nebent turite nerimauti dėl to, kad kažkas dar kartą nesugadintų serverio nustatymų, todėl visi indeksai bus atkurti naudojant juokingai mažą indekso užpildymo koeficientą.
Ar galima sukurti sugrupuotą indeksą stulpelyje, kuriame yra dublikatų?
Taip ir ne. Taip, galite sukurti sugrupuotą indeksą rakto stulpelyje, kuriame yra pasikartojančių reikšmių. Ne, rakto stulpelio reikšmė negali likti neunikalios būsenos. Leisk man paaiškinti. Jei stulpelyje sukuriate nepakartojamą sugrupuotą indeksą, saugojimo modulis prie pasikartojančios reikšmės prideda vienareikšmį, kad užtikrintų unikalumą ir galėtų identifikuoti kiekvieną sugrupuotos lentelės eilutę.Pavyzdžiui, galite nuspręsti sukurti sugrupuotą indeksą stulpelyje, kuriame yra klientų duomenų Pavardė pasilikdamas pavardę. Stulpelyje yra reikšmės Franklinas, Hancockas, Vašingtonas ir Smithas. Tada vėl įterpiate reikšmes Adams, Hancock, Smith ir Smith. Tačiau rakto stulpelio vertė turi būti unikali, todėl saugojimo variklis pakeis dublikatų vertę, kad jie atrodytų maždaug taip: Adams, Franklin, Hancock, Hancock1234, Washington, Smith, Smith4567 ir Smith5678.
Iš pirmo žvilgsnio šis metodas atrodo geras, tačiau sveikojo skaičiaus reikšmė padidina rakto dydį, o tai gali tapti problema, jei yra daug dublikatų, o šios reikšmės taps negrupuoto indekso arba svetimo indekso pagrindu. pagrindinė nuoroda. Dėl šių priežasčių visada turėtumėte stengtis sukurti unikalius sugrupuotus indeksus, kai tik įmanoma. Jei tai neįmanoma, bent jau pabandykite naudoti stulpelius su labai didelės unikalios vertės turiniu.
Kaip saugoma lentelė, jei nebuvo sukurtas sugrupuotas indeksas?
SQL serveris palaiko dviejų tipų lenteles: sugrupuotas lenteles, kuriose yra sugrupuotas indeksas, ir krūvos lenteles arba tik krūvas. Skirtingai nuo sugrupuotų lentelių, krūvos duomenys jokiu būdu nėra rūšiuojami. Iš esmės tai yra duomenų krūva (krūva). Jei prie tokios lentelės pridėsite eilutę, saugojimo variklis tiesiog pridės ją prie puslapio pabaigos. Kai puslapis bus užpildytas duomenimis, jis bus įtrauktas į naują puslapį. Daugeliu atvejų norėsite lentelėje sukurti sugrupuotą indeksą, kad galėtumėte pasinaudoti rūšiavimo galimybėmis ir greitesnėmis užklausomis (pabandykite įsivaizduoti, kaip rasti telefono numeris V adresų knyga, nerūšiuojama pagal jokį principą). Tačiau, jei nuspręsite nekurti sugrupuoto indekso, vis tiek galite sukurti negrupuotą indeksą krūvoje. Tokiu atveju kiekvienoje indekso eilutėje bus žymeklis į krūvos eilutę. Rodyklė apima failo ID, puslapio numerį ir duomenų eilutės numerį.Koks ryšys tarp vertės unikalumo apribojimų ir pirminio rakto su lentelės indeksais?
Pirminis raktas ir unikalus apribojimas užtikrina, kad stulpelio reikšmės būtų unikalios. Galite sukurti tik vieną pirminį lentelės raktą ir jame negali būti reikšmių NULL. Galite sukurti kelis lentelės vertės unikalumo apribojimus ir kiekvienas iš jų gali turėti vieną įrašą su NULL.Kai kuriate pirminį raktą, saugojimo modulis taip pat sukuria unikalų sugrupuotą indeksą, jei sugrupuotas indeksas dar nebuvo sukurtas. Tačiau galite nepaisyti numatytosios elgsenos ir bus sukurtas nesugrupuotas indeksas. Jei kuriant pirminį raktą yra sugrupuotas indeksas, bus sukurtas unikalus negrupuotas indeksas.
Kai sukuriate unikalų apribojimą, saugojimo variklis sukuria unikalų, negrupuotą indeksą. Tačiau galite nurodyti sukurti unikalų sugrupuotą indeksą, jei jis nebuvo sukurtas anksčiau.
Apskritai unikalus vertės apribojimas ir unikalus indeksas yra tas pats dalykas.
Kodėl sugrupuoti ir nesugrupuoti indeksai SQL serveryje vadinami B-medžiu?
Pagrindiniai SQL serverio indeksai, sugrupuoti arba negrupuoti, yra paskirstomi puslapių rinkiniuose, vadinamuose indekso mazgais. Šie puslapiai yra suskirstyti į tam tikrą hierarchiją su medžio struktūra, vadinama subalansuotu medžiu. Viršutiniame lygyje yra šaknies mazgas, apačioje yra lapų mazgai su tarpiniais mazgais tarp viršutinio ir apatinio lygio, kaip parodyta paveikslėlyje:Šakninis mazgas yra pagrindinis įvesties taškas užklausoms, bandančioms gauti duomenis per indeksą. Pradedant nuo šio mazgo, užklausos variklis inicijuoja naršymą žemyn hierarchine struktūra iki atitinkamo lapo mazgo, kuriame yra duomenys.
Pavyzdžiui, įsivaizduokite, kad gauta užklausa pasirinkti eilutes, kurių rakto reikšmė yra 82. Užklausos posistemis pradeda veikti nuo šakninio mazgo, kuris nurodo tinkamą tarpinį mazgą, mūsų atveju 1-100. Iš tarpinio mazgo 1-100 pereinama į mazgą 51-100, o iš jo į galutinį mazgą 76-100. Jei tai yra sugrupuotas indeksas, tada mazgo lape yra su raktu susietos eilutės duomenys, lygūs 82. Jei tai nesugrupuotas indeksas, tada indekso lape yra rodyklė į sugrupuotą lentelę arba konkrečią eilutę krūva.
Kaip indeksas netgi gali pagerinti užklausos našumą, jei turite pereiti visus šiuos indekso mazgus?
Pirma, indeksai ne visada pagerina našumą. Per daug neteisingai sukurtų indeksų paverčia sistemą liūnu ir pablogina užklausos našumą. Tiksliau sakyti, kad jei indeksai taikomi atsargiai, jie gali žymiai padidinti našumą.Pagalvokite apie didžiulę knygą, skirtą spektaklio derinimui SQL serveris(popierinė versija, o ne elektroninė versija). Įsivaizduokite, kad norite rasti informacijos apie išteklių valdytojo konfigūravimą. Galite vilkti pirštu per visą knygą puslapį po puslapio arba atidaryti turinį ir sužinoti tikslų puslapio numerį su ieškoma informacija (jei knyga teisingai indeksuota ir turinys turi teisingas rodykles). Taip tikrai sutaupysite daug laiko, net jei pirmiausia turite pasiekti visiškai kitokią struktūrą (indeksą), kad gautumėte reikiamą informaciją iš pirminės struktūros (knygos).
Kaip knygų rodyklė, rodyklė į SQL serveris leidžia vykdyti tikslias reikiamų duomenų užklausas, o ne visiškai nuskaityti visus lentelėje esančius duomenis. Mažose lentelėse pilnas nuskaitymas paprastai nėra problema, tačiau didelės lentelės užima daug duomenų puslapių, todėl užklausos vykdymas gali užtrukti daug laiko, nebent yra indeksas, leidžiantis užklausos varikliui iš karto gauti teisingą duomenų vietą. Įsivaizduokite, kad pasiklysite kelių lygių kelių sankryžoje priešais didelį didmiestį be žemėlapio ir suprasite.
Jei indeksai tokie puikūs, kodėl gi nesukūrus po vieną kiekviename stulpelyje?
Joks geras poelgis neturi likti nenubaustas. Bent jau taip yra su indeksais. Žinoma, indeksai veikia puikiai, kol vykdote operatoriaus gavimo užklausas PASIRINKTI, bet kai tik prasideda dažni skambučiai operatoriams ĮDĖTI, ATNAUJINTI Ir IŠTRINTI, todėl kraštovaizdis keičiasi labai greitai.Kai inicijuojate operatoriaus duomenų užklausą PASIRINKTI, užklausos variklis suranda indeksą, pereina per jo medžio struktūrą ir atranda ieškomus duomenis. Kas gali būti paprasčiau? Tačiau viskas pasikeičia, jei inicijuojate pakeitimo pareiškimą, pvz ATNAUJINTI. Taip, pirmoje teiginio dalyje užklausos variklis vėl gali naudoti indeksą, kad surastų keičiamą eilutę – tai gera žinia. Ir jei eilutėje yra paprastas duomenų pakeitimas, kuris neturi įtakos pagrindinių stulpelių pokyčiams, tada keitimo procesas bus visiškai neskausmingas. Bet ką daryti, jei dėl pakeitimo puslapiai, kuriuose yra duomenys, bus suskaidyti arba pakeičiama rakto stulpelio reikšmė, dėl kurios jis bus perkeltas į kitą indekso mazgą – dėl to indeksą galbūt reikės pertvarkyti, turintį įtakos visiems susijusiems indeksams ir operacijoms , todėl smarkiai sumažėjo produktyvumas.
Panašūs procesai vyksta skambinant operatoriui IŠTRINTI. Indeksas gali padėti rasti ištrinamus duomenis, tačiau ištrynus pačius duomenis puslapis gali būti pertvarkytas. Kalbant apie operatorių ĮDĖTI, pagrindinis visų indeksų priešas: pradedi pridėti didelį kiekį duomenų, dėl ko keičiasi indeksai ir jų pertvarkymas ir kenčia visi.
Taigi, galvodami apie tai, kokio tipo indeksus ir kiek jų sukurti, apsvarstykite duomenų bazės užklausų tipus. Daugiau nereiškia geriau. Prieš įtraukdami į lentelę naują indeksą, apskaičiuokite ne tik kainą pagrindinės užklausos, bet ir užimtas tūris disko talpa, sveikatos palaikymo išlaidas ir indeksus, o tai gali sukelti domino efektą atliekant kitas operacijas. Indekso kūrimo strategija yra vienas iš svarbiausių diegimo aspektų, į kurį turėtų būti atsižvelgta daug dalykų, pradedant nuo indekso dydžio, unikalių reikšmių skaičiaus ir baigiant užklausų, kurias palaikys indeksas, tipas.
Ar būtina sukurti sugrupuotą indeksą stulpelyje su pirminiu raktu?
Galite sukurti sugrupuotą indeksą bet kuriame atitinkančiame stulpelyje būtinas sąlygas. Tiesa, kad sugrupuotas indeksas ir pirminio rakto apribojimas yra sukurti vienas kitam ir atitinka dangų, todėl supraskite, kad kai sukuriate pirminį raktą, tada automatiškai bus sukurtas sugrupuotas indeksas, jei jo nebuvo. sukurta anksčiau. Tačiau galite nuspręsti, kad sugrupuotas indeksas būtų geresnis kitur, ir dažnai jūsų sprendimas bus pagrįstas.Pagrindinis sugrupuoto indekso tikslas yra rūšiuoti visas lentelės eilutes pagal rakto stulpelį, nurodytą apibrėžiant indeksą. Tai numato Greita paieška ir lengva prieiga prie lentelės duomenų.
Lentelės pirminis raktas gali būti geras pasirinkimas, nes jis unikaliai identifikuoja kiekvieną lentelės eilutę nepridedant papildomų duomenų. Kai kuriais atvejais Geriausias pasirinkimas Bus pakaitinis pirminis raktas, kuris yra ne tik unikalus, bet ir mažas, o jo reikšmės didėja nuosekliai, todėl šia verte pagrįsti nesugrupuoti indeksai tampa efektyvesni. Užklausos optimizavimo priemonė taip pat mėgsta šį sugrupuoto indekso ir pirminio rakto derinį, nes lentelių sujungimas yra greitesnis nei sujungimas kitu būdu, nenaudojant pirminio rakto ir su juo susijusio grupinio indekso. Kaip sakiau, tai degtukas, sukurtas danguje.
Tačiau galiausiai verta atkreipti dėmesį į tai, kad kuriant klasterinį indeksą reikia atsižvelgti į kelis aspektus: kiek ne grupuotų indeksų bus remiantis juo, kaip dažnai keisis pagrindinio indekso stulpelio reikšmė ir kokio dydžio. Kai pasikeičia reikšmės sugrupuoto indekso stulpeliuose arba indeksas neveikia taip, kaip tikėtasi, gali būti paveikti visi kiti lentelės indeksai. Sugrupuotas indeksas turėtų būti pagrįstas patvariausiu stulpeliu, kurio reikšmės didėja tam tikra tvarka, bet nesikeičia atsitiktinai. Indeksas turi palaikyti užklausas, susijusias su dažniausiai pasiekiamais lentelės duomenimis, todėl užklausos išnaudoja visas galimybes, kad duomenys yra rūšiuojami ir pasiekiami šakniniuose mazguose, indekso lapuose. Jei pirminis raktas atitinka šį scenarijų, naudokite jį. Jei ne, pasirinkite kitą stulpelių rinkinį.
Ką daryti, jei indeksuojate rodinį, ar jis vis tiek yra rodinys?
Rodinys yra virtuali lentelė, kuri generuoja duomenis iš vienos ar kelių lentelių. Iš esmės tai yra pavadinta užklausa, kuri nuskaito duomenis iš pagrindinių lentelių, kai pateikiate užklausą dėl to rodinio. Galite pagerinti užklausos našumą šiame rodinyje kurdami sugrupuotą indeksą ir negrupuotus indeksus, panašiai kaip kurdami indeksus lentelėje, tačiau pagrindinis įspėjimas yra tas, kad pirmiausia sukuriate sugrupuotą indeksą, o tada galite sukurti negrupuotą indeksą.Kai sukuriamas indeksuotas rodinys (materializuotas vaizdas), pats rodinio apibrėžimas lieka atskira esybe. Galų gale, tai tik užkoduotas operatorius PASIRINKTI, saugomi duomenų bazėje. Tačiau indeksas yra visiškai kita istorija. Kai kuriate sugrupuotą arba negrupuotą indeksą tiekėjui, duomenys fiziškai išsaugomi diske, kaip ir įprastas indeksas. Be to, pasikeitus duomenims pagrindinėse lentelėse, rodinio indeksas automatiškai pasikeičia (tai reiškia, kad galbūt norėsite neindeksuoti dažnai besikeičiančių lentelių rodinių). Bet kuriuo atveju vaizdas lieka vaizdu – žvilgsnis į lenteles, bet tiksliai atliktas Šis momentas, su jį atitinkančiais indeksais.
Kad galėtumėte sukurti rodinio rodyklę, jis turi atitikti kelis apribojimus. Pavyzdžiui, rodinys gali nurodyti tik bazines lenteles, bet ne kitus rodinius, ir tos lentelės turi būti toje pačioje duomenų bazėje. Iš tikrųjų yra daug kitų apribojimų, todėl būtinai patikrinkite dokumentaciją SQL serveris už visas nešvarias smulkmenas.
Kodėl verta naudoti apimantį indeksą, o ne sudėtinį indeksą?
Pirmiausia įsitikinkime, kad suprantame skirtumą tarp šių dviejų. Sudėtinis indeksas yra tiesiog įprastas indeksas, kuriame yra daugiau nei vienas stulpelis. Keli raktų stulpeliai gali būti naudojami siekiant užtikrinti, kad kiekviena lentelės eilutė būtų unikali, arba galite turėti kelis stulpelius, kad įsitikintumėte, jog pirminis raktas yra unikalus, arba galite bandyti optimizuoti dažnai iškviečiamų užklausų vykdymą keliuose stulpeliuose. Tačiau apskritai kuo daugiau pagrindinių stulpelių yra indekse, tuo indeksas bus mažiau efektyvus, o tai reiškia, kad sudėtiniai indeksai turėtų būti naudojami protingai.Kaip minėta, užklausa gali būti labai naudinga, jei visi reikalingi duomenys iš karto yra indekso lapuose, kaip ir pats indeksas. Sugrupuotam indeksui tai nėra problema, nes visi duomenys jau yra (todėl taip svarbu gerai pagalvoti, kai kuriate grupinį indeksą). Tačiau nesugrupuotame lapų indekse yra tik pagrindiniai stulpeliai. Norint pasiekti visus kitus duomenis, užklausų optimizavimo priemonėje reikia atlikti papildomus veiksmus, kurie gali labai apsunkinti jūsų užklausų vykdymą.
Čia į pagalbą ateina padengimo indeksas. Kai apibrėžiate negrupuotą indeksą, prie pagrindinių stulpelių galite nurodyti papildomus stulpelius. Pavyzdžiui, tarkime, kad jūsų programa dažnai užklausa stulpelio duomenų Užsakymo ID Ir Užsakymo data lentelėje Pardavimai:
SELECT OrderID, OrderDate FROM Sales WHERE OrderID = 12345;
Galite sukurti sudėtinį nesugrupuotą indeksą abiejuose stulpeliuose, tačiau stulpelis Užsakymo data tik pridės indekso priežiūros išlaidas, nenaudodamas ypač naudingo rakto stulpelio. Geriausias sprendimas būtų sukurti apimantį indeksą rakto stulpelyje Užsakymo ID ir papildomai įtrauktas stulpelis Užsakymo data:
KURTI NEKLUSTERĮ RODYKLĄ ix_orderid DBO.Pardavimai(Užsakymo ID) ĮTRAUKTI (Užsakymo data);
Taip išvengiama perteklinių stulpelių indeksavimo trūkumų ir išsaugoma duomenų saugojimo lapuose pranašumai vykdant užklausas. Įtrauktas stulpelis nėra rakto dalis, tačiau duomenys saugomi lapo mazge, indekso lape. Tai gali pagerinti užklausos vykdymo našumą be jokio poveikio. papildomų išlaidų. Be to, stulpeliams, įtrauktiems į apimantį indeksą, taikomi mažiau apribojimų nei pagrindiniams indekso stulpeliams.
Ar svarbus dublikatų skaičius rakto stulpelyje?
Kai kuriate indeksą, turite pabandyti sumažinti pasikartojančių raktų stulpeliuose skaičių. Arba tiksliau: stenkitės, kad pasikartojimų dažnis būtų kuo mažesnis.Jei dirbate su sudėtiniu indeksu, dubliavimas taikomas visiems pagrindinių stulpelių visumai. Viename stulpelyje gali būti daug pasikartojančių reikšmių, tačiau visuose indekso stulpeliuose turi būti kuo mažiau pasikartojimų. Pavyzdžiui, stulpeliuose sukuriate sudėtinį negrupuotą indeksą Pirmas vardas Ir Pavardė, galite turėti daug John Doe verčių ir daug Doe verčių, bet norite turėti kuo mažiau John Doe verčių arba, pageidautina, tik vieną John Doe vertę.
Pagrindinio stulpelio verčių unikalumo santykis vadinamas indekso selektyvumu. Kuo daugiau unikalių verčių, tuo didesnis selektyvumas: unikalus indeksas turi didžiausią įmanomą selektyvumą. Užklausų varikliui labai patinka stulpeliai su didelėmis selektyvumo reikšmėmis, ypač jei tie stulpeliai yra įtraukti į dažniausiai atliekamų užklausų WHERE sąlygas. Kuo labiau selektyvus indeksas, tuo greičiau užklausos variklis gali sumažinti gauto duomenų rinkinio dydį. Žinoma, minusas yra tas, kad stulpeliai su palyginti mažai unikalių verčių retai bus tinkami indeksavimo kandidatai.
Ar galima sukurti nesugrupuotą indeksą tik konkrečiame pagrindinio stulpelio duomenų poaibyje?
Pagal numatytuosius nustatymus negrupuotame indekse yra po vieną eilutę kiekvienai lentelės eilutei. Žinoma, tą patį galite pasakyti apie sugrupuotą indeksą, darant prielaidą, kad toks indeksas yra lentelė. Tačiau kalbant apie nesugrupuotą indeksą, ryšys vienas su vienu yra svarbi sąvoka, nes pradedant versija SQL Server 2008, turite galimybę sukurti filtruojamą indeksą, apribojantį į jį įtrauktas eilutes. Filtruotas indeksas gali pagerinti užklausos našumą, nes... ji yra mažesnė ir joje yra filtruota, tikslesnė statistika nei visose lentelėse - tai leidžia sukurti patobulintus vykdymo planus. Filtruotas indeksas taip pat reikalauja mažiau vietos saugykloje ir mažesnės priežiūros išlaidos. Indeksas atnaujinamas tik pasikeitus filtrą atitinkantiems duomenims.Be to, nesunku sukurti filtruojamą indeksą. Operatoriuje KURTI RODYKLĄ tereikia nurodyti KUR filtro būklė. Pavyzdžiui, galite iš indekso išfiltruoti visas eilutes, kuriose yra NULL, kaip parodyta kode:
KURTI NEKLUSTERIĄ INDEKSĄ ix_stebėjimo numerį ON Sales.SalesOrderDetail(CarrierTrackingNumber) WHERE CarrierTrackingNumber YRA NULL;
Tiesą sakant, galime išfiltruoti visus duomenis, kurie nėra svarbūs atliekant svarbias užklausas. Bet būkite atsargūs, nes... SQL serveris nustato keletą apribojimų filtruojamiems indeksams, pvz., nesugebėjimas sukurti rodinio filtruojamo indekso, todėl atidžiai perskaitykite dokumentaciją.
Taip pat gali būti, kad panašių rezultatų galite pasiekti sukūrę indeksuotą rodinį. Tačiau filtruojamas indeksas turi keletą privalumų, pavyzdžiui, galimybę sumažinti priežiūros išlaidas ir pagerinti vykdymo planų kokybę. Filtruotus indeksus taip pat galima atkurti internete. Išbandykite tai naudodami indeksuotą rodinį.
Ir vėl šiek tiek iš vertėjo
Šio vertimo pasirodymo Habrahabr puslapiuose tikslas buvo papasakoti arba priminti apie SimpleTalk tinklaraštį iš RedGate.
Jame publikuojama daug linksmų ir įdomių įrašų.
Nesu susijęs su jokiais įmonės produktais RedGate, nei su jų pardavimu.
Kaip ir žadėjau, knygos tiems, kurie nori sužinoti daugiau
Labai rekomenduoju tris geros knygos(nuorodos į uždegti versijos parduotuvėje Amazon):
 |
„Microsoft SQL Server 2012 T-SQL Fundamentals“ (kūrėjo nuoroda) Autorius Itzik Ben-Gan Paskelbimo data: 2012 m. liepos 15 d Autorius, savo amato meistras, suteikia pagrindines žinias apie darbą su duomenų bazėmis. Jei viską pamiršote arba niekada nežinojote, tai tikrai verta perskaityti. | Iš esmės galite atidaryti paprastus indeksus Pridėti žymas
Jei lentelėje yra daug įrašų, rasti tinkamą įrašą gali būti labai sunku. Duomenų paieška atliekama brute-force metodu, tai yra, visi lentelės įrašai yra peržiūrimi nuo pirmojo įrašo iki paskutinio įrašo, o tai užima daug laiko. Kad būtų lengviau rasti duomenis lentelėje, naudojami indeksai. Indeksas, kartais vadinamas rodykle, yra lentelės įrašo eilės numeris. Indeksas sudaromas remiantis vieno lauko reikšmėmis arba kelių laukų reikšmėmis. Indeksas, sukurtas naudojant vieno lauko reikšmes, vadinamas paprastu, o indeksas, pagrįstas dviejų ar daugiau laukų reikšmėmis, vadinamas sudėtingu. Kuriant indeksą, įrašai lentelėje rūšiuojami pagal būsimo indekso lauko (ar laukų) reikšmes. Tada pirmai lentelės eilutei priskiriamas indekso numeris vienas, antrajai eilutei priskiriamas indekso numeris du ir taip iki lentelės pabaigos.
Tiek paprasti, tiek sudėtingi indeksai turi savo tipą (Ture). Pirminis (pirminis) indeksas (raktas) yra laukas arba laukų grupė, kuri vienareikšmiškai identifikuoja įrašą, tai yra, pirminio indekso reikšmės yra unikalios (nepasikartojančios). Reliacinėje duomenų bazėje kiekviena lentelė gali turėti tik vieną pirminį raktą. Užsienio raktai lentelėje gali būti daug ir jie turės vieną iš šių tipų:
Kandidatas – kandidatas į pirminį arba alternatyvųjį raktą. Jis turi visas pirminio rakto savybes.
Unikalus – leidžia pasikartojančias vertes lauke, ant kurio jis sukurtas, tačiau bus rodomas tik pirmasis įrašų grupės įrašas su ta pačia indekso lauko verte.
Reguliarus – nenustato jokių apribojimų indekso lauko reikšmėms ir įrašų atvaizdavimui ekrane. Indeksas valdo tik įrašų rodymo tvarką. Tai yra populiariausias indekso tipas.
Ryšys tarp lentelių vykdomas per indeksus, kurie vadinami raktais.
Sukurtas indeksas saugomas specialiame indekso faile. Jei indekso faile saugomas tik vienas indeksas, tada jis vadinamas vienu indeksu ir turi plėtinį .idx. Rodyklės failai, kuriuose saugoma daug indeksų, vadinami kelių indeksų failais ir turi .cdx plėtinį. Kiekvienas indeksas, saugomas kelių indeksų faile, vadinamas žyma. Kiekviena žyma turi savo unikalų pavadinimą.
Yra dviejų tipų kelių indeksų failai: tiesiog kelių indeksų failai (aprašyti aukščiau) ir struktūriniai kelių indeksų failai. Struktūrinis kelių indeksų failas turi tokį patį pavadinimą kaip ir lentelės, kuriai jis priklauso (skirtumas yra tik failo plėtinys), ir turi šias savybes:
Automatiškai atsidaro su savo stalu;
Jo negalima uždaryti, bet galima padaryti ne pagrindiniu.
Vienoje lentelėje gali būti daug indeksų failų, tiek vieno indekso, tiek kelių indeksų. Senesnėse FoxPro versijose naudojami kelių indeksų failai.
Indekso kūrimas
Yra du būdai sukurti indeksą.
A. Naudojant komandą:
RODYKLĖ ĮJUNGTA<индексное выражение>TAI< idx-failas> | TAG<имя тега>
Pasirinkimų paskirtis:
<indekso išraiška>- lauko (arba laukų), kurių reikšmės turėtų būti sudarytas, pavadinimas. Kuriant sudėtingą indeksą, laukų pavadinimai pateikiami atskirti + (pliuso) ženklu. Jei sudėtingą indeksą sudaro:
Skaitiniams laukams indeksas sudaromas remiantis lauko reikšmių suma;
Simbolių laukams indeksas pirmiausia sukuriamas pagal pirmojo lauko reikšmę, o pasikartojančių pirmojo lauko verčių atveju - pagal antrojo lauko reikšmes; jei kartojasi pirmojo ir antrojo laukų reikšmės - pagal trečiojo lauko reikšmes ir pan.;
Pagal laukus skirtingi tipai, tada pirmiausia lauko reikšmės sumažinamos iki vieno tipo, dažniausiai simbolio, o tada sukuriamas indeksas.
Indekso išraiškos ilgis neturi viršyti 254 simbolių.
TAI< idx-failas>- nurodomas vieno indekso failo pavadinimas.
TAG<имя тега> - nurodo žymos pavadinimą kelių indeksų faile. Jei pasirenkama parinktis, tada sukurta žyma dedama į nurodytą kelių indeksų failą, o jei trūksta reikiamo kelių indeksų failo, bus kuriamas struktūrinis kelių indeksų failas. Jei parinktis praleista, sukurta žyma bus įdėta į dabartinį kelių indeksų failą.
DĖL<условие> - nustato tų lentelės įrašų, kuriuos tenkina, indekso pasirinkimo režimą<условию>.
KOMPAKTIŠKA- kontroliuoja kompaktiško vieno indekso failo kūrimą. Senesnėse FoxPro versijose ji nenaudojama.
NEPALEIDANTIS- sukuria indeksą mažėjimo tvarka. Pagal numatytuosius nustatymus indeksas kuriamas didėjančia tvarka (AUGĖJIMAS). Vieno indekso failams galite sukurti indeksą tik didėjančia tvarka. Jei komandą SET COLLATE išduodate prieš naudodami komandą INDEX ON..., galite sukurti vieno indekso failą mažėjančia tvarka.
UNIKALUS- sukuria unikalų indeksą. Jei indekso lauke (-iuose) yra pasikartojančių reikšmių, į indeksą bus įtrauktas tik pirmasis įrašas, o likę įrašai nebus pasiekiami.
PRIEDAS- naujai sukurtas indekso failas neuždaro tuo metu jau atidarytų indekso failų. Jei parinktis praleista, naujai sukurtas indekso failas uždaro visus anksčiau atidarytus indekso failus.
b. Pagrindinio meniu naudojimas:
Tokiu atveju indeksas sukuriamas sukūrus lentelę arba keičiant lentelės struktūrą. Norėdami tai padaryti, dialogo skydelyje Table Designer pasirinkite skirtuką Indeksas (3.1 pav.).
Kiekviena rodyklė aprašoma viena eilute dialogo lange Table Designer.
Stulpelyje Pavadinimas nurodo kelių indeksų failo žymos pavadinimą. Jei vienas iš kelių indeksų failų buvo atidarytas anksčiau, naujai sukurtas indeksas įdedamas į atvirą kelių indeksų failą. Jei indeksas sukuriamas kartu su lentelės failo kūrimu arba lentelės faile nėra kelių indeksų failų, tada naujai sukurtas indeksas dedamas į automatiškai sukurtą struktūrinį kelių indeksų failą.

Stulpelis „Ture“, kuriame yra išskleidžiamasis sąrašas, rodo vieną iš galiojančių indeksų tipų. Jei indeksas sukurtas lentelėje, kuri yra duomenų bazės dalis, yra keturios galimos reikšmės: Pirminė, Kandidatas, Unikali ir Įprasta. Jei indeksas sukurtas nemokamai lentelei, tada pirminės reikšmės išskleidžiamajame sąraše nėra.
Stulpelyje Išraiška pateikiami laukų, kurių reikšmes reikia naudoti kuriant indeksą, pavadinimai. Jei kuriamas sudėtingas indeksas, patogiau naudoti išraiškų kūrimo priemonę, kuri paleidžiama spustelėjus įvesties lauko dešinėje esantį mygtuką.
Stulpelyje Filtras galite nustatyti loginę sąlygą ir sudaryti indeksą ne visiems lentelės įrašams, o tik įrašams, kurie atitinka filtro sąlygą. Šiame grafike taip pat yra išraiškų kūrimo priemonė. Abiejų statybininkų turinys ir išvaizda yra vienodi (3.2 pav.).
Fig. 3.2 paveiksle parodytas sudėtingo indekso sudarymas naudojant du simbolių laukus ush_step ir uch_zvan (žymos pavadinimas uch buvo priskirtas prieš iškviečiant išraiškų kūrimo priemonę ekrane). „+“ ženklas, nurodantis sudėtingo indekso sudarymą, paimtas iš išskleidžiamojo sąrašo Eilutė.
Galioja išskleidžiamieji eilutės sąrašai stygų funkcijos. Taip pat Matematikos, loginės ir datos išskleidžiamajame sąraše pateikiamos galiojančios matematikos, loginės ir datos funkcijos. Norima funkcija iš šių išskleidžiamųjų sąrašų pasirenkama spustelėjus kairįjį pelės mygtuką. Laukų pavadinimai (Fields list) ir kintamųjų pavadinimai (Variables list) pasirenkami naudojant dukart spustelėkite kairysis pelės mygtukas. Gauta išraiška patalpinta išraiškos lange.
Išskleidžiamajame sąraše Iš lentelės nurodomas lentelės, iš kurios paimti laukai indeksui kurti, pavadinimas. Jei norite, galite užsisakyti bet kurią lentelę iš dabartinės duomenų bazės ir naudoti bet kurį lauką, kad sukurtumėte indeksą.
Šioje medžiagoje bus aptariami tokie duomenų bazės objektai Microsoft SQL serveris Kaip indeksai Sužinosite, kas yra indeksai, kokių tipų indeksai yra, kaip juos kurti, optimizuoti ir ištrinti.
Kas yra duomenų bazės indeksai?
Indeksas yra duomenų bazės objektas, kuris yra duomenų struktūra, susidedanti iš raktų, sudarytų iš vieno ar daugiau lentelės arba rodinio stulpelių, ir rodyklių, nukreipiančių į nurodytų duomenų saugojimo vietą. Indeksai skirti greičiau gauti eilutes iš lentelės; kitaip tariant, rodyklės leidžia greitai ieškoti duomenų lentelėje, o tai labai pagerina užklausų ir programų našumą. Indeksai taip pat gali būti naudojami siekiant užtikrinti, kad lentelės eilutės būtų unikalios, taip užtikrinant duomenų vientisumą.
„Microsoft SQL Server“ indeksų tipai
„Microsoft SQL Server“ yra šių tipų indeksai:
- Sugrupuoti (Sugrupuoti) yra indeksas, kuriame saugomi lentelės duomenys, surūšiuoti pagal indekso rakto reikšmę. Lentelėje gali būti tik vienas sugrupuotas indeksas, nes duomenis galima rūšiuoti tik viena tvarka. Jei įmanoma, kiekviena lentelė turi turėti sugrupuotą indeksą; jei lentelė neturi sugrupuoto indekso, lentelė vadinama " krūvoje“ Sugrupuotas indeksas sukuriamas automatiškai, kai sukuriate PRIMARY KEY apribojimus ( pirminis raktas) ir UNIKALUS, jei lentelės sugrupuotas indeksas dar neapibrėžtas. Jei sukuriate sugrupuotą indeksą lentelėje ( krūvos), kuriame yra nesugrupuotų indeksų, sukūrus juos visus reikia atkurti.
- Nesusikaupę į grupes (Nesusikaupę) yra indeksas, kuriame yra rakto reikšmė ir rodyklė į duomenų eilutę, kurioje yra to rakto reikšmė. Lentelėje gali būti keli negrupuoti indeksai. Nesugrupuotus indeksus galima sukurti lentelėse su grupuotu indeksu arba be jo. Būtent tokio tipo indeksai yra naudojami siekiant pagerinti dažnai naudojamų užklausų našumą, nes nesugrupuoti indeksai suteikia greitą paiešką ir prieigą prie duomenų pagal pagrindines reikšmes;
- Filtruojamas (Filtruota) yra optimizuotas negrupuotas indeksas, kuris naudoja filtro predikatą lentelės eilučių poaibiui indeksuoti. Gerai suprojektuotas tokio tipo indeksas gali pagerinti užklausos našumą ir sumažinti indekso priežiūros bei saugojimo išlaidas, palyginti su visos lentelės indeksais;
- Unikalus (Unikalus) yra indeksas, užtikrinantis, kad nėra dublikatų ( identiškas) indekso raktų reikšmes, taip garantuojant eilučių unikalumą pagal šį raktą. Tiek sugrupuoti, tiek nesugrupuoti indeksai gali būti unikalūs. Jei sukuriate unikalų indeksą keliuose stulpeliuose, indeksas užtikrina, kad kiekvienas rakto reikšmių derinys būtų unikalus. Kai kuriate PRIMARY KEY arba UNIQUE apribojimus, SQL serveris automatiškai sukuria unikalų indeksą raktų stulpeliuose. Unikalus indeksas gali būti sukurtas tik tuo atveju, jei lentelės raktiniuose stulpeliuose šiuo metu nėra pasikartojančių reikšmių;
- Stulpelis (Stulpelių saugykla) yra indeksas, pagrįstas stulpelių duomenų saugojimo technologija. Šis tipas Indeksas yra veiksmingas didelėms duomenų saugykloms, nes jis gali padidinti užklausų į saugyklą našumą iki 10 kartų, taip pat sumažinti duomenų dydį iki 10 kartų, nes stulpelių saugyklos indekse esantys duomenys yra suglaudinti. Yra ir sugrupuotų stulpelių indeksų, ir negrupuotų;
- Pilnas tekstas (Pilnas tekstas) yra specialus indekso tipas, teikiantis veiksmingą palaikymą sudėtingos operacijos ieškant žodžių simbolių eilutės duomenyse. Viso teksto rodyklės kūrimo ir priežiūros procesas vadinamas " užpildymas“ Yra tokie užpildymo tipai: pilnas užpildymas ir užpildymas, pagrįstas pokyčių sekimu. Pagal numatytuosius nustatymus SQL Server visiškai užpildo naują viso teksto indeksą iškart po jo sukūrimo, tačiau tam gali prireikti daug išteklių, priklausomai nuo lentelės dydžio, todėl galima atidėti visą populiaciją. Pakeitimų sekimu pagrįstas sėjimas naudojamas viso teksto indeksui palaikyti po to, kai jis iš pradžių visiškai užpildytas;
- Erdvinė (Erdvinė) yra indeksas, leidžiantis daugiau efektyvus naudojimas konkrečios operacijos su erdviniais objektais stulpeliuose su geometrijos arba geografijos duomenų tipu. Šio tipo indeksą galima sukurti tik erdviniame stulpelyje, o lentelėje, kurioje apibrėžiamas erdvinis indeksas, turi būti pirminis raktas ( PIRMINIS RAKTAS);
- XML yra kitas specialus indekso tipas, skirtas tipo stulpeliams XML duomenys. XML indeksas pagerina užklausų apdorojimo pagal XML stulpelius efektyvumą. Yra du XML indeksų tipai: pirminis ir antrinis. Pirminis XML indeksas indeksuoja visas žymas, reikšmes ir kelius, saugomus XML stulpelyje. Jį galima sukurti tik tuo atveju, jei lentelės pirminiame rakte yra sugrupuotas indeksas. Antrinis XML indeksas gali būti sukurtas tik tuo atveju, jei lentelė turi pirminį XML indeksą ir ji naudojama tam tikro tipo prieigos prie XML stulpelio užklausų našumui pagerinti, šiuo atžvilgiu yra keletas antrinių indeksų tipų: PATH , VERTĖ ir TURTAS;
- Taip pat yra specialių indeksų, skirtų atminčiai optimizuotoms lentelėms ( Atmintyje esantis OLTP) pvz.: maiša ( Maiša) pagal atmintį optimizuotus indeksus ir negrupuotus indeksus, sukurtus diapazono nuskaitymui ir užsakytam nuskaitymui.
Indeksų kūrimas ir trynimas „Microsoft SQL Server“.
Prieš pradedant kurti indeksą, būtina jį gerai suprojektuoti, kad indeksas būtų naudojamas efektyviai, nes prastai sukurti indeksai gali ne pagerinti našumą, o sumažinti. Pavyzdžiui, jei lentelėje yra daug indeksų, sumažėja INSERT, UPDATE, DELETE ir MERGE teiginių našumas, nes pasikeitus lentelės duomenims, visi indeksai turi būti atitinkamai atnaujinti. Atskirame straipsnyje apžvelgsime bendras rekomendacijas dėl indeksų kūrimo, bet dabar pereikime tiesiai prie indeksų kūrimo ir ištrynimo proceso.
Pastaba! Mano SQL serveris yra „Microsoft SQL Server 2016 Express“.
Indeksų kūrimas
Yra du būdai, kaip sukurti indeksus Microsoft SQL Server: pirmasis yra naudojant grafinę SQL Server Management Studio (SSMS) aplinkos sąsają, o antrasis - Transact-SQL kalba, mes analizuosime abu metodus.
Pavyzdžių šaltiniai
Įsivaizduokime, kad turime produktų lentelę TestTable, kurią sudaro trys stulpeliai:
- ProductId – prekės identifikatorius;
- ProductName – prekės pavadinimas;
- CategoryID – prekės kategorija.
Sugrupuoto indekso kūrimo pavyzdys
Kaip jau sakiau, klasterizuotas indeksas sukuriamas automatiškai, jei, pavyzdžiui, kurdami lentelę, kaip pirminį raktą nurodome konkretų stulpelį ( PIRMINIS RAKTAS), bet kadangi to nepadarėme, pažvelkime į klasterinio indekso kūrimo pavyzdį.
Norėdami sukurti sugrupuotą indeksą, galime nurodyti pirminį lentelės raktą ir taip sugrupuotas indeksas bus sukurtas automatiškai, arba galime sukurti sugrupuotą indeksą atskirai.
Pavyzdžiui, tiesiog sukurkime sugrupuotą indeksą, nesukurdami pirminio rakto. Pirmiausia tai padarysime naudodami valdymo studiją.
Atidarykite SSMS ir objekto naršyklėje suraskite norimą lentelę ir dešiniuoju pelės mygtuku spustelėkite elementą " Indeksai“, pasirinkite „ Sukurti indeksą" ir indekso tipas, mūsų atveju " Sugrupuoti».

Forma " Naujas indeksas “, kur turime nurodyti naujojo indekso pavadinimą ( jis turi būti unikalus lentelėje), taip pat nurodome, ar šis indeksas bus unikalus; jei kalbame apie prekės identifikatorių prekių lentelėje, tai, žinoma, jis turi būti unikalus. Tada pasirinkite stulpelį ( indekso raktas), kurio pagrindu kursime klasterinį indeksą, t.y. duomenų eilutės lentelėje bus rūšiuojamos naudojant " Papildyti».

Įvedę visus reikiamus parametrus, spustelėkite „ Gerai“, galiausiai bus sukurtas sugrupuotas indeksas.

Panašiai galima sukurti sugrupuotą indeksą naudojant T-SQL sakinį GŪRYBŲ RODYKLĖ, pavyzdžiui, šitaip
KURTI UNIKALŲ KLASTERIUOTA INDEKSĄ IX_Clustered ON TestTable (ProductId ASC) GO
Arba, kaip jau minėjome, taip pat galime naudoti teiginį, kad sukurtume, pavyzdžiui, pirminį raktą
ALTER TABLE TestTable ADD CONSTRAINT PK_TestTable PRIMARY KEY CLASTERED (ProductId ASC) GO
Negrupuoto indekso su įtrauktais stulpeliais kūrimo pavyzdys
Dabar pažiūrėkime į nesugrupuoto indekso sukūrimo pavyzdį, kuriame nurodysime stulpelius, kurie nebus pagrindiniai, bet bus įtraukti į indeksą. Tai naudinga tais atvejais, kai kuriate indeksą konkrečiai užklausai, pavyzdžiui, kad indeksas visiškai apimtų užklausą, t.y. buvo visi stulpeliai ( tai vadinama "užklausos aprėptis"). Užklausos aprėptis pagerina našumą, nes užklausos optimizavimo priemonė gali rasti visas indekso stulpelių reikšmes nepasiekdama lentelės duomenų, todėl disko I/O operacijų bus mažiau. Tačiau atminkite, kad įtraukus į indeksą nepagrindinius stulpelius, indekso dydis padidėja, t.y. Indekso saugojimui reikės daugiau vietos diske, todėl gali sumažėti INSERT, UPDATE, DELETE ir MERGE operacijų našumas pagrindinėje lentelėje.
Norėdami sukurti nesugrupuotą indeksą naudodami Management Studio GUI, taip pat randame norimą lentelę ir elementą Indeksai, tik tokiu atveju pasirenkame „ Sukurti -> Negrupuotas indeksas».

Atidarius formą " Naujas indeksas"mes nurodome indekso pavadinimą, pridedame raktinį stulpelį ar stulpelius naudodami mygtuką " Papildyti“, pavyzdžiui, mūsų bandomajam atvejui nurodykime CategoryID.

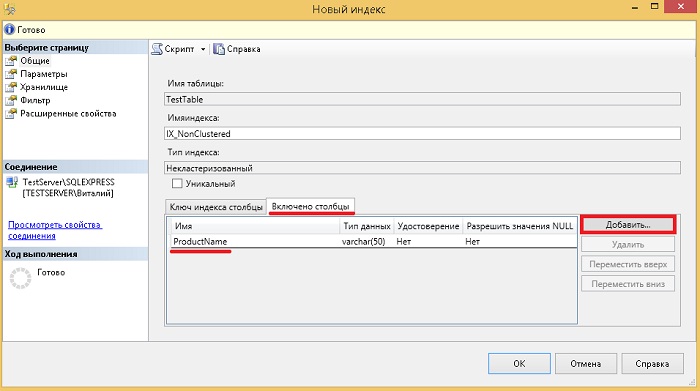
„Transact-SQL“ tai atrodytų taip.
KURTI NEKLUSTERINGĄ INDEX IX_NonClustered ON Test Table (CategoryID ASC) ĮTRAUKTI (Produkto pavadinimas) GO
„Microsoft SQL Server“ indekso ištrynimo pavyzdys
Norėdami ištrinti indeksą, dešiniuoju pelės mygtuku spustelėkite norimą rodyklę ir spustelėkite „ Ištrinti“, tada patvirtinkite savo veiksmus spustelėdami „ Gerai».

arba taip pat galite naudoti instrukcijas NURODYTI INDEKSO, Pavyzdžiui
DROP INDEX IX_NonClustered ON TestTable
Reikėtų pažymėti, kad DROP INDEX teiginys netaikomas indeksams, kurie buvo sukurti sukuriant PRIMARY KEY ir UNIQUE apribojimus. Tokiu atveju, norėdami atsisakyti indekso, turite naudoti teiginį ALTER TABLE su sąlyga DROP CONSTRAINT.
„Microsoft SQL Server“ indeksų optimizavimas
Atlikus duomenų atnaujinimo, pridėjimo arba ištrynimo operacijas SQL lentelės serveris automatiškai atlieka atitinkamus indeksų pakeitimus, tačiau laikui bėgant visi šie pakeitimai gali sukelti indekso duomenų fragmentaciją, t.y. jie bus išsklaidyti visoje duomenų bazėje. Indeksų suskaidymas sumažina užklausos našumą, todėl periodiškai reikia atlikti indekso priežiūros operacijas, būtent defragmentavimą, pvz., indekso pertvarkymo ir atkūrimo operacijas.
Kada naudoti indekso pertvarkymą ir kada atstatyti?
Norėdami atsakyti į šį klausimą, pirmiausia turite nustatyti indekso suskaidymo laipsnį, nes priklausomai nuo indekso suskaidymo, vienas ar kitas defragmentavimo būdas bus geresnis ir efektyvesnis. Norėdami nustatyti indekso suskaidymo laipsnį, galite naudoti sistemos lentelės funkciją sys.dm_db_index_physical_stats, kuriame pateikiama išsami informacija apie indeksų dydį ir suskaidymą. Pavyzdžiui, naudodami šią užklausą galite sužinoti visų dabartinės duomenų bazės lentelių indekso suskaidymo laipsnį.
PASIRINKITE OBJEKTO_NAME indeksuoja KAIP T2 Į T1.objekto_id = T2.objekto_id IR T1.index_id = T2.index_id
Šiuo atveju mus domina stulpelis avg_fragmentation_in_procent, t.y. loginio suskaidymo procentas.
- Jei suskaidymo laipsnis yra mažesnis nei 5%, indekso pertvarkyti ar atstatyti iš viso nereikėtų pradėti;
- Jei suskaidymo laipsnis yra nuo 5 iki 30%, prasminga pradėti indekso pertvarką, nes šią operaciją naudoja minimalius sistemos resursus ir nereikalauja ilgalaikių užraktų;
- Jei suskaidymo laipsnis yra didesnis nei 30%, tada indeksą reikia atkurti, nes ši operacija su dideliu suskaidymu duoda didesnį poveikį nei indekso pertvarkymo operacija.
Asmeniškai galiu pridėti štai ką, jei turite nedidelę įmonę ir duomenų bazė nereikalauja maksimalios išvesties 24 valandas per parą, t.y. Kadangi tai nėra itin aktyvi duomenų bazė, galite saugiai periodiškai atlikti indeksų atkūrimo operaciją, net nenustatydami suskaidymo laipsnio.
Indeksų pertvarkymas
Indekso reorganizavimas yra indekso defragmentavimo procesas, kuris defragmentuoja lapų lygio sugrupuotas ir nesugrupuotas lentelių ir rodinių rodykles, fiziškai pertvarkant lapų lygio puslapius pagal loginę tvarką ( iš kairės į dešinę) galiniai mazgai.
Norėdami pertvarkyti indeksą, galite naudoti like grafinis įrankis SSMS ir Transact-SQL sakiniai.
Indekso pertvarkymas naudojant valdymo studiją

Indekso pertvarkymas naudojant Transact-SQL
ALTER INDEX IX_NonClustered ON TestTable REORGANIZE GO
Indeksų atstatymas
Indekso atkūrimas yra procesas, kuris pašalina seną indeksą ir sukuria naują, taip pašalindamas susiskaidymą.
Norėdami atkurti indeksus, galite naudoti du metodus.
Pirmas. Naudojant sakinį ALTER INDEX su sąlyga REBUILD. Šis teiginys pakeičia DBCC DBREINDEX teiginį. Paprastai tai yra metodas, naudojamas masiniam indeksų atkūrimui.
Pavyzdys
ALTER INDEX IX_NonClustered ON TestTable REBUILD GO
Ir antra, naudojant CREATE INDEX teiginį su DROP_EXISTING sąlyga. Galima naudoti, pavyzdžiui, indekso atkūrimui pakeičiant jo apibrėžimą, t.y. pagrindinių stulpelių pridėjimas arba pašalinimas.
Pavyzdys
KURTI NEKLUSTERINGĄ INDEX IX_NonClustered ON Test Table (CategoryID ASC) WITH (DROP_EXISTING = ON) GO
Atkūrimo funkcija taip pat pasiekiama „Management Studio“. Dešiniuoju pelės mygtuku spustelėkite pagal reikiamą indeksą " Atstatyti».

Taip baigiama medžiaga apie „Microsoft SQL Server“ indeksų pagrindus. Jei jus domina T-SQL kalba, rekomenduoju perskaityti mano knygą „