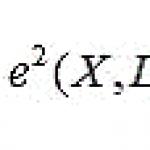1. Utilizarea directă a datelor sau stocare a datelor.
În acest caz, datele inițiale sunt stocate într-o formă explicit detaliată și sunt utilizate direct în etape și/sau analizarea excepțiilor... Problema cu acest grup de metode este că atunci când le folosiți, poate fi dificil să analizați baze de date foarte mari.
Metode din acest grup: analiza cluster, metoda celui mai apropiat vecin, metoda k-cel mai apropiat vecin, raționament prin analogie.
2. Identificarea și utilizarea formalizate modele, sau modele de distilare.
Cu tehnologie modele de distilare din datele inițiale se extrage un eșantion (șablon) de informații și se transformă în niște construcții formale, a căror formă depinde de metoda de Data Mining utilizată. Acest proces se realizează în etapă căutare gratuită, primul grup de metode nu are în principiu această etapă. Pe etape modelare predictivăși analizarea excepțiilor sunt utilizate rezultatele etapei căutare gratuită, sunt mult mai compacte decât bazele de date în sine. Să reamintim că construcțiile acestor modele pot fi interpretate de analist sau neurmate („cutii negre”).
Metode din acest grup: metode logice; metode de vizualizare; metode de tabulare încrucișată; metode bazate pe ecuații.
Metodele logice, sau metodele de inducție logică, includ: interogări și analize neclare; reguli simbolice; arbori de decizie; algoritmi genetici.
Metodele acestui grup sunt, poate, cele mai interpretabile - ele formalizează tiparele găsite, în cele mai multe cazuri, într-o formă destul de transparentă din punctul de vedere al utilizatorului. Regulile rezultate pot include variabile continue și discrete. Trebuie remarcat faptul că arborii de decizie pot fi convertiți cu ușurință în seturi de reguli simbolice prin generarea unei reguli de-a lungul căii de la rădăcina arborelui la acesta. partea superioară a terminalului... Arborele de decizie și regulile sunt de fapt modalități diferite de a rezolva o problemă și diferă doar prin capacitățile lor. În plus, implementarea regulilor este realizată de algoritmi mai lenți decât inducerea arborilor de decizie.
Metode de tabelare încrucișată: agenți, rețele bayesiene (încredere), vizualizare încrucișată. Ultima metodă nu corespunde în totalitate cu una dintre proprietățile Data Mining - căutare independentă modele sistem analitic. Cu toate acestea, furnizarea de informații sub formă de tabele încrucișate asigură implementarea sarcinii principale a Data Mining - căutarea modelelor, prin urmare această metodă poate fi considerată și una dintre metodele Data Mining.
Metode bazate pe ecuații.
Metodele acestui grup exprimă tiparele relevate sub formă de expresii matematice - ecuații. Prin urmare, ele pot funcționa numai cu variabile numerice, iar variabilele de alte tipuri trebuie să fie codificate corespunzător. Acest lucru limitează oarecum aplicarea metodelor acestui grup, cu toate acestea, ele sunt utilizate pe scară largă în rezolvarea diferitelor probleme, în special în prognozarea problemelor.
Principalele metode ale acestui grup: metode statistice și rețele neuronale
Metodele statistice sunt cel mai adesea folosite pentru a rezolva problemele de prognoză. Există multe metode de analiză a datelor statistice, printre care, de exemplu, analiza corelației-regresiune, corelarea seriilor temporale, identificarea tendințelor în seriale temporale, analiza armonică.
O altă clasificare împarte întreaga varietate de metode de Data Mining în două grupe: metode statistice și cibernetice. Această schemă de împărțire se bazează pe diferite abordări ale predării modelelor matematice.
Trebuie remarcat faptul că există două abordări pentru clasificarea metodelor statistice ca Data Mining. Prima dintre ele contrastează metodele statistice și Data Mining, susținătorii săi consideră că metodele statistice clasice sunt o direcție separată a analizei datelor. Conform celei de-a doua abordări, metodele statistice de analiză fac parte din setul de instrumente matematice Data Mining. Cele mai multe surse de renume adoptă a doua abordare.
În această clasificare, se disting două grupuri de metode:
- metode statistice bazate pe utilizarea experienței medii acumulate, care se reflectă în datele retrospective;
- metode cibernetice, care includ multe abordări matematice eterogene.
Dezavantajul unei astfel de clasificări: atât algoritmii statistici, cât și cei cibernetici se bazează într-un fel sau altul pe compararea experienței statistice cu rezultatele monitorizării situației actuale.
Avantajul acestei clasificări este comoditatea sa pentru interpretare - este folosită pentru a descrie instrumentele matematice ale abordării moderne a extragerea cunoștințelor din rețele de observații inițiale (operaționale și retrospective), adică în sarcinile Data Mining.
Să aruncăm o privire mai atentă asupra grupurilor prezentate mai sus.
Metode de extragere a datelor statistice
Metodele reprezintă patru secțiuni interdependente:
- analiza preliminară a naturii datelor statistice (testarea ipotezelor de staționaritate, normalitate, independență, omogenitate, evaluarea formei funcției de distribuție, a parametrilor acesteia etc.);
- identificarea legăturilor şi modele(analiza de regresie liniară și neliniară, analiza de corelație etc.);
- analiză statistică multivariată (analiza discriminantă liniară și neliniară, analiza cluster, analiza componentelor, analiza factorilor si etc.);
- modele dinamiceși prognoza serii temporale.
Arsenalul de metode statistice Data Mining este clasificat în patru grupe de metode:
- Analiza descriptivă și descrierea datelor inițiale.
- Analiza relațiilor (analiza de corelație și regresie, analiza factorilor, analiza variatiei).
- Analiză statistică multivariată (analiza componentelor, analiza discriminantă, analiza regresiei multivariate, corelații canonice etc.).
- Analiza serii temporale ( modele dinamiceși prognoză).
Metode cibernetice de extragere a datelor
A doua direcție a Data Mining este un set de abordări unite de ideea matematicii computerizate și de utilizarea teoriei inteligenței artificiale.
data mining) și pe analiza exploratorie „brutală”, care stă la baza prelucrărilor analitice online (OnLine Analytical Processing, OLAP), în timp ce una dintre principalele prevederi ale Data Mining-ului este căutarea unor elemente neevidente. modele... Instrumentele Data Mining pot găsi astfel de modele pe cont propriu și, de asemenea, pot forma în mod independent ipoteze despre relații. Întrucât formularea unei ipoteze privind dependențele este cea mai dificilă sarcină, avantajul Data Mining-ului în comparație cu alte metode de analiză este evident.Majoritatea metodelor statistice de identificare a relațiilor în date folosesc conceptul de medie pe un eșantion, ceea ce duce la operațiuni pe valori inexistente, în timp ce Data Mining operează pe valori reale.
OLAP este mai potrivit pentru înțelegerea datelor istorice, Data Mining se bazează pe date istorice pentru a răspunde întrebărilor despre viitor.
Perspectivele tehnologiei de minerit de date
Potențialul Data Mining dă undă verde pentru a depăși granițele tehnologiei. În ceea ce privește perspectivele pentru Data Mining, sunt posibile următoarele direcții de dezvoltare:
- identificarea tipurilor de domenii cu euristicile corespunzătoare, a căror formalizare va facilita rezolvarea problemelor corespunzătoare de Data Mining aferente acestor domenii;
- crearea de limbaje formale și mijloace logice, cu ajutorul cărora raționamentul va fi oficializat și a căror automatizare va deveni un instrument de rezolvare a problemelor de Data Mining în domenii specifice;
- Crearea unor metode de Data Mining care nu numai că pot extrage modele din date, ci și pot forma unele teorii bazate pe date empirice;
- depășirea unui decalaj semnificativ între capacitățile instrumentelor de Data Mining și progresele teoretice în acest domeniu.
Dacă ne gândim la viitorul Data Mining-ului pe termen scurt, atunci este evident că dezvoltarea acestei tehnologii este îndreptată cel mai mult către domenii legate de business.
Pe termen scurt, produsele Data Mining pot deveni la fel de comune și esențiale precum e-mailul și, de exemplu, pot fi folosite de utilizatori pentru a găsi cele mai mici prețuri pentru un anumit produs sau cele mai ieftine bilete.
Pe termen lung, viitorul Data Mining este cu adevărat interesant - poate fi o căutare de către agenți inteligenți atât pentru noi tratamente pentru diferite boli, cât și pentru o nouă înțelegere a naturii universului.
Cu toate acestea, Data Mining este plină de pericol potențial - la urma urmei, o cantitate din ce în ce mai mare de informații devine disponibilă prin intermediul rețelei mondiale, inclusiv informații private, și din ea se pot obține din ce în ce mai multe cunoștințe:
Nu cu mult timp în urmă, cel mai mare magazin online, Amazon, a fost în centrul unui scandal legat de brevetul său „Metode și sisteme pentru a ajuta utilizatorii să cumpere bunuri”, care nu este altceva decât un alt produs Data Mining conceput pentru a colecta date personale despre magazin. vizitatori. Noua metodologie face posibilă anticiparea cererilor viitoare pe baza faptelor de achiziție, precum și tragerea de concluzii cu privire la scopul acestora. Scopul acestei tehnici este, după cum am menționat mai sus, de a obține cât mai multe informații despre clienți, inclusiv de natură privată (sex, vârstă, preferințe etc.). În acest fel, sunt colectate date despre confidențialitatea cumpărătorilor din magazine, precum și a membrilor familiei acestora, inclusiv a copiilor. Acesta din urmă este interzis de legislația multor țări - colectarea de informații despre minori este posibilă acolo numai cu permisiunea părinților.
Cercetările notează că există atât soluții de succes care folosesc data mining, cât și experiențe proaste cu această tehnologie. Domeniile în care tehnologia Data Mining este cel mai probabil să aibă succes au următoarele caracteristici:
- necesită soluții bazate pe cunoștințe;
- au un mediu în schimbare;
- să aibă date accesibile, suficiente și semnificative;
- oferiți dividende mari din deciziile corecte.
Abordări existente ale analizei
Multă vreme, disciplina Data Mining nu a fost recunoscută ca un domeniu independent cu drepturi depline de analiză a datelor, uneori fiind numită „curtea din spate a statisticii” (Pregibon, 1997).
Până în prezent, au fost determinate mai multe puncte de vedere despre Data Mining. Susținătorii unuia dintre ele îl consideră un miraj, distragând atenția de la analiza clasică.
Ministerul Educației și Științei al Federației Ruse
Instituția de învățământ de învățământ profesional superior bugetar de stat federal
„UNIVERSITATEA POLITEHNICĂ TOMSK DE CERCETARE NAȚIONALĂ”
Institutul de Cibernetică
Directie Informatica si inginerie informatica
Departamentul de VT
Test
la disciplina informatică și inginerie informatică
Subiect: Metode de extragere a datelor
Introducere
Exploatarea datelor. Concepte de bază și definiții
1 Pași în procesul de extragere a datelor
2 Componentele sistemelor miniere
3 Metode de data mining în Data Mining
Metode de extragere a datelor
1 Derivarea regulilor de asociere
2 algoritmi de rețea neuronală
3 Metode de cel mai apropiat vecin și k-cel mai apropiat vecin
4 Arbori de decizie
5 algoritmi de grupare
6 Algoritmi genetici
Aplicații
Producători de instrumente pentru minerit de date
Critica metodelor
Concluzie
Bibliografie
Introducere
Rezultatul dezvoltării tehnologiei informației este o cantitate colosală de date acumulată în formă electronică, care crește într-un ritm rapid. Mai mult, datele, de regulă, au o structură eterogenă (texte, imagini, audio, video, documente hipertext, baze de date relaționale). Datele acumulate pe o perioadă lungă de timp pot conține modele, tendințe și relații, care sunt informații valoroase în planificare, prognoză, luare a deciziilor și controlul procesului. Cu toate acestea, o persoană este fizic incapabilă să analizeze eficient astfel de volume de date eterogene. Metodele statisticii matematice tradiționale au pretins de mult timp a fi instrumentul principal pentru analiza datelor. Cu toate acestea, ele nu permit sintetizarea de noi ipoteze, ci pot fi folosite doar pentru confirmarea ipotezelor formulate anterior și a analizei exploratorii „brutale”, care formează baza prelucrării analitice online (OLAP). Adesea, formularea unei ipoteze se dovedește a fi cea mai dificilă sarcină atunci când se efectuează analize pentru luarea deciziilor ulterioare, deoarece nu toate modelele din date sunt evidente la prima vedere. Prin urmare, tehnologiile de extragere a datelor sunt considerate una dintre cele mai importante și promițătoare subiecte pentru cercetare și aplicare în industria tehnologiei informației. În acest caz, data mining se referă la procesul de determinare a cunoștințelor noi, corecte și potențial utile pe baza unor cantități mari de date. Astfel, MIT Technology Review a descris data mining ca una dintre cele zece tehnologii emergente care vor schimba lumea.
1. Exploatarea datelor. Concepte de bază și definiții
Data Mining-ul este un proces de detectare a interpretării necunoscute anterior, netriviale, practic utile și accesibile a cunoștințelor în date „brute”, care este necesară pentru luarea deciziilor în diverse sfere ale activității umane.
Esența și scopul tehnologiei Data Mining pot fi formulate după cum urmează: este o tehnologie care este concepută pentru a căuta în cantități mari de date modele neevidente, obiective și utile în practică.
Tiparele neevidente sunt tipare care nu pot fi detectate prin metode standard de procesare a informațiilor sau prin sfatul experților.
Regularitățile obiective trebuie înțelese ca regularități care corespund pe deplin realității, spre deosebire de opinia experților, care este întotdeauna subiectivă.
Acest concept de analiză a datelor presupune că:
§ datele pot fi inexacte, incomplete (conțin lacune), contradictorii, eterogene, indirecte și, în același timp, să aibă volume gigantice; prin urmare, înțelegerea datelor în aplicații specifice necesită un efort intelectual semnificativ;
§ algoritmii de analiză a datelor în sine pot avea „elemente de inteligență”, în special, capacitatea de a învăța din precedente, adică de a trage concluzii generale pe baza observațiilor private; dezvoltarea unor astfel de algoritmi necesită, de asemenea, un efort intelectual semnificativ;
§ Procesele de prelucrare a datelor brute în informații și a informațiilor în cunoștințe nu pot fi efectuate manual și necesită automatizare.
Tehnologia Data Mining se bazează pe conceptul de modele (patterns) care reflectă fragmente de relații multidimensionale în date. Aceste modele reprezintă modele inerente subeșantioanelor de date care pot fi exprimate compact într-o formă care poate fi citită de om.
Căutarea tiparelor se realizează prin metode care nu sunt limitate de cadrul ipotezelor a priori despre structura eșantionului și tipul de distribuție a valorilor indicatorilor analizați.
O caracteristică importantă a Data Mining este non-standardul și neevidența tiparelor căutate. Cu alte cuvinte, instrumentele Data Mining diferă de instrumentele de prelucrare a datelor statistice și instrumentele OLAP prin faptul că, în loc să verifice interdependența asumate în prealabil de utilizatori, sunt capabili să găsească singuri astfel de interdependențe pe baza datelor disponibile și să construiască ipoteze despre natura lor. . Există cinci tipuri standard de modele identificate prin metodele Data Mining:
· Asociere - o mare probabilitate de conectare a evenimentelor între ele. Un exemplu de asociație sunt articolele dintr-un magazin care sunt adesea achiziționate împreună;
· Secvență - o probabilitate mare a unui lanț de evenimente legate în timp. Un exemplu de secvență este o situație în care, într-o anumită perioadă de timp de la achiziția unui produs, altul va fi achiziționat cu un grad ridicat de probabilitate;
· Clasificare - există semne care caracterizează grupul căruia îi aparține un eveniment sau un obiect;
· Clustering - un model asemănător clasificării și diferit de acesta prin faptul că grupurile în sine nu sunt specificate - sunt detectate automat în timpul prelucrării datelor;
· Tipare temporare - prezența tiparelor în dinamica comportamentului anumitor date. Un exemplu tipic de model temporal sunt fluctuațiile sezoniere ale cererii pentru anumite bunuri sau servicii.
1.1 Etape în procesul de extragere a datelor
În mod tradițional, în procesul de extragere a datelor se disting următoarele etape:
1. Studiul disciplinei, în urma căruia se formulează principalele scopuri ale analizei.
2. Colectarea datelor.
Preprocesarea datelor:
A. Curățarea datelor - eliminarea inconsecvențelor și a „zgomotului” aleatoriu din datele originale
b. Integrarea datelor este consolidarea datelor din mai multe surse posibile într-un singur depozit. Transformarea datelor. În această etapă, datele sunt convertite într-o formă adecvată pentru analiză. Agregarea datelor, eșantionarea atributelor, compresia datelor și reducerea dimensionalității sunt utilizate în mod obișnuit.
4. Analiza datelor. În această etapă, algoritmii de minerit sunt aplicați pentru a extrage modele.
5. Interpretarea tiparelor găsite. Acest pas poate include vizualizarea modelelor extrase, identificarea modelelor cu adevărat utile pe baza unei funcții de utilitate.
Utilizarea noilor cunoștințe.
1.2 Componentele sistemelor miniere
De obicei, sistemele de extragere a datelor au următoarele componente principale:
1. Baza de date, depozit de date sau alt depozit de informații. Poate fi una sau mai multe baze de date, depozit de date, foi de calcul, alte tipuri de depozite care pot fi curățate și integrate.
2. Server de baze de date sau depozit de date. Serverul specificat este responsabil pentru extragerea datelor esențiale pe baza solicitării utilizatorului.
Bază de cunoștințe. Cunoașterea domeniului este cea care indică cum să căutați și să evaluați utilitatea tiparelor rezultate.
Serviciul de minerit de cunoștințe. Este o parte integrantă a sistemului de data mining și conține un set de module funcționale pentru sarcini precum caracterizarea, găsirea de asociații, clasificare, analiza cluster și analiza varianței.
Modul de evaluare a modelului. Această componentă calculează măsurile de interes sau utilitatea tiparelor.
Interfață grafică cu utilizatorul. Acest modul este responsabil pentru comunicarea dintre utilizator și sistemul de data mining, vizualizarea tiparelor în diferite forme.
1.3 Metode de data mining în Data Mining
Cele mai multe dintre metodele analitice utilizate în tehnologia Data Mining sunt algoritmi și metode matematice bine-cunoscute. Nou în aplicația lor este posibilitatea utilizării lor în rezolvarea anumitor probleme specifice, datorită capacităților emergente ale hardware-ului și software-ului. Trebuie remarcat faptul că majoritatea metodelor de Data Mining au fost dezvoltate în cadrul teoriei inteligenței artificiale. Să luăm în considerare cele mai utilizate metode:
Încheierea regulilor de asociere.
2. Algoritmi de rețea neuronală, ideea cărora se bazează pe o analogie cu funcționarea țesutului nervos și constă în faptul că parametrii inițiali sunt considerați ca semnale care sunt transformate în conformitate cu conexiunile existente între „neuroni”, iar raspunsul intregii retele este considerat ca raspunsul rezultat din analiza datelor originale.
Selectarea unui analog apropiat al datelor inițiale din datele istorice existente. Denumită și metoda „cel mai apropiat vecin”.
Arborele de decizie reprezintă o structură ierarhică bazată pe un set de întrebări care necesită un răspuns „Da” sau „Nu”.
Modelele de clustere sunt folosite pentru a grupa evenimente similare în grupuri pe baza valorilor similare ale mai multor câmpuri dintr-un set de date.
În capitolul următor, vom descrie mai detaliat metodele de mai sus.
2. Metode de extragere a datelor
2.1 Deducerea regulilor de asociere
Regulile de asociere sunt reguli de forma „dacă... atunci...”. Căutarea unor astfel de reguli într-un set de date dezvăluie relații ascunse în date care aparent nu au legătură. Unul dintre cele mai frecvent citate exemple de căutare a regulilor de asociere este problema găsirii unor relații stabile în coșul de cumpărături. Provocarea este de a determina ce articole sunt achiziționate împreună de clienți, astfel încât agenții de marketing să poată plasa corect acele articole în magazin pentru a crește vânzările.
Regulile de asociere sunt definite ca instrucțiuni de forma (X1, X2, ..., Xn) -> Y, unde se presupune că Y poate fi prezent într-o tranzacție, cu condiția ca X1, X2, ..., Xn să fie prezent în aceeași tranzacție. Trebuie remarcat faptul că cuvântul „poate” implică faptul că regula nu este o identitate, ci este valabilă doar cu o oarecare probabilitate. În plus, Y poate fi un set de articole, mai degrabă decât un singur articol. Probabilitatea de a găsi Y într-o tranzacție în care există elemente X1, X2,…, Xn se numește încredere. Procentul de tranzacții care conțin o regulă din numărul total de tranzacții se numește suport. Nivelul de încredere pe care trebuie să-l depășească o regulă se numește interes.
Există diferite tipuri de reguli de asociere. În forma lor cea mai simplă, regulile de asociere raportează doar prezența sau absența unei asociații. Astfel de reguli se numesc Regula de asociere booleană. Un exemplu de astfel de regulă ar fi: „Clienții care cumpără iaurt cumpără și unt cu conținut scăzut de grăsimi”.
Regulile care reunesc mai multe reguli de asociere se numesc Reguli de asociere pe mai multe niveluri sau generalizate. La construirea unor astfel de reguli, articolele sunt de obicei grupate în funcție de o ierarhie, iar căutările sunt efectuate la cel mai înalt nivel conceptual. De exemplu, „clienții care cumpără lapte cumpără și pâine”. În acest exemplu, laptele și pâinea conțin o ierarhie de diferite tipuri și mărci, dar căutarea la nivelul de jos nu va găsi reguli interesante.
Un tip mai complex de regulă este Regulile Cantitative de Asociere. Acest tip de regulă este căutat folosind atribute cantitative (de exemplu, preț) sau categoriale (de exemplu, gen) și este definită ca (
Tipurile de reguli de mai sus nu abordează faptul că tranzacțiile sunt, prin însăși natura lor, dependente de timp. De exemplu, căutarea înainte ca un produs să fie listat spre vânzare sau după ce acesta a dispărut de pe piață va afecta negativ pragul de suport. Având în vedere acest lucru, a fost introdus conceptul de durata de viață a atributului în algoritmii de căutare a regulilor de asociere temporală.
Problema găsirii regulilor de asociere poate fi, în general, descompusă în două părți: căutarea unor seturi de elemente care apar frecvent și generarea de reguli bazate pe mulțimile care apar frecvent. În cea mai mare parte, cercetările anterioare au urmat aceste direcții și le-au extins în diferite direcții.
De la apariția algoritmului Apriori, acest algoritm a fost cel mai frecvent utilizat în primul pas. Multe îmbunătățiri, de exemplu, în ceea ce privește viteza și scalabilitatea, vizează îmbunătățirea algoritmului Apriori, corectarea proprietății sale eronate de a genera prea mulți candidați pentru cele mai comune seturi de elemente. Apriori generează seturi de articole folosind doar seturile de articole mari găsite în pasul anterior, fără a reexamina tranzacțiile. Algoritmul modificat AprioriTid îmbunătățește Apriori folosind baza de date doar la prima trecere. Calculele din etapele următoare folosesc doar datele generate în prima trecere, care este mult mai mică decât baza de date inițială. Acest lucru duce la câștiguri extraordinare de productivitate. O versiune îmbunătățită suplimentară a algoritmului, numită AprioriHybrid, poate fi obținută prin utilizarea Apriori la primele treceri, iar apoi, la trecerile ulterioare, atunci când seturile candidate k-lea pot fi deja alocate în întregime în memoria computerului, treceți la AprioriTid.
Eforturile ulterioare de îmbunătățire a algoritmului Apriori sunt legate de paralelizarea algoritmului (Distribuția numărului, Distribuția datelor, Distribuția candidaților etc.), scalarea acestuia (Distribuție inteligentă a datelor, Distribuție hibridă), introducerea de noi structuri de date, precum arbori. de elemente care apar frecvent (FP-creștere).
Al doilea pas este în mare parte autentic și interesant. Noile modificări adaugă dimensiunea, calitatea și suportul temporal descrise mai sus regulilor tradiționale ale regulilor booleene. Un algoritm evolutiv este adesea folosit pentru a găsi regulile.
2.2 Algoritmi de rețele neuronale
Rețelele neuronale artificiale au apărut ca urmare a aplicării unui aparat matematic la studiul funcționării sistemului nervos uman pentru a-l reproduce. Și anume: capacitatea sistemului nervos de a învăța și de a corecta erorile, care ar trebui să facă posibilă simularea, deși destul de grosolană, a activității creierului uman. Principala parte structurală și funcțională a rețelei neuronale este neuronul formal, prezentat în Fig. 1, unde x0, x1, ..., xn sunt componentele vectorului semnalelor de intrare, w0, w1, ..., wn sunt valorile greutăților semnalelor de intrare ale neuronului și y este semnalul de ieșire al neuronului.
Orez. 1. Neuron formal: sinapse (1), sumator (2), traductor (3).
Un neuron formal este format din 3 tipuri de elemente: sinapse, sumator și traductor. O sinapsă caracterizează puterea conexiunii dintre doi neuroni.
Adunatorul adaugă semnalele de intrare pre-multiplicate cu greutățile corespunzătoare. Convertorul implementează funcția unui singur argument - ieșirea sumatorului. Această funcție se numește funcția de activare sau funcția de transfer a neuronului.
Neuronii formali descriși mai sus pot fi combinați în așa fel încât semnalele de ieșire ale unor neuroni să fie introduse către alții. Setul rezultat de neuroni interconectați se numește rețele neuronale artificiale (ANN) sau, pe scurt, rețele neuronale.
Există trei tipuri generale de neuroni, în funcție de poziția lor în rețeaua neuronală:
Neuroni de intrare, care primesc semnale de intrare. Astfel de neuroni, neuroni, de regulă, au o singură intrare cu o unitate de greutate, nu există nicio părtinire, iar valoarea ieșirii neuronului este egală cu semnalul de intrare;
Neuroni de ieșire (noduri de ieșire), ale căror valori de ieșire reprezintă semnalele de ieșire rezultate ale rețelei neuronale;
Neuronii ascunși, care nu au conexiuni directe cu semnalele de intrare, în timp ce valorile semnalelor de ieșire ale neuronilor ascunși nu sunt semnale de ieșire ale ANN.
În funcție de structura conexiunilor interneuronale, se disting două clase de ANN:
ANN-uri de propagare directă, în care semnalul se propagă numai de la neuronii de intrare la neuronii de ieșire.
ANN recurent - ANN cu feedback. În astfel de ANN-uri, semnalele pot fi transmise între orice neuroni, indiferent de locația lor în ANN.
Există două abordări generale pentru predarea ANN:
Învățarea cu un profesor.
Învățați fără profesor.
Învățarea supravegheată implică utilizarea unui set predefinit de exemple de predare. Fiecare exemplu conține un vector de semnale de intrare și un vector corespunzător de semnale de ieșire de referință, care depind de sarcina la îndemână. Acest set se numește set de antrenament sau set de antrenament. Antrenamentul rețelei neuronale vizează o astfel de modificare a greutăților conexiunilor ANN, în care valoarea semnalelor de ieșire ANN diferă cât mai puțin posibil de valorile necesare ale semnalelor de ieșire pentru un anumit vector de intrare. semnale.
În învățarea nesupravegheată, ponderile conexiunilor sunt ajustate fie ca urmare a competiției dintre neuroni, fie ținând cont de corelarea semnalelor de ieșire ale neuronilor între care există o conexiune. În cazul învățării nesupravegheate, eșantionul de instruire nu este utilizat.
Rețelele neuronale sunt folosite pentru a rezolva o gamă largă de sarcini, cum ar fi planificarea sarcinilor utile pentru navetele spațiale și estimarea ratelor de schimb. Cu toate acestea, ele nu sunt adesea folosite în sistemele de data mining din cauza complexității modelului (cunoștințele înregistrate ca ponderea a câteva sute de conexiuni interneurale sunt complet dincolo de analiza și interpretarea umană) și timpul lung de antrenament pe un eșantion mare de antrenament. Pe de altă parte, rețelele neuronale au astfel de avantaje pentru utilizare în sarcinile de analiză a datelor, cum ar fi rezistența la datele zgomotoase și precizia ridicată.
2.3 Metodele celui mai apropiat vecin și k-cel mai apropiat vecin
Algoritmul de vecin cel mai apropiat și algoritmul de vecin cel mai apropiat (KNN) se bazează pe asemănarea caracteristicilor. Algoritmul cel mai apropiat vecin selectează un obiect dintre toate obiectele cunoscute care este cât mai aproape posibil (folosind metrica distanței dintre obiecte, de exemplu, euclidiană) de un nou obiect necunoscut anterior. Principala problemă a metodei celui mai apropiat vecin este sensibilitatea acesteia la valori aberante din datele de antrenament.
Problema descrisă poate fi evitată prin algoritmul KNN, care distinge între toate observațiile deja k-mai apropiati vecini similari unui obiect nou. Pe baza claselor vecinilor cei mai apropiati se ia o decizie cu privire la noul obiect. O sarcină importantă a acestui algoritm este de a selecta coeficientul k - numărul de înregistrări care vor fi considerate similare. O modificare a algoritmului, în care contribuția unui vecin este proporțională cu distanța până la noul obiect (metoda vecinilor cei mai apropiați ponderați k) permite obținerea unei mai mari precizii de clasificare. Metoda k vecini cei mai apropiați ne permite, de asemenea, să estimăm acuratețea prognozei. De exemplu, toți k vecini cei mai apropiați au aceeași clasă, atunci probabilitatea ca obiectul verificat să aibă aceeași clasă este foarte mare.
Printre caracteristicile algoritmului, merită remarcată rezistența la izbucnirile anormale, deoarece probabilitatea ca o astfel de înregistrare să se încadreze în numărul de vecini k-cel mai apropiat este mică. Dacă s-a întâmplat acest lucru, atunci influența asupra votării (în special ponderată) (pentru k> 2) este, de asemenea, probabil să fie nesemnificativă și, prin urmare, influența asupra rezultatului clasificării va fi, de asemenea, mică. De asemenea, avantajele sunt implementarea simplă, ușurința de interpretare a rezultatului algoritmului, posibilitatea de modificare a algoritmului prin utilizarea celor mai potrivite funcții de combinare și metrici, ceea ce vă permite să ajustați algoritmul pentru o anumită sarcină. Algoritmul KNN are și o serie de dezavantaje. În primul rând, setul de date utilizat pentru algoritm trebuie să fie reprezentativ. În al doilea rând, modelul nu poate fi separat de date: toate exemplele trebuie folosite pentru a clasifica un nou exemplu. Această caracteristică limitează sever utilizarea algoritmului.
2.4 Arbori de decizie
Prin termenul „arbori de decizie” se înțelege o familie de algoritmi bazați pe reprezentarea regulilor de clasificare într-o structură ierarhică, secvenţială. Aceasta este cea mai populară clasă de algoritmi pentru rezolvarea problemelor de data mining.
O familie de algoritmi pentru construirea arborilor de decizie face posibilă prezicerea valorii unui parametru pentru un caz dat pe baza unei cantități mari de date despre alte cazuri similare. De obicei, algoritmii din această familie sunt utilizați pentru a rezolva probleme care permit împărțirea tuturor datelor sursă în mai multe grupuri discrete.
Când algoritmii pentru construirea arborilor de decizie sunt aplicați unui set de date de intrare, rezultatul este afișat sub forma unui arbore. Astfel de algoritmi permit mai multe niveluri ale unei astfel de diviziuni, împărțind grupurile rezultate (ramuri de copac) în altele mai mici pe baza altor caracteristici. Împărțirea continuă până când valorile care se presupune a fi prezise devin aceleași (sau, în cazul unei valori continue a parametrului prezis, se închid) pentru toate grupurile obținute (frunzele arborelui). Aceste valori sunt folosite pentru a face predicții bazate pe acest model.
Funcționarea algoritmilor de construire a arborilor de decizie se bazează pe aplicarea metodelor de regresie și analiză a corelației. Unul dintre cei mai populari algoritmi din această familie este CART (Classification and Regression Trees), bazat pe împărțirea datelor dintr-o ramură de arbore în două ramuri copil; în acest caz, împărțirea ulterioară a uneia sau alteia ramuri depinde de cât de mult din datele inițiale sunt descrise de această ramură. Câțiva alți algoritmi similari vă permit să împărțiți o ramură în mai multe ramuri copil. În acest caz, împărțirea se face pe baza celui mai mare coeficient de corelație pentru ramura de date descrisă între parametrul în funcție de care are loc împărțirea și parametrul care trebuie prezis în viitor.
Popularitatea abordării este asociată cu claritatea și claritatea. Dar arborii de decizie sunt în mod fundamental incapabili să găsească regulile „cele mai bune” (cele mai complete și mai precise) în date. Ei implementează principiul naiv al vizualizării secvențiale a caracteristicilor și găsesc de fapt părți ale tiparelor reale, creând doar iluzia unei concluzii logice.
2.5 Algoritmi de grupare
Clustering este sarcina de a descompune un set de obiecte în grupuri numite clustere. Principala diferență între grupare și clasificare este că lista de grupuri nu este clar specificată și este determinată în timpul funcționării algoritmului.
Aplicarea analizei cluster în general se reduce la următoarele etape:
· Selectarea unui eșantion de obiecte pentru grupare;
· Determinarea setului de variabile prin care vor fi evaluate obiectele din esantion. Dacă este necesar, normalizați valorile variabilelor;
· Calculul valorilor măsurătorii asemănării dintre obiecte;
· Aplicarea metodei analizei cluster pentru a crea grupuri de obiecte similare (clusters);
· Prezentarea rezultatelor analizei.
După obținerea și analizarea rezultatelor, este posibil să se ajusteze metrica selectată și metoda de grupare până la obținerea rezultatului optim.
Printre algoritmii de grupare se disting grupurile ierarhice și plate. Algoritmii ierarhici (numiți și algoritmi de taxonomie) construiesc nu o partiție a unui eșantion în grupuri disjunse, ci un sistem de partiții imbricate. Astfel, rezultatul algoritmului este un arbore de clustere, a cărui rădăcină este întregul eșantion, iar frunzele sunt cele mai mici clustere. Algoritmii plat construiesc o partiție de obiecte în grupuri disjunse.
O altă clasificare a algoritmilor de grupare este în algoritmi clari și neclari. Algoritmi clari (sau care nu se suprapun) atribuie un număr de cluster fiecărui obiect eșantion, adică fiecare obiect aparține unui singur cluster. Algoritmii fuzzy (sau suprapuneri) asociază fiecare obiect cu un set de valori reale care arată gradul de relație a obiectului cu clusterele. Astfel, fiecare obiect aparține fiecărui grup cu o anumită probabilitate.
Printre algoritmii de grupare ierarhică, există două tipuri principale: algoritmi de jos în sus și de sus în jos. Algoritmii de sus în jos funcționează pe principiul de sus în jos: mai întâi, toate obiectele sunt plasate într-un singur grup, care este apoi împărțit în grupuri din ce în ce mai mici. Algoritmii de jos în sus sunt mai obișnuiți, care la începutul lucrului plasează fiecare obiect într-un grup separat și apoi combină grupurile în altele din ce în ce mai mari până când toate obiectele din eșantion sunt conținute într-un singur grup. Astfel, se construiește un sistem de partiții imbricate. Rezultatele unor astfel de algoritmi sunt de obicei prezentate sub forma unui arbore.
Dezavantajul algoritmilor ierarhici este sistemul de partiții complete, care poate fi redundant în contextul problemei care se rezolvă.
Luați în considerare acum algoritmii plati. Cei mai simpli dintre această clasă sunt algoritmii de eroare la pătrat. Problema grupării pentru acești algoritmi poate fi considerată ca construirea unei partiții optime a obiectelor în grupuri. În acest caz, optimitatea poate fi definită ca cerința de a minimiza eroarea pătratică medie a partiției:
 ,
,
Unde c j - „centrul de masă” al clusterului j(punct cu valori medii ale caracteristicilor pentru un anumit cluster).
Cel mai comun algoritm din această categorie este metoda k-means. Acest algoritm construiește un număr dat de clustere situate cât mai departe posibil. Funcționarea algoritmului este împărțită în mai multe etape:
Alege la întâmplare k puncte, care sunt „centrele de masă” inițiale ale clusterelor.
2. Atribuiți fiecare obiect grupului cu cel mai apropiat „centru de masă”.
Dacă criteriul de oprire a algoritmului nu este îndeplinit, reveniți la punctul 2.
Ca criteriu de oprire a funcționării algoritmului, este de obicei aleasă modificarea minimă a erorii pătratice medii. De asemenea, este posibil să opriți funcționarea algoritmului dacă la pasul 2 nu au existat obiecte mutate din cluster în cluster. Dezavantajele acestui algoritm includ necesitatea de a specifica numărul de clustere pentru partiționare.
Cel mai popular algoritm de grupare fuzzy este algoritmul c-means. Este o modificare a metodei k-means. Etapele algoritmului:
1. Alegeți o partiție neclară inițială n obiecte pe k clustere prin alegerea matricei de membru U mărimea n x k.
2. Folosind matricea U, găsiți valoarea criteriului de eroare fuzzy:
 ,
,
Unde c k - „centrul de masă” al unui cluster fuzzy k:
3. Regrupați obiectele pentru a scădea această valoare a criteriului de eroare fuzzy.
4. Reveniți la pasul 2 până când matricea se schimbă U nu va deveni nesemnificativ.
Este posibil ca acest algoritm să nu funcționeze dacă numărul de clustere este necunoscut în prealabil sau este necesar să atribuiți fără ambiguitate fiecare obiect unui cluster.
Următorul grup de algoritmi sunt algoritmi bazați pe teoria grafurilor. Esența unor astfel de algoritmi este aceea că o selecție de obiecte este reprezentată sub forma unui grafic G = (V, E), ale căror vârfuri corespund obiectelor, iar marginile au o pondere egală cu „distanța” dintre obiecte. Avantajele algoritmilor de grupare grafică sunt claritatea, relativă ușurință de implementare și posibilitatea de a face diverse îmbunătățiri pe baza considerațiilor geometrice. Algoritmii principali sunt algoritmul pentru extragerea componentelor conectate, algoritmul pentru construirea arborelui de acoperire minim și algoritmul de grupare strat cu strat.
Pentru a selecta un parametru R de obicei este reprezentată grafic o histogramă a distribuțiilor de distanțe pe perechi. În problemele cu o structură a grupului de date bine pronunțată, histograma va avea două vârfuri - unul corespunde distanțelor intra-cluster, al doilea - distanțelor inter-cluster. Parametru R este selectat din zona minimului dintre aceste vârfuri. În același timp, este destul de dificil să controlezi numărul de clustere folosind pragul de distanță.
Algoritmul arborelui de întindere minimă construiește mai întâi arborele de întindere minim pe grafic și apoi elimină secvențial muchiile cu cea mai mare greutate. Algoritmul de grupare strat cu strat se bazează pe selecția componentelor conectate ale graficului la un anumit nivel de distanțe între obiecte (vârfurile). Nivelul distanței este stabilit de pragul distanței c... De exemplu, dacă distanța dintre obiecte, atunci.
Algoritmul de grupare strat cu strat formează o secvență de subgrafe grafice G care reflectă relațiile ierarhice dintre clustere:
![]() ,
,
Unde G t = (V, E t )
- grafic la nivel cu t, ![]() ,
,
cu t este al-lea prag al distanței, m este numărul de niveluri ierarhice,
G 0 = (V, o), o este setul gol de muchii ale graficului obținut pentru t 0 = 1,
G m = G, adică un grafic al obiectelor fără restricții privind distanța (lungimea marginilor graficului), deoarece t m = 1.
Prin modificarea pragurilor de distanță ( cu 0 , …, cu m), unde 0 = cu 0 < cu 1 < …< cu m = 1, este posibil să se controleze adâncimea ierarhiei clusterelor rezultate. Astfel, algoritmul de grupare strat cu strat este capabil să creeze atât partiționare plană, cât și ierarhică a datelor.
Clustering vă permite să atingeți următoarele obiective:
· Îmbunătățește înțelegerea datelor prin identificarea grupurilor structurale. Împărțirea eșantionului în grupuri de obiecte similare face posibilă simplificarea ulterioară a procesării datelor și luării deciziilor prin aplicarea propriei metode de analiză fiecărui cluster;
· Vă permite să stocați în mod compact datele. Pentru a face acest lucru, în loc să stocați întregul eșantion, puteți lăsa o observație tipică din fiecare grup;
· Detectarea de noi obiecte atipice care nu au fost incluse în niciun cluster.
De obicei, gruparea este folosită ca ajutor pentru analiza datelor.
2.6 Algoritmi genetici
Algoritmii genetici se numără printre metodele universale de optimizare care permit rezolvarea unor probleme de diferite tipuri (combinatorii, probleme generale cu și fără restricții) și de diferite grade de complexitate. În același timp, algoritmii genetici se caracterizează prin posibilitatea căutării atât cu un singur criteriu, cât și cu mai multe criterii într-un spațiu mare, al cărui peisaj nu este neted.
Acest grup de metode folosește un proces iterativ de evoluție a secvenței generațiilor de modele, incluzând operațiile de selecție, mutație și încrucișare. La începutul algoritmului, populația se formează aleatoriu. Pentru a evalua calitatea soluțiilor codificate, se utilizează funcția de fitness, care este necesară pentru a calcula fitness-ul fiecărui individ. Conform rezultatelor evaluării indivizilor, cei mai adaptați dintre ei sunt selectați pentru încrucișare. Ca rezultat al încrucișării unor indivizi selectați prin utilizarea operatorului de încrucișare genetică, se creează descendenți, a căror informație genetică se formează ca urmare a schimbului de informații cromozomiale între indivizii părinți. Descendenții creați formează o nouă populație, iar unii dintre urmași mută, ceea ce se exprimă într-o schimbare aleatorie a genotipurilor lor. Etapa care include secvența „Estimarea populației” – „Selecție” – „Încrucișare” – „Mutație” se numește generație. Evoluția populației constă dintr-o succesiune de astfel de generații.
Se disting următorii algoritmi de selectare a indivizilor pentru încrucișare:
· Panmixia. Ambii indivizi care alcătuiesc perechea parentală sunt selectați aleatoriu din întreaga populație. Orice individ poate deveni membru al mai multor perechi. Această abordare este universală, dar eficiența algoritmului scade odată cu creșterea dimensiunii populației.
· Selectie. Persoanele cu o condiție fizică cel puțin medie pot deveni părinți. Această abordare asigură o convergență mai rapidă a algoritmului.
· Consangvinizare. Metoda se bazează pe formarea unui cuplu pe baza unei relații apropiate. Aici, rudenia este înțeleasă ca distanța dintre membrii populației, atât în sensul distanței geometrice a indivizilor în spațiul parametrilor, cât și al distanței Heming dintre genotipuri. Prin urmare, se face o distincție între consangvinizarea genotipică și cea fenotipică. Primul membru al perechii pentru încrucișare este ales la întâmplare, iar al doilea, cu o probabilitate mai mare, va fi individul cât mai aproape de el. Consangvinizarea poate fi caracterizată prin proprietatea de concentrare a căutării în nodurile locale, ceea ce duce de fapt la împărțirea populației în grupuri locale separate în jurul unor zone ale peisajului suspecte de extremum.
· Outbreeding. Formarea unei perechi pe baza unei relații îndepărtate, pentru cei mai îndepărtați indivizi. Outbreeding are ca scop prevenirea convergenței algoritmului către soluții deja găsite, forțând algoritmul să caute zone noi, neexplorate.
Algoritmi pentru formarea unei noi populații:
· Selectie cu deplasare. Dintre toți indivizii cu aceleași genotipuri, se acordă preferință celor a căror fitness este mai mare. Astfel, sunt atinse două obiective: cele mai bune soluții găsite cu seturi de cromozomi diferite nu se pierd, o diversitate genetică suficientă este menținută constant în populație. Deplasarea formează o nouă populație de indivizi îndepărtați, în loc de grupuri de indivizi în jurul soluției actuale găsite. Această metodă este utilizată pentru sarcini multi-extreme.
· Selecție de elită. Metodele de selecție de elită asigură supraviețuirea celor mai buni membri ai populației. În același timp, unii dintre cei mai buni indivizi trec în generația următoare fără nicio schimbare. Convergența rapidă oferită de selecția de elită poate fi compensată printr-o metodă adecvată de selecție parentală. În acest caz, deseori se folosește îndoirea. Această combinație de „outbreeding – selecție de elită” este una dintre cele mai eficiente.
· Selectarea turneului. Selecția turneelor implementează n turnee pentru a selecta n persoane. Fiecare turneu este construit pe un eșantion de k elemente din populație și selecția celui mai bun individ dintre ele. Cea mai comună selecție de turneu cu k = 2.
Una dintre cele mai populare aplicații ale algoritmilor genetici în domeniul Data Mining este căutarea celui mai optim model (căutarea unui algoritm care se potrivește cu specificul unei anumite zone). Algoritmii genetici sunt utilizați în principal pentru a optimiza topologia și ponderile rețelelor neuronale. Cu toate acestea, este posibil să le folosiți și ca instrument independent.
3. Domenii de aplicare
Tehnologia Data Mining are o gamă cu adevărat largă de aplicații, fiind, de fapt, un set de instrumente universale pentru analiza datelor de orice tip.
Marketing
Unul dintre cele mai timpurii domenii în care s-au aplicat tehnologiile de extragere a datelor a fost marketingul. Sarcina care a început dezvoltarea metodelor de Data Mining se numește analiza coșului de cumpărături.
Această sarcină este de a identifica produsele pe care cumpărătorii doresc să le cumpere împreună. Cunoașterea coșului de cumpărături este necesară pentru campaniile publicitare, formarea de recomandări personale pentru clienți, elaborarea unei strategii de creare a stocurilor de mărfuri și metode de aranjare a acestora în zonele de vânzare.
De asemenea, în marketing, astfel de sarcini sunt rezolvate ca determinarea publicului țintă al unui anumit produs pentru promovarea sa cu mai mult succes; un studiu al tiparelor de timp care ajută companiile să ia decizii privind inventarul; crearea de modele predictive, care să permită întreprinderilor să recunoască natura nevoilor diverselor categorii de clienți cu un anumit comportament; prezicerea loialității clienților, care vă permite să identificați din timp momentul plecării clientului atunci când îi analizați comportamentul și, eventual, să preveniți pierderea unui client valoros.
Industrie
Una dintre direcțiile importante în acest domeniu este monitorizarea și controlul calității, unde folosind instrumente de analiză este posibil să se prezică defecțiunile echipamentelor, apariția defecțiunilor și să se planifice lucrările de reparații. Prevederea popularității anumitor caracteristici și cunoașterea care caracteristici sunt de obicei ordonate împreună ajută la optimizarea producției, orientând-o către nevoile reale ale consumatorilor.
Medicament
În medicină, analiza datelor este, de asemenea, folosită cu destul de mult succes. Un exemplu de sarcini este analiza rezultatelor examinării, diagnosticarea, compararea eficacității metodelor de tratament și a medicamentelor, analiza bolilor și distribuția acestora, identificarea efectelor secundare. Tehnologiile Data Mining, cum ar fi regulile de asociere și modelele secvenţiale, au fost utilizate cu succes pentru a identifica legăturile dintre consumul de medicamente și efectele secundare.
Genetica moleculară și inginerie genetică
Poate că sarcina cea mai acută și în același timp clară de descoperire a tiparelor în datele experimentale este în genetica moleculară și ingineria genetică. Aici este formulat ca o definiție a markerilor, care sunt înțeleși ca coduri genetice care controlează anumite caracteristici fenotipice ale unui organism viu. Astfel de coduri pot conține sute, mii sau mai multe elemente înrudite. Rezultatul analizei analitice a datelor este, de asemenea, relația dintre modificările secvenței ADN-ului unei persoane și riscul de a dezvolta diverse boli, descoperite de oamenii de știință genetician.
Chimie aplicată
Metodele Data Mining sunt folosite și în domeniul chimiei aplicate. Aici se pune adesea întrebarea de a elucida caracteristicile structurii chimice a anumitor compuși care le determină proprietățile. Această problemă este deosebit de relevantă în analiza compușilor chimici complecși, a căror descriere include sute și mii de elemente structurale și legăturile lor.
Combaterea crimei
Instrumentele de data mining au fost folosite relativ recent în asigurarea securității, totuși, s-au obținut deja rezultate practice care confirmă eficiența extragerii de date în acest domeniu. Oamenii de știință elvețieni au dezvoltat un sistem de analiză a activității de protest pentru a prezice incidente viitoare și un sistem de urmărire a amenințărilor cibernetice emergente și a acțiunilor hackerilor din lume. Ultimul sistem permite prezicerea amenințărilor cibernetice și a altor riscuri de securitate a informațiilor. De asemenea, metodele Data Mining sunt folosite cu succes pentru a detecta frauda cu cardul de credit. Analizând tranzacțiile anterioare care ulterior s-au dovedit a fi frauduloase, banca identifică unele stereotipuri ale unei astfel de fraude.
Alte aplicații
· Analiza de risc. De exemplu, prin identificarea combinațiilor de factori asociați cu daunele plătite, asigurătorii își pot reduce pierderile din răspundere. Există un caz binecunoscut când o mare companie de asigurări din Statele Unite a descoperit că sumele plătite pe declarațiile persoanelor căsătorite erau de două ori mai mari decât suma plătită pe declarațiile persoanelor singure. Compania a răspuns la aceste noi cunoștințe prin revizuirea politicii sale generale de reduceri pentru clienții de familie.
· Meteorologie. Sunt folosite prognoza meteo folosind rețele neuronale, în special hărți Kohonen auto-organizate.
· Politica de personal. Instrumentele de analiză ajută serviciile de HR să selecteze cei mai de succes candidați pe baza analizei datelor lor de CV, pentru a modela caracteristicile angajaților ideali pentru o anumită poziție.
4. Producători de instrumente de data mining
Instrumentele de extragere a datelor aparțin în mod tradițional unor produse software scumpe. Prin urmare, până de curând, principalii consumatori ai acestei tehnologii au fost băncile, companiile financiare și de asigurări, marile întreprinderi comerciale, iar principalele sarcini care necesitau utilizarea Data Mining au fost evaluarea riscurilor de credit și de asigurare și dezvoltarea politicii de marketing, a planurilor tarifare. și alte principii de lucru cu clienții. În ultimii ani, situația a suferit anumite schimbări: pe piața de software au apărut instrumente de Data Mining relativ ieftine și chiar sisteme de distribuție gratuite, care au făcut această tehnologie disponibilă pentru întreprinderile mici și mijlocii.
Printre instrumentele plătite și sistemele de analiză a datelor, liderii sunt SAS Institute (SAS Enterprise Miner), SPSS (SPSS, Clementine) și StatSoft (STATISTICA Data Miner). Destul de cunoscute sunt soluțiile Angoss (Angoss KnowledgeSTUDIO), IBM (IBM SPSS Modeler), Microsoft (Microsoft Analysis Services) și (Oracle) Oracle Data Mining.
Alegerea software-ului gratuit este, de asemenea, variată. Există atât instrumente universale de analiză, precum JHepWork, KNIME, Orange, RapidMiner, cât și instrumente specializate, de exemplu, Carrot2 - un cadru pentru gruparea datelor de text și a rezultatelor căutării, Chemicalize.org - o soluție în domeniul chimiei aplicate, NLTK (Natural Language Toolkit) instrument de procesare a limbajului natural.
5. Critica metodelor
Rezultatele Data Mining depind în mare măsură de nivelul de pregătire a datelor și nu de „capacitățile miraculoase” ale unor algoritmi sau set de algoritmi. Aproximativ 75% din munca despre Data Mining constă în colectarea de date, care se face chiar înainte de utilizarea instrumentelor de analiză. Utilizarea analfabetă a instrumentelor va duce la o risipă fără sens a potențialului companiei și, uneori, la milioane de dolari.
Potrivit Herb Edelstein, un expert de renume mondial în Data Mining, Data Warehousing și CRM: „Un studiu recent realizat de Two Crows a arătat că Data Mining este încă în stadiile incipiente. Multe organizații sunt interesate de această tehnologie, dar doar câteva implementează în mod activ astfel de proiecte. Am reușit să aflăm un alt punct important: procesul de implementare a Data Mining-ului în practică se dovedește a fi mai complicat decât se aștepta.Echipele au fost duse de mitul că instrumentele de Data Mining sunt ușor de folosit. Se presupune că este suficient să rulați un astfel de instrument pe o bază de date terabyte și vor apărea imediat informații utile. De fapt, un proiect de Data Mining de succes necesită înțelegerea esenței activității, cunoașterea datelor și instrumentelor, precum și a procesului de analiză a datelor.” Astfel, înainte de a utiliza tehnologia Data Mining, este necesar să se analizeze cu atenție limitările impuse de metode și problemele critice asociate cu aceasta, precum și să se evalueze sobru capacitățile tehnologiei. Problemele critice includ următoarele:
1. Tehnologia nu poate oferi răspunsuri la întrebările care nu au fost puse. Nu poate înlocui analistul, ci îi oferă doar un instrument puternic pentru a-și facilita și îmbunătăți munca.
2. Complexitatea dezvoltării și funcționării aplicației Data Mining.
Întrucât această tehnologie este un domeniu multidisciplinar, pentru a dezvolta o aplicație care să includă Data Mining, este necesar să se implice specialiști din diferite domenii, precum și să se asigure interacțiunea lor de înaltă calitate.
3. Calificările utilizatorului.
Diferite instrumente de Data Mining au grade diferite de ușurință pentru utilizator și necesită anumite calificări ale utilizatorului. Prin urmare, software-ul trebuie să corespundă nivelului de pregătire al utilizatorului. Utilizarea Data Mining ar trebui să fie indisolubil legată de îmbunătățirea calificărilor utilizatorului. Cu toate acestea, în prezent există puțini specialiști în Data Mining care sunt bine versați în procesele de afaceri.
4. Extragerea de informații utile este imposibilă fără o bună înțelegere a esenței datelor.
Sunt necesare selecția atentă a modelului și interpretarea dependențelor sau modelelor care sunt găsite. Prin urmare, lucrul cu astfel de instrumente necesită o colaborare strânsă între expertul în domeniu și specialistul în instrumentele Data Mining. Modelele permanente trebuie integrate inteligent în procesele de afaceri pentru a putea evalua și actualiza modelele. Recent, sistemele Data Mining au fost livrate ca parte a tehnologiei de depozit de date.
5. Complexitatea pregătirii datelor.
O analiză de succes necesită preprocesare de înaltă calitate a datelor. Potrivit analiștilor și utilizatorilor bazei de date, procesul de preprocesare poate dura până la 80% din întregul proces de Data Mining.
Astfel, pentru ca tehnologia să funcționeze de la sine, va fi nevoie de mult efort și timp, care sunt cheltuiți pentru analiza preliminară a datelor, selectarea modelului și corectarea acestuia.
6. Un procent mare de rezultate false, nesigure sau inutile.
Cu ajutorul tehnologiilor Data Mining, puteți găsi informații cu adevărat foarte valoroase care vă pot oferi un avantaj semnificativ în planificarea, managementul și luarea deciziilor ulterioare. Cu toate acestea, rezultatele obținute folosind metodele Data Mining conțin destul de des concluzii false și lipsite de sens. Mulți experți susțin că instrumentele Data Mining pot produce o cantitate imensă de rezultate nesigure din punct de vedere statistic. Pentru a reduce procentul de astfel de rezultate, este necesar să se verifice adecvarea modelelor obținute pe datele de testare. Cu toate acestea, este imposibil să evitați complet concluziile false.
7. Cost ridicat.
Un produs software de calitate este rezultatul unui efort semnificativ din partea dezvoltatorului. Prin urmare, software-ul Data Mining este în mod tradițional considerat un produs software scump.
8. Disponibilitatea unor date reprezentative suficiente.
Instrumentele Data Mining, spre deosebire de cele statistice, teoretic nu necesită o cantitate strict definită de date istorice. Această caracteristică poate determina detectarea modelelor inexacte, false și, ca urmare, adoptarea unor decizii incorecte pe baza acestora. Este necesar să se controleze semnificația statistică a cunoștințelor descoperite.
algoritmul rețelei neuronale de grupare a minării de date
Concluzie
Se face o scurtă descriere a sferelor de aplicare și se fac critici la adresa tehnologiei Data Mining și opiniile experților în acest domeniu.
Listăliteratură
1. Han și Micheline Kamber. Data Mining: Concepte și tehnici. A doua editie. - Universitatea din Illinois la Urbana-Champaign
Berry, Michael J. A. Tehnici de extragere a datelor: pentru marketing, vânzări și managementul relațiilor cu clienții - Ed. a II-a.
Siu Nin Lam. Descoperirea regulilor de asociere în data mining. - Departamentul de Informatică Universitatea din Illinois la Urbana-Champaign
Trimiteți-vă munca bună în baza de cunoștințe este simplu. Utilizați formularul de mai jos
Studenții, studenții absolvenți, tinerii oameni de știință care folosesc baza de cunoștințe în studiile și munca lor vă vor fi foarte recunoscători.
Documente similare
- analiza traiectoriilor clienților de la vizitarea unui site web până la achiziționarea de bunuri
- evaluarea eficienței serviciului, analiza defecțiunilor din cauza lipsei de bunuri
- legarea de bunuri care sunt interesante pentru vizitatori
- analiza coșului de cumpărături;
- crearea de modele predictiveși modele de clasificare a cumpărătorilor și bunurilor achiziționate;
- crearea profilurilor clienților;
- CRM, evaluarea fidelitatii clientilor diferitelor categorii, planificarea programelor de fidelizare;
- cercetarea serii temporaleși dependențe de timp, evidențierea factorilor sezonieri, evaluarea eficienței promoțiilor pe o gamă largă de date reale.
- clasificarea clienților pe baza caracteristicilor cheie ale apelurilor (frecvență, durată etc.), frecvență SMS;
- identificarea loialității clienților;
- definirea fraudei etc.
- analiza de risc... Prin identificarea combinațiilor de factori asociați cu daunele plătite, asigurătorii își pot reduce pierderile din răspundere. Există un caz cunoscut când o companie de asigurări a constatat că sumele plătite pe pretențiile persoanelor căsătorite erau de două ori mai mari decât suma plătită pe pretențiile persoanelor singure. Compania a răspuns prin revizuirea politicii sale de reduceri pentru familii.
- detectarea fraudei... Companiile de asigurări pot reduce frauda căutând stereotipuri specifice în reclamații care caracterizează relația dintre avocați, medici și reclamanți.
Clasificarea sarcinilor DataMining. Crearea de rapoarte si totaluri. Caracteristicile Data Miner în Statistica. Problemă de clasificare, grupare și regresie. Instrumente de analiză Statistica Data Miner. Esența problemei este căutarea regulilor de asociere. Analiza predictorilor de supraviețuire.
lucrare de termen, adăugată 19.05.2011
Descrierea funcționalității tehnologiei Data Mining ca proces de detectare a datelor necunoscute. Studiul sistemelor de inferență a regulilor asociative și a mecanismelor algoritmilor de rețele neuronale. Descrierea algoritmilor de clustering și a domeniilor de aplicare ale Data Mining.
test, adaugat 14.06.2013
Bazele grupării. Folosind data mining ca o modalitate de „descoperire a cunoștințelor în baze de date”. Alegerea algoritmilor de grupare. Preluarea datelor din baza de date de stocare a atelierului de la distanță. Clustering studenți și sarcini.
lucrare de termen adăugată la 07.10.2017
Exploatarea datelor, istoricul dezvoltării minării datelor și descoperirea cunoștințelor. Elemente tehnologice și metode de data mining. Pași în descoperirea cunoștințelor. Detectarea schimbărilor și a abaterilor. Discipline înrudite, regăsirea informațiilor și extragerea textului.
raport adaugat la 16.06.2012
Analiza problemelor apărute în urma aplicării metodelor și algoritmilor de clustering. Algoritmi de bază pentru clustering. Software-ul RapidMiner ca mediu pentru învățarea automată și analiza datelor. Evaluarea calității clusterizării folosind metodele Data Mining.
lucrare de termen, adăugată 22.10.2012
Îmbunătățirea tehnologiilor de înregistrare și stocare a datelor. Specificitatea cerințelor moderne pentru prelucrarea datelor informaționale. Conceptul de modele care reflectă fragmente de relații multidimensionale în date în centrul tehnologiei moderne de data mining.
test, adaugat 09.02.2010
Analiza utilizării rețelelor neuronale pentru prezicerea situației și luarea deciziilor la bursă folosind pachetul software de modelare a rețelelor neuronale Trajan 3.0. Conversia datelor primare, tabele. Evaluarea programului ergonomic.
teză, adăugată 27.06.2011
Dificultăți în utilizarea algoritmilor evolutivi. Construirea sistemelor de calcul bazate pe principiile selecției naturale. Dezavantajele algoritmilor genetici. Exemple de algoritmi evolutivi. Direcții și secțiuni ale modelării evolutive.
Vă urăm bun venit pe Portalul Data Mining - un portal unic dedicat metodelor moderne de Data Mining.
Tehnologiile Data Mining sunt un instrument puternic de business intelligence modern și data mining pentru descoperirea tiparelor ascunse și construirea modelelor predictive. Miningul de date sau extragerea cunoștințelor se bazează nu pe raționamente speculative, ci pe date reale.

Orez. 1. Schema aplicației Data Mining
Definirea problemei - Enunțarea problemei: clasificarea datelor, segmentarea, construirea modelelor predictive, prognoză.
Colectarea și pregătirea datelor - Colectarea și pregătirea datelor, curățarea, verificarea, ștergerea înregistrărilor duplicate.
Construire model - Construire model, evaluarea preciziei.
Knowledge Deployment - Aplicarea unui model pentru a rezolva o problemă dată.
Data Mining este folosit pentru a implementa proiecte analitice la scară largă în afaceri, marketing, internet, telecomunicații, industrie, geologie, medicină, produse farmaceutice și alte domenii.
Data Mining vă permite să începeți procesul de găsire a corelațiilor și conexiunilor semnificative ca urmare a verificării unei game uriașe de date folosind metode moderne de recunoaștere a modelelor și utilizarea tehnologiilor analitice unice, inclusiv arbori de decizie și clasificări, clustering, metode de rețele neuronale , si altii.
Un utilizator care a descoperit pentru prima dată tehnologia data mining este uimit de abundența de metode și algoritmi eficienți care permit găsirea unor abordări pentru rezolvarea problemelor dificile asociate cu analiza unor cantități mari de date.
În general, Data Mining poate fi caracterizată ca o tehnologie concepută pentru a căuta în cantități mari de date. neevident, obiectiv si practic util modele.
Data Mining se bazează pe metode și algoritmi eficienți dezvoltați pentru analiza datelor nestructurate de volum și dimensiune mare.
Punctul cheie este că datele de volum mare, cu dimensiuni mari par să fie lipsite de structură și conexiuni. Scopul tehnologiei data mining este de a identifica aceste structuri și de a găsi modele în care, la prima vedere, domnește haosul și arbitrariul.
Iată un studiu de caz actual al aplicațiilor de extragere a datelor în industria farmaceutică și a medicamentelor.
Interacțiunile medicamentoase sunt o problemă în creștere cu care se confruntă asistența medicală modernă.
De-a lungul timpului, numărul de medicamente prescrise (eliberate fără prescripție medicală și tot felul de suplimente) crește, ceea ce face din ce în ce mai probabil ca interacțiunile medicamentoase să provoace reacții adverse grave de care medicii și pacienții nu sunt conștienți.
Acest domeniu aparține cercetării postclinice, când un medicament a fost deja lansat pe piață și este utilizat intens.
Studiile clinice se referă la evaluarea eficacității unui medicament, dar nu iau în considerare interacțiunile acestui medicament cu alte medicamente de pe piață.
Cercetătorii de la Universitatea Stanford din California au examinat baza de date a Food and Drug Administration (FDA) privind efectele secundare ale medicamentelor și au descoperit că două medicamente utilizate în mod obișnuit - paroxetina antidepresivă și pravastatina, utilizate pentru a scădea nivelul colesterolului - cresc riscul de a dezvolta diabet dacă sunt utilizate împreună.
Un studiu care a efectuat o analiză similară bazată pe datele FDA a identificat 47 de interacțiuni adverse necunoscute anterior.
Acest lucru este remarcabil, cu avertismentul că multe dintre efectele negative raportate de pacienți rămân nerecunoscute. Aici căutarea online poate face tot posibilul.
Cursuri viitoare de Data Mining la StatSoft Data Analysis Academy în 2020
Începem cunoștințele noastre cu Data Mining folosind minunatele videoclipuri ale Academiei de Analiză a Datelor.
Asigurați-vă că urmăriți videoclipurile noastre și veți înțelege ce este Data Mining!
Video 1. Ce este data mining?
Video 2. Prezentare generală a metodelor de extragere a datelor: arbori de decizie, modele predictive generalizate, clustering și multe altele
JavaScript este dezactivat în browserul dvs
Înainte de a începe un proiect de cercetare, trebuie să organizăm procesul de obținere a datelor din surse externe, acum vom arăta cum se face acest lucru.
Videoclipul vă va prezenta tehnologia unică STATISTICA Procesare la locul de date și conexiune de extragere a datelor cu date reale.
Video 3. Ordinea interacțiunii cu bazele de date: interfață grafică pentru construirea de interogări SQL Tehnologie de procesare a bazelor de date la loc
JavaScript este dezactivat în browserul dvs
Acum ne uităm la tehnologiile interactive de foraj care sunt eficiente în analiza datelor de explorare. Termenul de foraj în sine reflectă legătura dintre tehnologia Data Mining și explorarea geologică.
Video 4. Foraj interactiv: Tehnici de explorare și grafice pentru explorarea interactivă a datelor
JavaScript este dezactivat în browserul dvs
Acum ne vom familiariza cu analiza asociațiilor (reguli de asociere), acești algoritmi vă permit să găsiți relații care există în date reale. Punctul cheie este eficiența algoritmilor pe cantități mari de date.
Rezultatul algoritmilor de analiză a legăturilor, de exemplu, algoritmul Apriori, este găsirea regulilor de legătură pentru obiectele studiate cu o fiabilitate dată, de exemplu, 80%.
În geologie, acești algoritmi pot fi utilizați în analiza exploratorie a mineralelor, de exemplu, modul în care caracteristica A este asociată cu caracteristicile B și C.
Puteți găsi exemple specifice de astfel de soluții urmând linkurile noastre:
În retail, algoritmul Apriori sau modificările acestora vă permit să investigați relația dintre diferite produse, de exemplu, atunci când vindeți parfumerie (parfum - lac - rimel etc.) sau produse de diferite mărci.
Analiza celor mai interesante secțiuni de pe site poate fi efectuată eficient și folosind regulile asociațiilor.
Așa că, urmăriți următorul nostru videoclip.
Video 5. Regulile de asociere
JavaScript este dezactivat în browserul dvs
Să dăm exemple de aplicație Data Mining în anumite zone.
Comerț online:
Comerț cu amănuntul: analizați informațiile despre clienți pe baza cardurilor de credit, cardurilor de reducere și multe altele.
Sarcini tipice de retail rezolvate de instrumentele Data Mining:
Sectorul telecomunicațiilor deschide oportunități nelimitate pentru aplicarea metodelor de data mining, precum și a tehnologiilor moderne de big data:
Asigurare:
Aplicația practică a extragerii de date și rezolvarea unor probleme specifice este prezentată în următorul nostru videoclip.
Webinar 1. Webinar „Sarcini practice de extragere a datelor: probleme și soluții”
JavaScript este dezactivat în browserul dvsWebinar 2. Webinar „Data Mining și Text Mining: Exemple de rezolvare a problemelor reale”
JavaScript este dezactivat în browserul dvs
Puteți obține o cunoaștere mai profundă a metodologiei și tehnologiei de extragere a datelor la cursurile StatSoft.