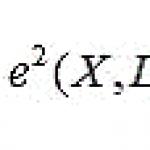1. Direktno korištenje podataka, ili pohrana podataka.
U ovom slučaju, početni podaci se pohranjuju u eksplicitno detaljnom obliku i direktno se koriste u fazama i/ili raščlanjivanje izuzetaka... Problem sa ovom grupom metoda je što kada se koriste, može biti teško analizirati veoma velike baze podataka.
Metode ove grupe: klaster analiza, metoda najbližeg susjeda, metoda k-najbližeg susjeda, rezoniranje po analogiji.
2. Identifikacija i upotreba formalizovanih uzorci, ili šabloni za destilaciju.
Sa tehnologijom šabloni za destilaciju jedan uzorak (šablon) informacija se izdvaja iz početnih podataka i transformiše u neke formalne konstrukcije, čiji oblik zavisi od primenjene metode rudarenja podataka. Ovaj proces se provodi u fazi besplatno pretraživanje, prva grupa metoda u principu nema ovu fazu. U fazama prediktivno modeliranje i raščlanjivanje izuzetaka koriste se rezultati faze besplatno pretraživanje, mnogo su kompaktnije od samih baza podataka. Podsjetimo da se konstrukcije ovih modela mogu interpretirati od strane analitičara ili ih ne pratiti („crne kutije“).
Metode u ovoj grupi: logičke metode; metode vizualizacije; metode unakrsne tabele; metode zasnovane na jednačinama.
Logičke metode, ili metode logičke indukcije, uključuju: nejasne upite i analize; simbolička pravila; stabla odlučivanja; genetski algoritmi.
Metode ove grupe su, možda, najshvatljivije - one formaliziraju pronađene obrasce, u većini slučajeva, u prilično transparentnom obliku sa stanovišta korisnika. Rezultirajuća pravila mogu uključivati kontinuirane i diskretne varijable. Treba napomenuti da se stabla odluka mogu lako pretvoriti u simboličke skupove pravila generiranjem jednog pravila duž putanje od korijena stabla do njegovog vrh terminala... Stabla odlučivanja i pravila su zapravo različiti načini rješavanja jednog problema i razlikuju se samo po svojim mogućnostima. Osim toga, implementacija pravila se provodi sporijim algoritmima od indukcije stabala odlučivanja.
Metode unakrsnog tabuliranja: agenti, Bayesove (povjerenje) mreže, unakrsna tabularna vizualizacija. Posljednja metoda ne odgovara sasvim jednom od svojstava Data Mining-a - neovisno pretraživanje uzorci analitički sistem. Međutim, pružanje informacija u obliku unakrsnih tabela osigurava implementaciju glavnog zadatka Data Mininga - traženje obrazaca, stoga se ova metoda može smatrati i jednom od metoda Data Mininga.
Metode zasnovane na jednadžbi.
Metode ove grupe iskazuju otkrivene obrasce u obliku matematičkih izraza – jednačina. Stoga, oni mogu raditi samo s numeričkim varijablama, a varijable drugih tipova moraju biti kodirane u skladu s tim. To donekle ograničava primjenu metoda ove grupe, ali se one široko koriste u rješavanju različitih problema, posebno problema prognoziranja.
Glavne metode ove grupe: statističke metode i neuronske mreže
Za rješavanje problema predviđanja najčešće se koriste statističke metode. Postoje mnoge metode statističke analize podataka, među njima, na primjer, korelaciono-regresijska analiza, korelacija vremenskih serija, identifikacija trendova u vremenskim serijama, harmonska analiza.
Druga klasifikacija dijeli čitav niz metoda Data Mininga u dvije grupe: statističke i kibernetičke metode. Ova shema particioniranja zasniva se na različitim pristupima podučavanju matematičkih modela.
Treba napomenuti da postoje dva pristupa klasifikaciji statističkih metoda kao Data Mining. Prvi od njih suprotstavlja statističke metode i Data Mining, a njegove pristalice klasične statističke metode smatraju posebnim pravcem analize podataka. Prema drugom pristupu, statističke metode analize su dio matematičkog alata Data Mining. Većina uglednih izvora koristi drugi pristup.
U ovoj klasifikaciji razlikuju se dvije grupe metoda:
- statističke metode zasnovane na korištenju prosječnog akumuliranog iskustva, koje se ogleda u retrospektivnim podacima;
- kibernetičke metode, koje uključuju mnoge heterogene matematičke pristupe.
Nedostatak takve klasifikacije: i statistički i kibernetički algoritmi se na ovaj ili onaj način oslanjaju na poređenje statističkog iskustva sa rezultatima praćenja trenutne situacije.
Prednost ove klasifikacije je njena pogodnost za interpretaciju - koristi se za opisivanje matematičkih alata savremenog pristupa ekstrakcija znanja iz nizova početnih zapažanja (operativnih i retrospektivnih), tj. u zadacima rudarenja podataka.
Pogledajmo bliže gore predstavljene grupe.
Metode istraživanja statističkih podataka
Metode predstavljaju četiri međusobno povezana dijela:
- preliminarna analiza prirode statističkih podataka (testiranje hipoteza stacionarnosti, normalnosti, nezavisnosti, homogenosti, procjena oblika funkcije distribucije, njenih parametara, itd.);
- identifikaciju veza i uzorci(linearna i nelinearna regresiona analiza, korelaciona analiza, itd.);
- multivarijantna statistička analiza (linearna i nelinearna diskriminantna analiza, klaster analiza, komponentna analiza, faktorska analiza i sl.);
- dinamički modeli i prognoza vremenskih serija.
Arsenal statističkih metoda Data Mining je klasifikovan u četiri grupe metoda:
- Deskriptivna analiza i opis početnih podataka.
- Analiza odnosa (korelacija i regresiona analiza, faktorska analiza, analiza varijanse).
- Multivarijantna statistička analiza (komponentna analiza, diskriminantna analiza, multivarijantna regresiona analiza, kanonske korelacije, itd.).
- Analiza vremenskih serija ( dinamički modeli i predviđanje).
Cybernetic Methods of Data Mining
Drugi pravac Data Mininga je skup pristupa ujedinjenih idejom kompjuterske matematike i upotrebom teorije umjetne inteligencije.
data mining) i na „grubu“ istraživačku analizu, koja čini osnovu online analitičke obrade (OnLine Analytical Processing, OLAP), dok je jedna od glavnih odredbi Data Mininga potraga za neočiglednim uzorci... Alati za rudarenje podataka mogu sami pronaći takve obrasce i također samostalno formirati hipoteze o odnosima. Budući da je formulisanje hipoteze o zavisnostima najteži zadatak, prednost Data Mininga u odnosu na druge metode analize je očigledna.Većina statističkih metoda za identifikaciju odnosa u podacima koristi koncept usrednjavanja na uzorku, što dovodi do operacija na nepostojećim vrijednostima, dok Data Mining radi na stvarnim vrijednostima.
OLAP je pogodniji za razumijevanje historijskih podataka, Data Mining se oslanja na historijske podatke kako bi odgovorio na pitanja o budućnosti.
Perspektive tehnologije rudarenja podataka
Potencijal Data Mininga daje zeleno svjetlo za pomicanje granica tehnologije. S obzirom na izglede za Data Mining, mogući su sljedeći pravci razvoja:
- identifikaciju tipova predmetnih oblasti sa odgovarajućom heuristikom, čija će formalizacija olakšati rešavanje odgovarajućih problema Data Mininga koji se odnose na ove oblasti;
- stvaranje formalnih jezika i logičkih sredstava uz pomoć kojih će se formalizirati rasuđivanje i čija će automatizacija postati alat za rješavanje problema Data Mininga u određenim predmetnim oblastima;
- Kreiranje metoda rudarenja podataka koje ne samo da mogu izvući obrasce iz podataka, već i formirati neke teorije zasnovane na empirijskim podacima;
- prevazilaženje značajnog jaza između mogućnosti Data Mining alata i teorijskog napretka u ovoj oblasti.
Ako posmatramo budućnost Data Mininga u kratkom roku, onda je očigledno da je razvoj ove tehnologije najviše usmjeren na područja vezana za poslovanje.
Kratkoročno, proizvodi za rudarenje podataka mogu postati uobičajeni i bitni poput e-pošte i, na primjer, korisnici ih koriste da pronađu najniže cijene za određeni proizvod ili najjeftinije karte.
Dugoročno gledano, budućnost Data Mininga je zaista uzbudljiva – to može biti potraga inteligentnih agenata za novim tretmanima za različite bolesti i novim razumijevanjem prirode svemira.
Međutim, Data Mining je prepun potencijalne opasnosti - na kraju krajeva, sve veća količina informacija postaje dostupna kroz svjetsku mrežu, uključujući privatne informacije, a iz njih se može dobiti sve više znanja:
Ne tako davno najveća internet prodavnica "Amazon" bila je u centru skandala oko patenta "Metode i sistemi za pomoć korisnicima u kupovini robe", koji nije ništa drugo do još jedan Data Mining proizvod dizajniran za prikupljanje ličnih podataka o prodavnici. posjetitelja. Nova metodologija omogućava predviđanje budućih zahtjeva na osnovu činjenica o kupovini, kao i izvođenje zaključaka o njihovoj svrsi. Svrha ove tehnike je, kao što je već spomenuto, da se dobije što više informacija o klijentima, uključujući i privatne prirode (pol, godine, preferencije, itd.). Na ovaj način se prikupljaju podaci o privatnosti kupaca u radnji, kao i članova njihovih porodica, uključujući i djecu. Ovo posljednje je zabranjeno zakonodavstvom mnogih zemalja - prikupljanje podataka o maloljetnicima tamo je moguće samo uz dozvolu roditelja.
Istraživanja primjećuju da postoje uspješna rješenja koja koriste Data Mining i loša iskustva s ovom tehnologijom. Oblasti u kojima će tehnologija rudarenja podataka najvjerovatnije biti uspješna imaju sljedeće karakteristike:
- zahtijevaju rješenja zasnovana na znanju;
- imaju promenljivo okruženje;
- imati dostupne, dovoljne i smislene podatke;
- daju visoke dividende od ispravnih odluka.
Postojeći pristupi analizi
Dugo vremena disciplina Data Mining nije bila prepoznata kao punopravno nezavisno polje analize podataka, ponekad se naziva i „dvorište statistike“ (Pregibon, 1997).
Do danas je utvrđeno nekoliko tačaka gledišta o Data Miningu. Pristalice jednog od njih smatraju ga fatamorganom, odvlačeći pažnju od klasične analize.
Ministarstvo obrazovanja i nauke Ruske Federacije
Federalna državna budžetska obrazovna ustanova visokog stručnog obrazovanja
"NACIONALNI ISTRAŽIVAČKI TOMSKI POLITEHNIČKI UNIVERZITET"
Institut za kibernetiku
Smjer Informatika i računarsko inženjerstvo
Odjeljenje VT
Test
u disciplini informatika i računarsko inženjerstvo
Tema: Metode rudarenja podataka
Uvod
Data Mining. Osnovni pojmovi i definicije
1 Koraci u procesu rudarenja podataka
2 Komponente rudarskih sistema
3 Metode rudarenja podataka u Data Miningu
Metode rudarenja podataka
1 Izvođenje pravila asocijacije
2 Algoritmi neuronske mreže
3 Metode najbližeg susjeda i k-Nearest Neighbor
4 Stabla odluka
5 Algoritmi grupisanja
6 Genetski algoritmi
Prijave
Proizvođači alata za rudarenje podataka
Kritika metoda
Zaključak
Bibliografija
Uvod
Rezultat razvoja informacionih tehnologija je kolosalna količina podataka akumuliranih u elektronskom obliku, koja raste velikom brzinom. Štaviše, podaci po pravilu imaju heterogenu strukturu (tekstovi, slike, audio, video, hipertekstualni dokumenti, relacione baze podataka). Podaci akumulirani tokom dugog vremenskog perioda mogu sadržavati obrasce, trendove i odnose, koji su vrijedne informacije u planiranju, predviđanju, donošenju odluka i kontroli procesa. Međutim, osoba fizički nije u stanju da efikasno analizira takve količine heterogenih podataka. Metode tradicionalne matematičke statistike dugo su tvrdile da su glavni alat za analizu podataka. Međutim, oni ne dozvoljavaju sintetiziranje novih hipoteza, već se mogu koristiti samo za potvrđivanje prethodno formuliranih hipoteza i “grubu” istraživačku analizu, koja čini osnovu online analitičke obrade (OLAP). Često se upravo formuliranje hipoteze pokaže kao najteži zadatak prilikom provođenja analize za kasnije donošenje odluka, budući da nisu svi obrasci u podacima očigledni na prvi pogled. Stoga se tehnologije rudarenja podataka smatraju jednom od najvažnijih i obećavajućih tema za istraživanje i primjenu u industriji informacionih tehnologija. U ovom slučaju, data mining se odnosi na proces utvrđivanja novih, tačnih i potencijalno korisnih znanja na osnovu velikih količina podataka. Stoga je MIT Technology Review opisao Data Mining kao jednu od deset tehnologija u nastajanju koje će promijeniti svijet.
1. Data Mining. Osnovni pojmovi i definicije
Data Mining je proces otkrivanja ranije nepoznatih, netrivijalnih, praktično korisnih i pristupačnih tumačenja znanja u „sirovim“ podacima, koji su neophodni za donošenje odluka u različitim sferama ljudske aktivnosti.
Suština i svrha Data Mining tehnologije mogu se formulirati na sljedeći način: to je tehnologija koja je dizajnirana da traži velike količine podataka za neočigledne, objektivne i korisne u praksi obrasce.
Neočigledni obrasci su obrasci koji se ne mogu otkriti standardnim metodama obrade informacija ili savjetima stručnjaka.
Objektivne pravilnosti treba shvatiti kao pravilnosti koje u potpunosti odgovaraju stvarnosti, za razliku od stručnog mišljenja koje je uvijek subjektivno.
Ovaj koncept analize podataka pretpostavlja da:
§ podaci mogu biti netačni, nepotpuni (sadrže praznine), kontradiktorni, heterogeni, indirektni, a istovremeno imaju ogromne količine; stoga, razumijevanje podataka u specifičnim aplikacijama zahtijeva značajan intelektualni napor;
§ sami algoritmi za analizu podataka mogu imati "elemente inteligencije", posebno sposobnost učenja iz presedana, odnosno izvođenja opštih zaključaka na osnovu privatnih zapažanja; razvoj takvih algoritama takođe zahteva značajan intelektualni napor;
§ Procesi obrade sirovih podataka u informaciju, a informacija u znanje ne mogu se izvoditi ručno i zahtijevaju automatizaciju.
Data Mining tehnologija se zasniva na konceptu obrazaca (obrasci) koji odražavaju fragmente višedimenzionalnih odnosa u podacima. Ovi obrasci predstavljaju obrasce svojstvene poduzorcima podataka koji se mogu kompaktno izraziti u ljudskom čitljivom obliku.
Potraga za obrascima provodi se metodama koje nisu ograničene okvirom apriornih pretpostavki o strukturi uzorka i vrsti distribucija vrijednosti analiziranih indikatora.
Važna karakteristika Data Mininga je nestandardnost i neočiglednost traženih obrazaca. Drugim riječima, alati za obradu podataka razlikuju se od alata za statističku obradu podataka i OLAP alata po tome što umjesto provjere međuzavisnosti koje su korisnici unaprijed pretpostavili, oni su u mogućnosti da sami pronađu takve međuzavisnosti na osnovu dostupnih podataka i izgrade hipoteze o njihovoj prirodi. . Postoji pet standardnih tipova obrazaca identifikovanih metodama Data Mininga:
· Asocijacija - velika vjerovatnoća povezanosti događaja jedan s drugim. Primjer asocijacije su artikli u trgovini koji se često kupuju zajedno;
· Slijed - velika vjerovatnoća lanca događaja vezanih za vrijeme. Primjer slijeda je situacija u kojoj će, u određenom vremenskom periodu nakon kupovine jednog proizvoda, s velikim stepenom vjerovatnoće biti kupljen drugi;
· Klasifikacija - postoje znakovi koji karakterišu grupu kojoj pripada ovaj ili onaj događaj ili predmet;
· Grupisanje – obrazac sličan klasifikaciji i drugačiji od nje po tome što same grupe nisu specificirane – otkrivaju se automatski tokom obrade podataka;
· Privremeni obrasci – prisustvo obrazaca u dinamici ponašanja određenih podataka. Tipičan primjer vremenskog obrasca su sezonske fluktuacije potražnje za određenim dobrima ili uslugama.
1.1 Koraci u procesu rudarenja podataka
Tradicionalno, u procesu rudarenja podataka razlikuju se sljedeće faze:
1. Proučavanje predmetne oblasti, kao rezultat čega se formulišu glavni ciljevi analize.
2. Prikupljanje podataka.
Prethodna obrada podataka:
a. Čišćenje podataka - eliminacija nedosljednosti i nasumične "šumove" iz originalnih podataka
b. Integracija podataka je konsolidacija podataka iz više mogućih izvora u jedno spremište. Transformacija podataka. U ovoj fazi, podaci se pretvaraju u oblik pogodan za analizu. Agregacija podataka, uzorkovanje atributa, kompresija podataka i smanjenje dimenzionalnosti se obično koriste.
4. Analiza podataka. Unutar ove faze primjenjuju se algoritmi rudarenja za izdvajanje uzoraka.
5. Interpretacija pronađenih obrazaca. Ovaj korak može uključivati vizualizaciju ekstrahovanih obrazaca, identifikaciju zaista korisnih obrazaca na osnovu neke korisne funkcije.
Upotreba novih znanja.
1.2 Komponente rudarskih sistema
Tipično, sistemi za rudarenje podataka imaju sljedeće glavne komponente:
1. Baza podataka, skladište podataka ili drugo spremište informacija. To može biti jedna ili više baza podataka, skladište podataka, proračunske tablice, druge vrste spremišta koja se mogu očistiti i integrirati.
2. Server baze podataka ili skladište podataka. Navedeni server je odgovoran za izdvajanje bitnih podataka na osnovu zahtjeva korisnika.
Baza znanja. To je znanje o domeni koje ukazuje na to kako pretraživati i procjenjivati korisnost rezultujućih obrazaca.
Usluga rudarenja znanja. On je sastavni dio sistema za rudarenje podataka i sadrži skup funkcionalnih modula za zadatke kao što su karakterizacija, pronalaženje asocijacija, klasifikacija, klaster analiza i analiza varijanse.
Modul za evaluaciju uzoraka. Ova komponenta izračunava mjere od interesa ili korisnosti obrazaca.
Grafičko korisničko sučelje. Ovaj modul je odgovoran za komunikaciju između korisnika i data mining sistema, vizualizaciju obrazaca u različitim oblicima.
1.3 Metode rudarenja podataka u Data Miningu
Većina analitičkih metoda koje se koriste u tehnologiji rudarenja podataka su dobro poznati matematički algoritmi i metode. Novost u njihovoj primjeni je mogućnost njihove upotrebe u rješavanju određenih specifičnih problema, zbog novonastalih mogućnosti hardvera i softvera. Treba napomenuti da je većina metoda Data Mininga razvijena u okviru teorije umjetne inteligencije. Razmotrimo najčešće korištene metode:
Zaključivanje pravila udruživanja.
2. Algoritmi neuronske mreže, čija je ideja zasnovana na analogiji sa funkcionisanjem nervnog tkiva i leži u činjenici da se početni parametri smatraju signalima koji se transformišu u skladu sa postojećim vezama između "neurona", a odgovor cijele mreže smatra se odgovorom koji proizlazi iz analize originalnih podataka.
Izbor bliskog analoga početnih podataka iz postojećih istorijskih podataka. Naziva se i metodom "najbližeg susjeda".
Stabla odlučivanja su hijerarhijska struktura zasnovana na skupu pitanja koja zahtijevaju odgovor „Da“ ili „Ne“.
Modeli klastera se koriste za grupisanje sličnih događaja u grupe na osnovu sličnih vrednosti nekoliko polja u skupu podataka.
U narednom poglavlju ćemo detaljnije opisati gore navedene metode.
2. Metode rudarenja podataka
2.1 Zaključak pravila asocijacije
Pravila asocijacije su pravila oblika "ako ... onda ...". Traženje takvih pravila u skupu podataka otkriva skrivene odnose u naizgled nepovezanim podacima. Jedan od najčešće citiranih primjera traženja pravila asocijacije je problem pronalaženja stabilnih odnosa u korpi za kupovinu. Izazov je utvrditi koje artikle kupci zajedno kupuju kako bi trgovci mogli pravilno staviti te artikle u prodavnicu kako bi povećali prodaju.
Pravila asocijacije su definirana kao izjave oblika (X1, X2, ..., Xn) -> Y, gdje se pretpostavlja da Y može biti prisutan u transakciji, pod uvjetom da su prisutni X1, X2, ..., Xn u istoj transakciji. Treba napomenuti da riječ "može" implicira da pravilo nije identitet, već vrijedi samo s određenom vjerovatnoćom. Osim toga, Y može biti skup stavki, a ne samo jedna stavka. Vjerovatnoća pronalaska Y u transakciji u kojoj postoje elementi X1, X2,…, Xn naziva se povjerenje. Procenat transakcija koje sadrže pravilo od ukupnog broja transakcija naziva se podrška. Nivo povjerenja koji pravilo mora premašiti naziva se zanimljivošću.
Postoje različite vrste pravila asocijacije. U svom najjednostavnijem obliku, pravila udruživanja samo prijavljuju prisustvo ili odsustvo udruženja. Takva pravila se nazivaju Boolean Association Rule. Primjer takvog pravila bi bio: "Kupci koji kupuju jogurt kupuju i maslac s niskim udjelom masti."
Pravila koja spajaju višestruka pravila pridruživanja nazivaju se višerazinskim ili generaliziranim pravilima asocijacije. Prilikom konstruisanja ovakvih pravila, stavke se obično grupišu prema hijerarhiji, a pretrage se sprovode na najvišem konceptualnom nivou. Na primjer, "mušterije koje kupuju mlijeko kupuju i kruh." U ovom primjeru, mlijeko i kruh sadrže hijerarhiju različitih vrsta i marki, ali pretraživanje na donjem nivou neće pronaći zanimljiva pravila.
Složenija vrsta pravila su pravila kvantitativne asocijacije. Ovaj tip pravila se traži pomoću kvantitativnih (na primjer, cijena) ili kategoričkih (na primjer, spol) atributa, a definira se kao (
Gore navedeni tipovi pravila ne bave se činjenicom da su transakcije, po svojoj prirodi, vremenski zavisne. Na primjer, pretraživanje prije nego što je proizvod na listi za prodaju ili nakon što je nestao s tržišta negativno će utjecati na prag podrške. Imajući to na umu, uveden je koncept životnog vijeka atributa u algoritmima pretraživanja pravila vremenskih asocijacija.
Problem pronalaženja pravila asocijacije može se generalno razložiti na dva dela: traženje skupova elemenata koji se često pojavljuju i generisanje pravila na osnovu pronađenih skupova koji se često pojavljuju. Uglavnom, prethodna istraživanja su pratila ove pravce i proširila ih u različitim pravcima.
Od pojave Apriori algoritma, ovaj algoritam je najčešće korišten u prvom koraku. Mnoga poboljšanja, na primjer, u brzini i skalabilnosti, imaju za cilj poboljšanje Apriori algoritma, ispravljanje njegove pogrešne osobine generiranja previše kandidata za najčešće skupove elemenata. Apriori generiše skupove stavki koristeći samo velike skupove stavki pronađene u prethodnom koraku, bez ponovnog ispitivanja transakcija. Modificirani AprioriTid algoritam poboljšava Apriori korištenjem baze podataka samo pri prvom prolazu. Izračuni u narednim koracima koriste samo podatke generirane u prvom prolazu, koji su mnogo manji od originalne baze podataka. To dovodi do ogromnog povećanja produktivnosti. Daljnja poboljšana verzija algoritma, nazvana AprioriHybrid, može se dobiti korištenjem Apriori u prvih nekoliko prolaza, a zatim, na kasnijim prolazima, kada se k-ti skupovi kandidata već mogu u potpunosti dodijeliti u memoriji računara, prebaciti se na AprioriTid.
Daljnji napori na poboljšanju algoritma Apriori odnose se na paralelizaciju algoritma (distribucija brojanja, distribucija podataka, distribucija kandidata itd.), njegovo skaliranje (inteligentna distribucija podataka, hibridna distribucija), uvođenje novih struktura podataka, kao što su stabla elemenata koji se često javljaju (FP-rast).
Drugi korak je uglavnom autentičan i zanimljiv. Nove modifikacije dodaju dimenziju, kvalitet i vremensku podršku opisanu iznad tradicionalnim Booleovim pravilima. Za pronalaženje pravila često se koristi evolucijski algoritam.
2.2 Algoritmi neuronske mreže
Umjetne neuronske mreže su se pojavile kao rezultat primjene matematičkog aparata u proučavanju funkcionisanja ljudskog nervnog sistema kako bi se on reproducirao. Naime: sposobnost nervnog sistema da uči i ispravlja greške, što bi trebalo da omogući simulaciju, iako prilično grubo, rada ljudskog mozga. Glavni strukturni i funkcionalni dio neuronske mreže je formalni neuron, prikazan na Sl. 1, gdje su x0, x1, ..., xn komponente vektora ulaznih signala, w0, w1, ..., wn su vrijednosti težina ulaznih signala neurona, a y je izlazni signal neurona.
Rice. 1. Formalni neuron: sinapse (1), sabirač (2), transduktor (3).
Formalni neuron se sastoji od 3 tipa elemenata: sinapse, zbrajalice i pretvarača. Sinapsa karakterizira snagu veze između dva neurona.
Sabirač dodaje ulazne signale prethodno pomnožene odgovarajućim težinama. Konvertor implementira funkciju jednog argumenta - izlaz sabirača. Ova funkcija se naziva aktivacijska funkcija ili prijenosna funkcija neurona.
Gore opisani formalni neuroni mogu se kombinirati na takav način da se izlazni signali nekih neurona unose u druge. Rezultirajući skup međusobno povezanih neurona naziva se umjetne neuronske mreže (ANN), ili, ukratko, neuronske mreže.
Postoje tri općenite vrste neurona, ovisno o njihovoj poziciji u neuronskoj mreži:
Ulazni neuroni, koji primaju ulazne signale. Takvi neuroni, neuroni, u pravilu imaju jedan ulaz s jediničnom težinom, nema pristranosti, a vrijednost izlaza neurona jednaka je ulaznom signalu;
Izlazni neuroni (izlazni čvorovi), čije izlazne vrijednosti predstavljaju rezultirajuće izlazne signale neuronske mreže;
Skriveni neuroni, koji nemaju direktne veze sa ulaznim signalima, dok vrijednosti izlaznih signala skrivenih neurona nisu izlazni signali ANN.
Prema strukturi interneuronskih veza razlikuju se dvije klase ANN:
ANN direktnog širenja, u kojem se signal širi samo od ulaznih neurona do izlaznih neurona.
Rekurentna ANN - ANN sa povratnim informacijama. U takvim ANN-ima, signali se mogu prenositi između bilo kojeg neurona, bez obzira na njihovu lokaciju u ANN-u.
Postoje dva opšta pristupa podučavanju ANN:
Učenje sa učiteljem.
Učenje bez nastavnika.
Učenje pod nadzorom uključuje korištenje unaprijed definiranog skupa nastavnih primjera. Svaki primjer sadrži vektor ulaznih signala i odgovarajući vektor referentnih izlaznih signala, koji zavise od zadatka. Ovaj skup se naziva set za obuku ili set za obuku. Obuka neuronske mreže ima za cilj takvu promjenu težine ANN veza, u kojoj se vrijednost izlaznih signala ANN što manje razlikuje od traženih vrijednosti izlaznih signala za dati vektor ulaza signale.
U nenadgledanom učenju, težine veza se prilagođavaju ili kao rezultat nadmetanja između neurona, ili uzimajući u obzir korelaciju izlaznih signala neurona između kojih postoji veza. U slučaju učenja bez nadzora, uzorak za obuku se ne koristi.
Neuronske mreže se koriste za rješavanje širokog spektra zadataka, kao što je planiranje tereta za svemirske šatlove i predviđanje deviznih kurseva. Međutim, oni se ne koriste često u sistemima za rudarenje podataka zbog složenosti modela (znanje zabilježeno kao težine nekoliko stotina interneuralnih veza je potpuno izvan analize i interpretacije od strane ljudi) i dugog vremena obuke na velikom uzorku obuke. S druge strane, neuronske mreže imaju takve prednosti za korištenje u zadacima analize podataka kao što su otpornost na bučne podatke i visoka tačnost.
2.3 Metode najbližeg susjeda i k-najbližih susjeda
Algoritam najbližeg susjeda i algoritam k-najbližeg susjeda (KNN) zasnovani su na sličnosti karakteristika. Algoritam najbližeg susjeda odabire objekt među svim poznatim objektima koji je što je moguće bliži (koristeći metriku udaljenosti između objekata, na primjer, Euklid) novom ranije nepoznatom objektu. Glavni problem sa metodom najbližeg susjeda je njena osjetljivost na vanjske vrijednosti u podacima obuke.
Opisani problem može se izbjeći KNN algoritmom, koji među svim opažanjima razlikuje već k-najbliže susjede slične novom objektu. Na osnovu klasa najbližih susjeda donosi se odluka o novom objektu. Važan zadatak ovog algoritma je odabir koeficijenta k - broja zapisa koji će se smatrati sličnim. Modifikacija algoritma, u kojoj je doprinos susjeda proporcionalan udaljenosti do novog objekta (metoda k-ponderisanih najbližih susjeda) omogućava postizanje veće preciznosti klasifikacije. Metoda k najbližih susjeda nam također omogućava da procijenimo tačnost prognoze. Na primjer, svih k najbližih susjeda imaju istu klasu, tada je vjerovatnoća da će provjereni objekt imati istu klasu vrlo velika.
Među karakteristikama algoritma, vrijedi istaknuti otpornost na anomalne ispade, jer je vjerovatnoća da takav zapis padne u broj k-najbližih susjeda mala. Ako se to desilo, onda će uticaj na glasanje (posebno ponderisan) (za k> 2) takođe biti beznačajan, pa će stoga i uticaj na rezultat klasifikacije biti mali. Također, prednosti su jednostavna implementacija, lakoća interpretacije rezultata algoritma, mogućnost modifikacije algoritma korištenjem najprikladnije kombinacije funkcija i metrika, što vam omogućava da prilagodite algoritam za određeni zadatak. KNN algoritam također ima niz nedostataka. Prvo, skup podataka koji se koristi za algoritam mora biti reprezentativan. Drugo, model se ne može odvojiti od podataka: svi primjeri se moraju koristiti za klasifikaciju novog primjera. Ova karakteristika ozbiljno ograničava upotrebu algoritma.
2.4 Stabla odlučivanja
Pod pojmom "stabla odlučivanja" podrazumeva se porodica algoritama zasnovana na predstavljanju pravila klasifikacije u hijerarhijskoj, sekvencijalnoj strukturi. Ovo je najpopularnija klasa algoritama za rješavanje problema rudarenja podataka.
Porodica algoritama za konstruisanje stabala odluka omogućava predviđanje vrednosti parametra za dati slučaj na osnovu velike količine podataka o drugim sličnim slučajevima. Obično se algoritmi ove porodice koriste za rješavanje problema koji omogućavaju podjelu svih izvornih podataka u nekoliko diskretnih grupa.
Kada se algoritmi za konstruisanje stabala odluka primjenjuju na skup ulaznih podataka, rezultat se prikazuje u obliku stabla. Takvi algoritmi dozvoljavaju nekoliko nivoa takve podjele, dijeleći rezultirajuće grupe (grane stabla) na manje na osnovu drugih karakteristika. Podjela se nastavlja sve dok vrijednosti koje bi trebale biti predviđene ne postanu iste (ili, u slučaju kontinuirane vrijednosti predviđenog parametra, zatvorene) za sve dobijene grupe (listove stabla). Ove vrijednosti se koriste za predviđanje na osnovu ovog modela.
Rad algoritama za konstruisanje stabala odlučivanja zasniva se na primeni metoda regresione i korelacione analize. Jedan od najpopularnijih algoritama u ovoj porodici je CART (Classification and Regression Trees), zasnovan na podjeli podataka u grani stabla na dvije podređene grane; u ovom slučaju, dalja podjela jedne ili druge grane ovisi o tome koliko je početnih podataka opisano ovom granom. Nekoliko drugih sličnih algoritama omogućava vam da podijelite granu na više podređenih grana. U ovom slučaju, podjela se vrši na osnovu najvećeg koeficijenta korelacije za opisanu granu podataka između parametra prema kojem se podjela vrši i parametra koji se predviđa u budućnosti.
Popularnost pristupa povezana je sa jasnoćom i jasnoćom. Ali stabla odlučivanja u osnovi nisu u stanju da pronađu „najbolja“ (najpotpunija i najtačnija) pravila u podacima. Oni implementiraju naivni princip sekvencijalnog gledanja karakteristika i zapravo pronalaze dijelove stvarnih obrazaca, stvarajući samo iluziju logičnog zaključka.
2.5 Algoritmi grupisanja
Grupiranje je zadatak razlaganja skupa objekata u grupe koje se nazivaju klasteri. Glavna razlika između klasteriranja i klasifikacije je u tome što lista grupa nije jasno specificirana i određena je tokom rada algoritma.
Primjena klaster analize općenito se svodi na sljedeće faze:
· Odabir uzorka objekata za grupisanje;
· Određivanje skupa varijabli pomoću kojih će se evaluirati objekti u uzorku. Ako je potrebno, normalizirajte vrijednosti varijabli;
· Izračunavanje vrijednosti mjere sličnosti između objekata;
· Primena metode klaster analize za kreiranje grupa sličnih objekata (klastera);
· Prezentacija rezultata analize.
Nakon dobijanja i analize rezultata, moguće je prilagoditi odabranu metriku i metodu klasteriranja dok se ne dobije optimalan rezultat.
Među algoritmima klasteriranja razlikuju se hijerarhijske i ravne grupe. Hijerarhijski algoritmi (koji se nazivaju i taksonomijski algoritmi) ne izgrađuju jednu particiju uzorka u disjunktne klastere, već sistem ugniježđenih particija. Dakle, izlaz algoritma je stablo klastera čiji je korijen cijeli uzorak, a listovi najmanji klasteri. Flat algoritmi grade jednu particiju objekata u disjunktne klastere.
Druga klasifikacija algoritama za grupisanje je na jasne i nejasne algoritme. Jasni (ili ne-preklapajući) algoritmi dodeljuju broj klastera svakom uzorku objekta, to jest, svaki objekat pripada samo jednom klasteru. Fazni (ili preklapajući) algoritmi povezuju svaki objekat sa skupom stvarnih vrednosti koje pokazuju stepen odnosa objekta sa klasterima. Dakle, svaki objekat pripada svakom klasteru sa nekom verovatnoćom.
Među hijerarhijskim algoritmima za grupisanje, postoje dva glavna tipa: algoritmi odozdo prema gore i odozgo prema dolje. Algoritmi odozgo prema dolje rade na principu odozgo prema dolje: prvo se svi objekti smjeste u jedan klaster, koji se zatim dijeli na sve manje i manje klastere. Češći su algoritmi odozdo prema gore, koji na početku rada svaki objekt stavljaju u poseban klaster, a zatim kombinuju klastere u sve veće i veće sve dok svi objekti u uzorku ne budu sadržani u jednom klasteru. Tako se konstruiše sistem ugniježđenih particija. Rezultati takvih algoritama se obično prikazuju u obliku stabla.
Nedostatak hijerarhijskih algoritama je sistem punih particija, što može biti redundantno u kontekstu problema koji se rješava.
Razmotrite sada ravne algoritme. Najjednostavniji u ovoj klasi su kvadratni algoritmi. Problem klasteriranja za ove algoritme može se smatrati konstruiranjem optimalnog podjele objekata u grupe. U ovom slučaju, optimalnost se može definirati kao zahtjev za minimiziranjem srednje kvadratne greške particije:
 ,
,
gdje c j - "centar mase" klastera j(tačka sa prosječnim vrijednostima karakteristika za dati klaster).
Najčešći algoritam u ovoj kategoriji je k-means metoda. Ovaj algoritam gradi zadani broj klastera koji se nalaze što je više moguće. Rad algoritma podijeljen je u nekoliko faza:
Slučajno birajte k tačke koje su početni "centri mase" klastera.
2. Dodijelite svaki objekt grupi s najbližim "centrom mase".
Ukoliko kriterijum za zaustavljanje algoritma nije zadovoljen, vratite se na tačku 2.
Kao kriterijum za zaustavljanje rada algoritma obično se bira minimalna promena srednje kvadratne greške. Također je moguće zaustaviti rad algoritma ako u koraku 2 nije bilo objekata premještenih iz klastera u klaster. Nedostaci ovog algoritma uključuju potrebu da se specificira broj klastera za particioniranje.
Najpopularniji algoritam rasplinutog klastera je algoritam c-means. To je modifikacija metode k-means. Koraci algoritma:
1. Odaberite početnu rasplinutu particiju n objekti na k klastera odabirom matrice članstva U veličina n x k.
2. Koristeći matricu U, pronaći vrijednost kriterija fuzzy greške:
 ,
,
gdje c k - "centar mase" rasplinutog klastera k:
3. Pregrupirajte objekte kako biste smanjili ovu vrijednost kriterija fuzzy greške.
4. Vratite se na korak 2 dok se matrica ne promijeni U neće postati beznačajan.
Ovaj algoritam možda neće raditi ako je broj klastera unaprijed nepoznat ili je potrebno nedvosmisleno dodijeliti svaki objekt jednom klasteru.
Sledeća grupa algoritama su algoritmi zasnovani na teoriji grafova. Suština ovakvih algoritama je da je izbor objekata predstavljen u obliku grafa G = (V, E), čiji vrhovi odgovaraju objektima, a ivice imaju težinu jednaku "udaljenosti" između objekata. Prednosti algoritama za grupisanje grafova su jasnoća, relativna lakoća implementacije i mogućnost raznih poboljšanja na osnovu geometrijskih razmatranja. Glavni algoritmi su algoritam za izdvajanje povezanih komponenti, algoritam za konstruisanje minimalnog razapinjućeg stabla i algoritam za klasterisanje sloj po sloj.
Za odabir parametra R obično se iscrtava histogram parnih distribucija udaljenosti. U problemima sa dobro izraženom klaster strukturom podataka, histogram će imati dva vrha - jedan odgovara udaljenostima unutar klastera, drugi - međuklasterskim udaljenostima. Parametar R se bira iz zone minimuma između ovih vrhova. U isto vrijeme, prilično je teško kontrolirati broj klastera korištenjem praga udaljenosti.
Algoritam minimalnog razapinjućeg stabla prvo konstruiše minimalno razapinjuće stablo na grafu, a zatim sekvencijalno uklanja ivice sa najvećom težinom. Algoritam klasteriranja sloj po sloj bazira se na odabiru povezanih komponenti grafa na određenom nivou udaljenosti između objekata (vrhova). Nivo udaljenosti je postavljen pragom udaljenosti c... Na primjer, ako je udaljenost između objekata, onda.
Algoritam za grupisanje slojeva po sloju formira niz podgrafova grafa G koji odražavaju hijerarhijske odnose između klastera:
![]() ,
,
gdje G t = (V, E t )
- graf na nivou sa t, ![]() ,
,
sa t je t-ti prag udaljenosti, m je broj nivoa hijerarhije,
G 0 = (V, o), o je prazan skup ivica grafa dobijen za t 0 = 1,
G m = G, odnosno graf objekata bez ograničenja udaljenosti (dužine ivica grafa), budući da t m = 1.
Promjenom pragova udaljenosti ( sa 0 , …, sa m), gdje je 0 = sa 0 < sa 1 < …< sa m = 1, moguće je kontrolisati dubinu hijerarhije rezultirajućih klastera. Dakle, algoritam klasteriranja sloj-po-sloj je sposoban kreirati i ravno i hijerarhijsko particioniranje podataka.
Klasterizacija vam omogućava da postignete sljedeće ciljeve:
· Poboljšava razumijevanje podataka identifikacijom strukturnih grupa. Podjela uzorka na grupe sličnih objekata omogućava pojednostavljenje dalje obrade podataka i donošenja odluka primjenom vlastite metode analize na svaki klaster;
· Omogućava kompaktno pohranjivanje podataka. Da biste to učinili, umjesto pohranjivanja cijelog uzorka, možete ostaviti jedno tipično zapažanje iz svakog klastera;
· Detekcija novih atipičnih objekata koji nisu uključeni ni u jedan klaster.
Tipično, grupiranje se koristi kao pomoć u analizi podataka.
2.6 Genetski algoritmi
Genetski algoritmi spadaju u univerzalne metode optimizacije koje omogućavaju rješavanje problema različitog tipa (kombinatorni, opći problemi sa i bez ograničenja) i različitog stepena složenosti. Istovremeno, genetske algoritme karakteriše mogućnost jednokriterijumske i višekriterijumske pretrage u velikom prostoru čiji pejzaž nije gladak.
Ova grupa metoda koristi iterativni proces evolucije niza generacija modela, uključujući operacije selekcije, mutacije i ukrštanja. Na početku algoritma, populacija se formira nasumično. Za procjenu kvalitete kodiranih rješenja koristi se funkcija fitnesa koja je neophodna za izračunavanje fitnesa svakog pojedinca. Prema rezultatima procjene pojedinaca, za prelazak se biraju najprilagođeniji od njih. Kao rezultat ukrštanja odabranih jedinki korištenjem genetskog crossing-over operatora, nastaju potomci čija se genetska informacija formira kao rezultat razmjene hromozomskih informacija između roditeljskih jedinki. Stvoreni potomci formiraju novu populaciju, a dio potomaka mutira, što se izražava nasumičnom promjenom njihovih genotipova. Faza koja uključuje sekvencu "Procjena populacije" - "Selekcija" - "Ukrštanje" - "Mutacija" naziva se generacija. Evolucija stanovništva sastoji se od niza takvih generacija.
Razlikuju se sljedeći algoritmi za odabir pojedinaca za ukrštanje:
· Panmiksija. Obje osobe koje čine roditeljski par su nasumično odabrane iz cijele populacije. Svaki pojedinac može postati član više parova. Ovaj pristup je univerzalan, ali efikasnost algoritma opada sa povećanjem veličine populacije.
· Odabir. Roditelji mogu postati pojedinci koji imaju barem prosječnu kondiciju. Ovaj pristup omogućava bržu konvergenciju algoritma.
· Inbreeding. Metoda se zasniva na formiranju para na osnovu bliskog odnosa. Ovdje se pod srodstvom podrazumijeva udaljenost između članova populacije, kako u smislu geometrijske udaljenosti jedinki u prostoru parametara, tako i Hemingove udaljenosti između genotipova. Stoga se pravi razlika između genotipskog i fenotipskog inbreedinga. Prvi član para za ukrštanje bira se nasumično, a drugi će, sa većom vjerovatnoćom, biti pojedinac što mu je bliže. Inbreeding se može okarakterizirati svojstvom koncentracije pretrage u lokalnim čvorovima, što zapravo dovodi do podjele populacije u zasebne lokalne grupe oko područja krajolika sumnjivih na ekstrem.
· Outbreeding. Formiranje para na bazi udaljene veze, za najudaljenije pojedince. Outbreeding ima za cilj sprečavanje konvergencije algoritma prema već pronađenim rješenjima, prisiljavajući algoritam da traži nova, neistražena područja.
Algoritmi za formiranje nove populacije:
· Izbor sa pomakom. Od svih individua sa istim genotipovima, prednost se daje onima čija je kondicija veća. Time se postižu dva cilja: ne gube se najbolje pronađena rješenja s različitim skupovima hromozoma; u populaciji se konstantno održava dovoljna genetska raznolikost. Raseljavanje formira novu populaciju udaljenih pojedinaca, umjesto da se pojedinci grupišu oko trenutno pronađenog rješenja. Ova metoda se koristi za multi-ekstremne zadatke.
· Elitni izbor. Elitne metode selekcije osiguravaju da će najbolji članovi populacije zajamčiti opstanak. Istovremeno, neki od najboljih pojedinaca prelaze u sljedeću generaciju bez ikakvih promjena. Brza konvergencija koju pruža elitna selekcija može se nadoknaditi odgovarajućom metodom roditeljske selekcije. U ovom slučaju se često koristi vanbreding. Upravo je ova kombinacija "outbreeding - elitna selekcija" jedna od najefikasnijih.
· Izbor turnira. Odabir turnira implementira n turnira za odabir n pojedinaca. Svaki turnir je izgrađen na uzorku od k elemenata iz populacije, i odabiru najboljeg pojedinca među njima. Najčešći izbor turnira sa k = 2.
Jedna od najpopularnijih primena genetskih algoritama u oblasti Data Mininga je potraga za najoptimalnijim modelom (potraga za algoritmom koji odgovara specifičnostima određenog područja). Genetski algoritmi se prvenstveno koriste za optimizaciju topologije i težine neuronske mreže. Međutim, moguće ih je koristiti i kao samostalni alat.
3. Područja primjene
Tehnologija rudarenja podataka ima zaista širok spektar primjena, budući da je zapravo skup univerzalnih alata za analizu podataka bilo koje vrste.
Marketing
Jedna od najranijih oblasti u kojoj su primenjene tehnologije rudarenja podataka bio je marketing. Zadatak koji je započeo razvoj metoda Data Mininga naziva se analiza korpe za kupovinu.
Ovaj zadatak je identificirati proizvode koje kupci žele kupiti zajedno. Poznavanje korpe za kupovinu neophodno je za reklamne kampanje, formiranje ličnih preporuka za kupce, izradu strategije za stvaranje zaliha robe i metode njihovog rasporeda u prodajnim prostorima.
I u marketingu se rješavaju takvi zadaci kao što je određivanje ciljne publike određenog proizvoda radi njegove uspješnije promocije; studija vremenskih obrazaca koja pomaže preduzećima da donesu odluke o zalihama; stvaranje prediktivnih modela, koji omogućavaju preduzećima da prepoznaju prirodu potreba različitih kategorija kupaca sa određenim ponašanjem; predviđanje lojalnosti kupaca, što vam omogućava da unapred identifikujete trenutak kada kupac odlazi kada analizirate njegovo ponašanje i, eventualno, sprečite gubitak vrednog kupca.
Industrija
Jedan od važnih pravaca u ovoj oblasti je praćenje i kontrola kvaliteta, gde je pomoću alata za analizu moguće predvideti kvar opreme, pojavu kvarova i planirati popravke. Predviđanje popularnosti određenih karakteristika i poznavanje karakteristika koje se obično naručuju zajedno pomaže u optimizaciji proizvodnje, usmjeravajući je na stvarne potrebe potrošača.
Lijek
U medicini se prilično uspješno koristi i analiza podataka. Primjer zadataka je analiza rezultata pregleda, dijagnostika, poređenje efikasnosti metoda liječenja i lijekova, analiza bolesti i njihove distribucije, identifikacija nuspojava. Tehnologije rudarenja podataka, kao što su pravila povezivanja i sekvencijalni obrasci, uspješno su korištene za identifikaciju veza između uzimanja lijekova i nuspojava.
Molekularna genetika i genetski inženjering
Možda je najakutniji i u isto vrijeme najjasniji zadatak otkrivanja obrazaca u eksperimentalnim podacima u molekularnoj genetici i genetskom inženjeringu. Ovdje je to formulirano kao definicija markera, koji se podrazumijevaju kao genetski kodovi koji kontroliraju određene fenotipske karakteristike živog organizma. Takvi kodovi mogu sadržavati stotine, hiljade ili više povezanih elemenata. Rezultat analitičke analize podataka je i odnos između promjena u DNK sekvenci osobe i rizika od razvoja raznih bolesti, koji su otkrili genetičari.
Primijenjena hemija
Data Mining metode se takođe koriste u oblasti primenjene hemije. Ovdje se često postavlja pitanje razjašnjenja karakteristika hemijske strukture pojedinih jedinjenja koje određuju njihova svojstva. Ovaj problem je posebno relevantan u analizi složenih hemijskih jedinjenja, čiji opis uključuje stotine i hiljade strukturnih elemenata i njihovih veza.
Borba protiv kriminala
Data Mining alati su relativno nedavno korišćeni u obezbeđivanju sigurnosti, međutim, već su dobijeni praktični rezultati koji potvrđuju efikasnost data mininga u ovoj oblasti. Švicarski naučnici razvili su sistem za analizu protestnih aktivnosti kako bi se predvidjeli budući incidenti i sistem za praćenje novih sajber prijetnji i akcija hakera u svijetu. Potonji sistem omogućava predviđanje sajber prijetnji i drugih rizika sigurnosti informacija. Također, metode Data Mininga se uspješno koriste za otkrivanje prijevara s kreditnim karticama. Analizom prošlih transakcija za koje se kasnije pokazalo da su bile lažne, banka identifikuje neke stereotipe takve prevare.
Ostale aplikacije
· Analiza rizika. Na primjer, identifikacijom kombinacija faktora povezanih s plaćenim štetama, osiguravači mogu smanjiti svoje gubitke od obaveza. Poznat je slučaj kada je velika osiguravajuća kompanija u Sjedinjenim Državama otkrila da su iznosi plaćeni na izjavama ljudi koji su u braku dvostruko veći od iznosa plaćenih na izjavama samaca. Kompanija je odgovorila na ovo novo saznanje revidiranjem svoje opšte politike popusta za porodične kupce.
· Meteorologija. Koriste se prognoze vremena korištenjem neuronskih mreža, a posebno se koriste samoorganizirajuće Kohonenove karte.
· Kadrovska politika. Alati za analizu pomažu HR službama da izaberu najuspješnije kandidate na osnovu analize njihovih biografskih podataka, da modeliraju karakteristike idealnih zaposlenika za određenu poziciju.
4. Proizvođači alata za rudarenje podataka
Alati za rudarenje podataka tradicionalno spadaju u skupe softverske proizvode. Stoga su donedavno glavni potrošači ove tehnologije bile banke, finansijska i osiguravajuća društva, velika trgovačka preduzeća, a glavni zadaci koji su zahtijevali korištenje Data Mining-a bili su procjena kreditnih rizika i rizika osiguranja i izrada marketinške politike, tarifnih planova. i drugi principi rada sa klijentima. Posljednjih godina situacija je doživjela određene promjene: na tržištu softvera pojavili su se relativno jeftini alati za rudarenje podataka, pa čak i besplatni sistemi distribucije, koji su ovu tehnologiju učinili dostupnom malim i srednjim preduzećima.
Među plaćenim alatima i sistemima za analizu podataka, vodeći su SAS Institute (SAS Enterprise Miner), SPSS (SPSS, Clementine) i StatSoft (STATISTICA Data Miner). Prilično poznata su rješenja Angoss (Angoss KnowledgeSTUDIO), IBM (IBM SPSS Modeler), Microsoft (Microsoft Analysis Services) i (Oracle) Oracle Data Mining.
Izbor slobodnog softvera je također raznolik. Postoje i univerzalni alati za analizu, kao što su JHepWork, KNIME, Orange, RapidMiner, i specijalizovani alati, na primjer, Carrot2 - okvir za grupisanje tekstualnih podataka i rezultata pretraživanja, Chemicalize.org - rješenje u oblasti primijenjene hemije, NLTK (Natural Language Toolkit) alat za obradu prirodnog jezika.
5. Kritika metoda
Rezultati Data Mininga u velikoj mjeri zavise od nivoa pripreme podataka, a ne od "čudesnih mogućnosti" nekog algoritma ili skupa algoritama. Oko 75% rada na Data Mining-u sastoji se od prikupljanja podataka, koje se obavlja i prije upotrebe alata za analizu. Nepismeno korišćenje alata će dovesti do besmislenog trošenja potencijala kompanije, a ponekad i miliona dolara.
Prema Herbu Edelsteinu, svjetski poznatom stručnjaku za rudarenje podataka, skladištenje podataka i CRM: „Nedavna studija Two Crows pokazala je da je Data Mining još uvijek u ranoj fazi. Mnoge organizacije su zainteresirane za ovu tehnologiju, ali samo nekoliko njih aktivno implementira takve projekte. Uspeli smo da otkrijemo još jednu važnu tačku: proces implementacije Data Mininga u praksi se pokazao komplikovanijim nego što se očekivalo, a timovi su bili poneseni mitom da su Data Mining alati jednostavni za korišćenje. Pretpostavlja se da je dovoljno pokrenuti takav alat na terabajtnoj bazi podataka, a korisne informacije će se odmah pojaviti. Zapravo, uspješan Data Mining projekat zahtijeva razumijevanje suštine aktivnosti, poznavanje podataka i alata, kao i proces analize podataka." Dakle, prije upotrebe Data Mining tehnologije, potrebno je pažljivo analizirati ograničenja koja nameću metode i kritična pitanja povezana s njom, kao i trezveno procijeniti mogućnosti tehnologije. Kritična pitanja uključuju sljedeće:
1. Tehnologija ne može dati odgovore na pitanja koja nisu postavljena. Ne može zamijeniti analitičara, već mu samo pruža moćno oruđe za olakšavanje i poboljšanje njegovog rada.
2. Složenost razvoja i rada aplikacije Data Mining.
Budući da je ova tehnologija multidisciplinarna oblast, za razvoj aplikacije koja uključuje Data Mining potrebno je uključiti stručnjake iz različitih oblasti, kao i osigurati njihovu kvalitetnu interakciju.
3. Kvalifikacije korisnika.
Različiti alati za rudarenje podataka imaju različite stepene jednostavnosti za korisnika i zahtijevaju određene kvalifikacije korisnika. Stoga softver mora odgovarati nivou obuke korisnika. Upotreba Data Mininga treba biti neraskidivo povezana sa poboljšanjem kvalifikacija korisnika. Međutim, trenutno postoji nekoliko stručnjaka za rudarenje podataka koji su dobro upućeni u poslovne procese.
4. Izdvajanje korisnih informacija nemoguće je bez dobrog razumijevanja suštine podataka.
Potrebni su pažljivi odabir modela i interpretacija zavisnosti ili obrazaca koji su pronađeni. Stoga, rad s takvim alatima zahtijeva blisku saradnju između stručnjaka za predmet i stručnjaka za alate za rudarenje podataka. Stalni modeli moraju biti inteligentno integrirani u poslovne procese kako bi mogli procijeniti i ažurirati modele. Nedavno su sistemi za rudarenje podataka isporučeni kao dio tehnologije skladišta podataka.
5. Složenost pripreme podataka.
Za uspješnu analizu potrebna je visokokvalitetna predobrada podataka. Prema analitičarima i korisnicima baze podataka, proces pretprocesiranja može zauzeti do 80% cjelokupnog procesa Data Mininga.
Dakle, da bi tehnologija radila sama za sebe, bit će potrebno mnogo truda i vremena, koji se troše na preliminarnu analizu podataka, odabir modela i njegovu korekciju.
6. Veliki postotak lažnih, nepouzdanih ili beskorisnih rezultata.
Uz pomoć Data Mining tehnologija možete pronaći zaista vrlo vrijedne informacije koje mogu dati značajnu prednost u daljem planiranju, upravljanju i donošenju odluka. Međutim, rezultati dobiveni korištenjem Data Mining metoda često sadrže lažne i besmislene zaključke. Mnogi stručnjaci tvrde da alati za rudarenje podataka mogu proizvesti ogromnu količinu statistički nepouzdanih rezultata. Da bi se smanjio postotak ovakvih rezultata, potrebno je provjeriti adekvatnost dobijenih modela na podacima testa. Međutim, nemoguće je u potpunosti izbjeći lažne zaključke.
7. Visoka cijena.
Kvalitetan softverski proizvod rezultat je značajnog truda od strane programera. Stoga se softver za rudarenje podataka tradicionalno smatra skupim softverskim proizvodom.
8. Dostupnost dovoljnih reprezentativnih podataka.
Alati za rudarenje podataka, za razliku od statističkih, teoretski ne zahtevaju strogo definisanu količinu istorijskih podataka. Ova karakteristika može uzrokovati otkrivanje netačnih, lažnih modela i, kao rezultat, donošenje pogrešnih odluka na osnovu njih. Neophodno je kontrolisati statističku značajnost otkrivenog znanja.
algoritam neuronske mreže klastering data mining
Zaključak
Dat je kratak opis sfera primjene i date kritike Data Mining tehnologije i mišljenja stručnjaka iz ove oblasti.
Listaknjiževnost
1. Han i Micheline Kamber. Data Mining: koncepti i tehnike. Drugo izdanje. - Univerzitet Illinois u Urbana-Champaign
Berry, Michael J. A. Tehnike rudarenja podataka: za marketing, prodaju i upravljanje odnosima s kupcima - 2. izdanje.
Siu Nin Lam. Otkrivanje pravila asocijacije u rudarenju podataka. - Odsjek za kompjuterske nauke Univerziteta Illinois u Urbana-Champaign
Pošaljite svoj dobar rad u bazu znanja je jednostavno. Koristite obrazac ispod
Studenti, postdiplomci, mladi naučnici koji koriste bazu znanja u svom studiranju i radu biće vam veoma zahvalni.
Slični dokumenti
- analiza putanja kupaca od posjete web stranici do kupovine robe
- procjena efikasnosti usluge, analiza kvarova zbog nedostatka robe
- povezivanje robe koja je interesantna posetiocima
- analiza korpe za kupovinu;
- kreiranje prediktivnih modela i modeli klasifikacije kupaca i kupljene robe;
- kreiranje profila kupaca;
- CRM, procjena lojalnosti kupaca različitih kategorija, planiranje programa lojalnosti;
- istraživanje vremenskih serija i vremenske zavisnosti, isticanje sezonskih faktora, procena efikasnosti promocija na velikom broju stvarnih podataka.
- klasifikacija korisnika na osnovu ključnih karakteristika poziva (učestalost, trajanje itd.), frekvencija SMS-a;
- prepoznavanje lojalnosti kupaca;
- definicija prevare itd.
- analiza rizika... Identifikovanjem kombinacija faktora povezanih sa isplaćenim štetama, osiguravači mogu smanjiti gubitke svojih obaveza. Poznat je slučaj kada je osiguravajuće društvo utvrdilo da su iznosi isplaćeni po potraživanjima osoba koje su u braku dvostruko veće od iznosa isplaćenih na potraživanja samaca. Kompanija je odgovorila revidiranjem svoje politike porodičnih popusta.
- otkrivanje prevare... Osiguravajuća društva mogu smanjiti prevaru tražeći specifične stereotipe u potraživanjima koji karakterišu odnos između advokata, doktora i potraživača.
Klasifikacija zadataka rudarenja podataka. Izrada izvještaja i zbrojeva. Funkcije Data Miner-a u Statistici. Problem klasifikacije, grupisanja i regresije. Alati za analizu Statistica Data Miner. Suština problema je traženje pravila asocijacije. Analiza prediktora preživljavanja.
seminarski rad, dodan 19.05.2011
Opis funkcionalnosti Data Mining tehnologije kao procesa za otkrivanje nepoznatih podataka. Proučavanje sistema zaključivanja asocijativnih pravila i mehanizama algoritama neuronske mreže. Opis algoritama klasteriranja i područja primjene Data Mininga.
test, dodano 14.06.2013
Osnove za grupisanje. Korištenje Data Mininga kao načina za "otkrivanje znanja u bazama podataka". Izbor algoritama za grupisanje. Dohvaćanje podataka iz skladišta baze podataka udaljene radionice. Grupiranje učenika i zadataka.
seminarski rad dodan 07.10.2017
Data mining, razvojna istorija rudarenja podataka i otkrivanje znanja. Tehnološki elementi i metode rudarenja podataka. Koraci u otkrivanju znanja. Detekcija promjena i odstupanja. Povezane discipline, pronalaženje informacija i ekstrakcija teksta.
izvještaj dodan 16.06.2012
Analiza problema koji nastaju primjenom metoda i algoritama klasteriranja. Osnovni algoritmi za grupisanje. RapidMiner softver kao okruženje za mašinsko učenje i analizu podataka. Procjena kvaliteta klasterizacije korištenjem Data Mining metoda.
seminarski rad, dodan 22.10.2012
Unapređenje tehnologija snimanja i skladištenja podataka. Specifičnost savremenih zahteva za obradu podataka informacija. Koncept obrazaca koji odražavaju fragmente višedimenzionalnih odnosa u podacima u srcu moderne tehnologije rudarenja podataka.
test, dodano 09.02.2010
Analiza upotrebe neuronskih mreža za predviđanje situacije i donošenje odluka na berzi korišćenjem softverskog paketa za modeliranje neuronskih mreža Trajan 3.0. Konverzija primarnih podataka, tabele. Ergonomska evaluacija programa.
disertacije, dodato 27.06.2011
Poteškoće u korištenju evolucijskih algoritama. Izgradnja računarskih sistema zasnovanih na principima prirodne selekcije. Nedostaci genetskih algoritama. Primjeri evolucijskih algoritama. Pravci i dijelovi evolucijskog modeliranja.
Želimo vam dobrodošlicu na Data Mining Portal - jedinstveni portal posvećen modernim metodama Data Mininga.
Data Mining tehnologije su moćan alat moderne poslovne inteligencije i rudarenja podataka za otkrivanje skrivenih obrazaca i izgradnju prediktivnih modela. Data Mining ili rudarenje znanja nije zasnovano na spekulativnom zaključivanju, već na stvarnim podacima.

Rice. 1. Šema aplikacije Data Mining
Definicija problema - Izjava o problemu: klasifikacija podataka, segmentacija, izgradnja prediktivnih modela, predviđanje.
Prikupljanje i priprema podataka - Prikupljanje i priprema podataka, čišćenje, verifikacija, brisanje duplikata zapisa.
Izrada modela - Izrada modela, procjena tačnosti.
Primena znanja - Primena modela za rešavanje datog problema.
Data Mining se koristi za implementaciju velikih analitičkih projekata u poslovanju, marketingu, internetu, telekomunikacijama, industriji, geologiji, medicini, farmaciji i drugim oblastima.
Data Mining vam omogućava da započnete proces pronalaženja značajnih korelacija i veza kao rezultat pregledavanja ogromnog niza podataka koristeći moderne metode prepoznavanja obrazaca i korištenje jedinstvenih analitičkih tehnologija, uključujući stabla odlučivanja i klasifikacije, grupiranje, metode neuronske mreže , i drugi.
Korisnik koji je prvi otkrio tehnologiju rudarenja podataka zadivljen je obiljem metoda i efikasnih algoritama koji omogućavaju pronalaženje pristupa rješavanju teških problema povezanih s analizom velikih količina podataka.
Općenito, Data Mining se može okarakterizirati kao tehnologija dizajnirana za pretraživanje velikih količina podataka. neočigledno, objektivan i praktično korisno uzorci.
Data Mining se zasniva na efikasnim metodama i algoritmima razvijenim za analizu nestrukturiranih podataka velikog obima i dimenzija.
Ključna stvar je da se čini da su podaci velikog obima i visoke dimenzije lišeni strukture i veza. Cilj tehnologije rudarenja podataka je da se identifikuju ove strukture i pronađu obrasci u kojima, na prvi pogled, vladaju haos i proizvoljnost.
Ovdje je trenutna studija slučaja aplikacija rudarenja podataka u farmaceutskoj industriji i industriji lijekova.
Interakcije lijekova rastući su problem sa kojim se susreće moderna zdravstvena zaštita.
S vremenom se broj propisanih lijekova (bez recepta i svih vrsta suplemenata) povećava, što čini sve vjerojatnijim da interakcije lijekova mogu uzrokovati ozbiljne nuspojave kojih liječnici i pacijenti nisu svjesni.
Ovo područje spada u postklinička istraživanja, kada je lijek već pušten na tržište i intenzivno se koristi.
Klinička ispitivanja se odnose na procjenu efikasnosti lijeka, ali ne uzimaju u obzir interakcije ovog lijeka s drugim lijekovima na tržištu.
Istraživači sa Univerziteta Stanford u Kaliforniji ispitali su bazu podataka o nuspojavama lijekova Uprave za hranu i lijekove (FDA) i otkrili da dva najčešće korištena lijeka - antidepresiv paroksetin i pravastatin, koji se koriste za snižavanje nivoa kolesterola - povećavaju rizik od razvoja dijabetesa ako se koriste zajedno.
Studija koja je sprovela sličnu analizu zasnovanu na podacima FDA identifikovala je 47 ranije nepoznatih štetnih interakcija.
Ovo je izvanredno, uz upozorenje da mnogi negativni efekti koje su prijavili pacijenti ostaju neprepoznati. Ovo je mjesto gdje online pretraga može dati sve od sebe.
Predstojeći kursevi Data Mining na StatSoft Akademiji za analizu podataka 2020
Započinjemo naše upoznavanje sa Data Mining-om koristeći divne video zapise Akademije za analizu podataka.
Obavezno pogledajte naše video zapise i shvatit ćete šta je Data Mining!
Video 1. Šta je Data Mining?
Video 2. Pregled metoda rudarenja podataka: stabla odlučivanja, generalizirani modeli predviđanja, grupiranje i još mnogo toga
JavaScript je onemogućen u vašem pretraživaču
Prije nego započnemo istraživački projekat, moramo organizirati proces pribavljanja podataka iz vanjskih izvora, sada ćemo pokazati kako se to radi.
Video će vas upoznati sa jedinstvenom tehnologijom STATISTICA Obrada baze podataka na licu mjesta i povezivanje podataka rudarenja sa stvarnim podacima.
Video 3. Redosled interakcije sa bazama podataka: grafički interfejs za izgradnju SQL upita Tehnologija obrade baze podataka na mestu
JavaScript je onemogućen u vašem pretraživaču
Sada razmatramo interaktivne tehnologije bušenja koje su efikasne u analizi podataka istraživanja. Sam izraz bušenje odražava vezu između tehnologije rudarenja podataka i geoloških istraživanja.
Video 4. Interaktivno bušenje: istraživanje i grafičke tehnike za interaktivno istraživanje podataka
JavaScript je onemogućen u vašem pretraživaču
Sada ćemo se upoznati s analizom asocijacija (pravila pridruživanja), ovi algoritmi vam omogućavaju da pronađete veze koje postoje u stvarnim podacima. Ključna stvar je efikasnost algoritama na velikim količinama podataka.
Rezultat algoritama analize linkova, na primjer algoritma Apriori, je pronalaženje pravila veze za objekte koji se proučavaju sa zadatom pouzdanošću, na primjer, 80%.
U geologiji, ovi algoritmi se mogu koristiti u istraživačkoj analizi minerala, na primjer, kako je karakteristika A povezana sa karakteristikama B i C.
Konkretne primjere takvih rješenja možete pronaći slijedeći naše linkove:
U maloprodaji algoritam Apriori ili njegove modifikacije omogućavaju vam da istražite odnos između različitih proizvoda, na primjer, prilikom prodaje parfimerije (parfem - lak - maskara, itd.) ili proizvoda različitih marki.
Analiza najzanimljivijih sekcija na sajtu takođe se može efikasno sprovesti korišćenjem pravila udruženja.
Dakle, pogledajte naš sljedeći video.
Video 5. Pravila asocijacije
JavaScript je onemogućen u vašem pretraživaču
Navedimo primjere primjene Data Mininga u određenim područjima.
Online trgovina:
Maloprodaja: analizirajte informacije o klijentima na osnovu kreditnih kartica, diskontnih kartica i još mnogo toga.
Tipični zadaci maloprodaje riješeni alatima za rudarenje podataka:
Sektor telekomunikacija otvara neograničene mogućnosti za primjenu metoda rudarenja podataka, kao i modernih big data tehnologija:
osiguranje:
Praktična primjena rudarenja podataka i rješavanje specifičnih problema predstavljena je u našem sljedećem videu.
Webinar 1. Webinar "Praktični zadaci rudarenja podataka: problemi i rješenja"
JavaScript je onemogućen u vašem pretraživačuWebinar 2. Webinar "Data Mining i Text Mining: Primjeri rješavanja stvarnih problema"
JavaScript je onemogućen u vašem pretraživaču
Možete dobiti dublje znanje o metodologiji i tehnologiji rudarenja podataka na kursevima StatSoft.