1) Conceptul de index
Index Este un instrument care oferă acces rapid la rândurile tabelelor pe baza valorilor uneia sau mai multor coloane.
Există multă varietate în acest operator, deoarece nu este standardizat, deoarece standardele nu abordează probleme de performanță.
2) Crearea indexurilor
CREAȚI INDEX
PE ()
3) Modificarea și ștergerea indexurilor
Următorul operator este utilizat pentru a controla activitatea indexului:
ALTER INDEX
Pentru a șterge un index, utilizați operatorul:
INDEX DROP
a) Reguli de selectare a tabelelor
1. Se recomandă să se indexeze tabele în care nu sunt selectate mai mult de 5% din rânduri.
2. Tabele de index care nu au duplicate în clauza WHERE din instrucțiunea SELECT.
3. Este imposibil să indexăm tabele actualizate frecvent.
4. Este imposibil să existe tabele de index care nu ocupă mai mult de 2 pagini (pentru Oracle este mai mic de 300 de rânduri), deoarece scanarea completă a acestuia nu durează mai mult.
b) Reguli de selecție a coloanelor
1. Cheile primare și străine sunt adesea folosite pentru alăturarea tabelelor, preluarea datelor și căutarea. Acestea sunt întotdeauna indexuri unice cu utilitate maximă
2. Când folosiți opțiuni de integritate referențială, este întotdeauna necesar un index pe FK.
3. Coloane prin care se realizează deseori sortarea și / sau gruparea datelor.
4. Coloane care sunt căutate frecvent în clauza WHERE a unei instrucțiuni SELECT.
5. Nu creați indexuri pe coloane descriptive lungi.
c) Principiile pentru crearea indexurilor compozite
1. Indicii compuși sunt buni atunci când coloanele individuale au puține valori unice, iar indexul compozit oferă mai multă unicitate.
2. Dacă toate valorile selectate de instrucțiunea SELECT aparțin unui index compus, atunci valorile sunt preluate din index.
3. Creați un index compus dacă clauza WHERE folosește două sau mai multe valori combinate cu operatorul AND.
d) Nu se recomandă crearea
Nu este recomandat să se creeze indexuri pe coloane, inclusiv pe cele compuse, care:
1. Rar utilizat pentru căutarea, combinarea și sortarea rezultatelor interogării.
2. Conțin valori care se schimbă frecvent, ceea ce necesită o actualizare frecventă a indexului, ceea ce încetinește performanța bazei de date.
3. Conține un număr mic de valori unice (mai puțin de 10% m / f) sau numărul predominant de linii cu una sau două valori (orașul de reședință al furnizorului este Moscova).
4. O funcție sau expresie le este aplicată în clauza WHERE și indexul nu funcționează.
e) Nu uita
Ar trebui să vă străduiți să reduceți numărul de indici, deoarece un număr mare dintre ei încetinește rata de actualizare a datelor. Așadar, MS SQL Server recomandă crearea a cel mult 16 indexuri pe tabelă.
De obicei, indexurile sunt create pentru interogări și integritate referențială.
Dacă indicele nu este utilizat pentru interogări, atunci ar trebui renunțat și ar trebui aplicată integritatea referențială folosind declanșatoare.
Se folosesc indexuri pentru a oferi acces rapid la rândurile tabelului DBMS Oracle. Indexurile oferă acces rapid la date în timpul operațiunilor, atunci când este selectat un număr relativ mic de rânduri de tabel.
Deși Oracle permite un număr nelimitat de indici de pe un tabel, indexurile sunt utile doar atunci când sunt utilizate pentru a accelera interogările. În caz contrar, acestea ocupă spațiu și încetinesc performanța serverului atunci când actualizează coloane indexate. Ar trebui să utilizați funcția EXPLAIN PLAN (Planul de execuție și statisticile) pentru a determina modul în care sunt folosiți indici în interogările dvs. Uneori, dacă un index nu este utilizat în mod implicit, puteți utiliza indicii de interogare cu privire la utilizarea indexului.
Creați indexuri după introducerea datelor din tabel
De obicei, inserați sau încărcați date într-un tabel înainte de a crea indexuri. În caz contrar, cheltuielile generale ale indexurilor de actualizare vor încetini operațiunile de introducere sau încărcare. Singura excepție de la această regulă este un indice de cheie în grup. Poate fi creat doar pentru un cluster gol.
Treceți la spațiul de tabel temporar pentru a evita probleme de spațiu liber atunci când creați indexuri
Când se creează un index pe un tabel care conține deja date, Oracle necesită spațiu suplimentar de stocare pentru sortare. Aceasta folosește zona de memorie de sortare alocată creatorului de index (suma alocată pentru fiecare utilizator este stabilită de parametrul de inițializare SORT_AREA_SIZE), în plus, serverul Oracle trebuie să curgă și să schimbe informațiile din segmentele temporare alocate în timpul creării indexului. Dacă indicele este foarte mare, atunci se recomandă să faceți următoarele:
- Creați un nou spațiu de tabel temporar folosind instrucțiunea CREATE TABLESPACE.
- Specificați acest nou spațiu temporar în parametrul TEMPORARY TABLESPACE din instrucțiunea ALTER USER.
- Creați un index cu instrucțiunea CREATE INDEX.
- Distrugeți acest spațiu de tabel cu comanda DROP TABLESPACE. Apoi folosiți instrucțiunea ALTER USER pentru a restabili spațiul de tabel original ca temporar.
Alegeți tabelele și coloanele potrivite pentru indexare
Utilizați următoarele instrucțiuni pentru a determina când să creați un index.
- Creați un index dacă selectați frecvent un număr relativ mic (sub 15%) de rânduri într-un tabel mare. Acest procent depinde foarte mult de viteza relativă a scanării tabelelor și de modul în care sunt grupate datele rândului în cheia index. Cu cât este mai mare viteza de navigare, cu atât este mai mic procentul, cu atât sunt mai grupate datele de rând, cu atât este mai mare procentul.
- Coloanele index utilizate în uniri pentru a îmbunătăți performanța de alăturare mai multe tabele.
- Indexurile sunt create automat pe baza cheii primare și unice.
- Tabelele mici nu trebuie să fie indexate. Dacă observați că timpul de execuție al interogării a crescut semnificativ, atunci, cel mai probabil, a devenit mare.
- valorile din coloană sunt relativ unice;
- o gamă largă de valori (potrivite pentru indicii comuni);
- gamă mică de valori (potrivite pentru indici de biți);
- coloane foarte rare (multe valori nedefinite, „goale”), dar întrebările sunt în mare parte despre rânduri semnificative. În acest caz, este preferată o comparație care să corespundă tuturor valorilor nule:
WHERE COL_X\u003e -9.99 * putere (10, 125) mai degrabă decât
UNDE COL_X NU ESTE NULL Aceasta se datorează faptului că prima folosește indicele COL_X (presupunând că COL_X este o coloană numerică).
Limitați numărul de indici pentru fiecare tabel
Cu cât mai mulți indici, cu atât este mai mare capul de schimbare a tabelului. Când rândurile sunt adăugate sau șterse, toate indexurile de pe tabel sunt actualizate. Când o coloană este actualizată, toți indexurile la care participă trebuie să fie, de asemenea, actualizați.
În cazul indexurilor, trebuie să echilibrați creșterea performanței de interogare față de degradarea performanței în timpul actualizărilor. De exemplu, dacă tabelul poate fi citit în primul rând, indexurile pot fi utilizate pe scară largă; cu toate acestea, dacă tabelul este actualizat frecvent, utilizarea indexurilor ar trebui să fie minimă.
Alegeți Ordine de coloane în indexuri compuse
Deși coloanele pot fi specificate în orice ordine din instrucțiunea CREATE INDEX, ordinea coloanelor din instrucțiunea CREATE INDEX poate afecta performanța interogării. În general, coloanele care sunt cel mai probabil utilizate sunt listate mai întâi în index. Este posibil să se creeze un index compus (folosind mai multe coloane), un astfel de index poate fi utilizat pentru a interoga pe toate coloanele din acest index sau doar pe unele.
Colectați statistici pentru utilizarea corectă a indexului
Indexurile pot fi utilizate mai eficient dacă baza de date colectează și menține statistici despre tabelele utilizate în interogări. Puteți colecta statistici în timpul creării indexului, specificând cuvântul cheie COMPUTE STATISTICS din instrucțiunea CREATE INDEX. Deoarece datele sunt în permanență actualizate și distribuția valorilor se schimbă, statisticile ar trebui să fie actualizate periodic, utilizând procedurile DBMS_STATS.GATHER_TABLE_STATISTICS și DBMS_STATS.GATHER_SCHEMA_STATISTICS.
Distruge indexuri inutile
Indexul este șters în următoarele cazuri:
- dacă utilizarea indexului nu îmbunătățește performanța interogării. Această situație apare dacă tabelul este prea mic sau dacă există multe rânduri în tabel, dar dintre ele doar câteva sunt elemente de index;
- dacă indicele nu este utilizat în cererile dvs. de propuneri;
- dacă indexul este scăzut și înainte de a-l reconstrui.
Indexurile sunt create pe coloane din tabele și vizualizări. Index-urile oferă o modalitate de a găsi rapid date pe baza valorilor din aceste coloane. De exemplu, dacă creați un index pe o cheie primară și apoi căutați un rând de date utilizând valorile cheii primare, atunci SQL Server găsește mai întâi valoarea indexului și apoi folosește indexul pentru a găsi rapid întregul rând de date. Fără un index, se va efectua o scanare completă (scanare) a tuturor rândurilor din tabel, ceea ce poate avea un impact semnificativ asupra performanței.
Puteți crea un index pe majoritatea coloanelor unui tabel sau a unei vizualizări. Excepție fac în principal coloane cu tipuri de date pentru stocarea obiectelor mari ( LOB), precum imagine, textsau varchar (max)... De asemenea, puteți crea indexuri pe coloane concepute pentru a stoca date în format XML, dar acești indici sunt aranjați altfel decât cei standard, iar considerarea lor nu depășește scopul acestui articol. De asemenea, articolul nu acoperă columnstoreindici. În schimb, mă concentrez pe indexurile care sunt cel mai des utilizate în bazele de date. SQL Server.
Un index constă dintr-un set de pagini, noduri de index, care sunt organizate într-o structură de arbore - copac echilibrat... Această structură este de natură ierarhică și începe cu nodul rădăcină din partea de sus a ierarhiei și nodurile frunze din partea de jos, așa cum se arată în figură: 
Când interogați o coloană indexată, motorul de interogare pornește din partea superioară a nodului rădăcină și se deplasează treptat în jos prin nodurile intermediare, fiecare strat al nivelului intermediar conținând informații mai detaliate despre date. Motorul de interogare continuă să se deplaseze prin nodurile indexului până când atinge cel mai mic nivel cu frunze de index. De exemplu, dacă căutați valoarea 123 într-o coloană indexată, motorul de interogare va determina mai întâi pagina la primul nivel intermediar la nivelul rădăcină. În acest caz, prima pagină indică o valoare de la 1 la 100, iar a doua de la 101 la 200, deci motorul de interogare se va referi la a doua pagină a acestui nivel intermediar. Mai departe, se va afla că ar trebui să vă referiți la a treia pagină a următorului nivel intermediar. De aici, motorul de interogare va citi valoarea indexului însuși la un nivel inferior. Frunzele de index pot conține atât datele tabelului în sine, sau pur și simplu un indicator către rândurile cu datele din tabel, în funcție de tipul de index: index indexat sau index neclasificat.
Indicele grupat
Indicele grupat stochează rândurile reale de date în frunzele indexului. Revenind la exemplul anterior, acest lucru înseamnă că rândul de date asociate valorii cheie de 123 va fi memorat în indexul însuși. O caracteristică importantă a unui indice grupat este faptul că toate valorile sunt sortate într-o ordine specifică, fie crescătoare, fie descendentă. Astfel, un tabel sau o vizualizare nu poate avea decât un singur indice grupat. În plus, trebuie remarcat faptul că datele dintr-un tabel sunt stocate într-o formă sortată numai dacă pe acest tabel a fost creat un indice grupat.Un tabel care nu are un indice grupat se numește heap.
Indice neinclus
Spre deosebire de un indice grupat, frunzele unui index neincluzat conțin doar acele coloane ( cheie), prin care este determinat acest index și conține, de asemenea, un indicator către rândurile cu date reale din tabel. Aceasta înseamnă că sistemul de solicitare necesită o operație suplimentară pentru a localiza și recupera datele necesare. Conținutul unui pointer către date depinde dacă datele sunt stocate pe un tabel grupat sau pe un morman. Dacă indicatorul se referă la un tabel grupat, atunci acesta conduce la un indice grupat care poate fi utilizat pentru a găsi datele reale. Dacă indicatorul se referă la un morman, atunci conduce la un identificator specific al rândului de date. Nu pot fi sortați indexuri neîncadrați, spre deosebire de cele grupate, cu toate că puteți crea mai mult de un index neincluzat pe un tabel sau pe o vedere, până la 999. Acest lucru nu înseamnă că ar trebui să creați cât mai mulți indici. Indicii pot îmbunătăți și degrada performanțele sistemului. Pe lângă faptul că puteți crea mai mulți indici neinclusi, puteți include și coloane suplimentare ( coloana inclusă) la indexul său: frunzele indexului vor stoca nu numai valoarea coloanelor indexate în sine, ci și valorile acestor coloane suplimentare care nu sunt indexate. Această abordare vă va permite să soluționați unele restricții ale indexului. De exemplu, puteți include o coloană care nu poate fi indexată sau ocoliți limita de lungime a indexului (900 de octeți în majoritatea cazurilor).Tipuri de index
Pe lângă faptul că este fie grupat, fie necluster, un index poate fi configurat opțional ca un indice compus, un indice unic sau un indice de acoperire.Indicele compozit
Un astfel de index poate conține mai multe coloane. Puteți include până la 16 coloane în index, dar lungimea totală a acestora este limitată la 900 de octeți. Atât indexul cât și cel neaglomerat pot fi compuse.Index unic
Acest index asigură că fiecare valoare din coloana indexată este unică. Dacă indexul este compus, atunci unicitatea se aplică tuturor coloanelor din index, dar nu și pentru fiecare singură coloană. De exemplu, dacă creați un index unic pe coloane NUMEși NUME DE FAMILIE, atunci numele complet trebuie să fie unic, dar duplicatele în prenumele sau prenumele sunt posibile separat.Un index unic este creat automat atunci când definiți restricțiile de coloană: cheie primară sau restricție de unicitate la valori:
- Cheia principala
Când definiți o restricție de cheie primară pe una sau mai multe coloane, atunci SQL Server creează automat un indice grupat unic dacă indicele cluster nu a fost creat anterior (în acest caz, un indice unic neaglomerat este creat de cheia primară) - Unicitatea valorilor
Când definiți o constrângere a unicității valorilor, atunci SQL Server creează automat un index unic neaglomerat. Puteți specifica că un index unic grupat este creat dacă nu a fost deja creat un indice grupat pe tabelă
Indicele de acoperire
Un astfel de index permite unei interogări specifice să recupereze imediat toate datele necesare din frunzele indexului, fără apeluri suplimentare la înregistrările tabelului în sine.Proiectarea indexului
Pe cât de utile pot fi indexurile, acestea ar trebui să fie proiectate cu atenție. Deoarece indexurile pot ocupa spațiu de disc semnificativ, nu doriți să creați mai mulți indici decât este necesar. În plus, indexurile sunt actualizate automat atunci când rândul de date în sine este actualizat, ceea ce poate duce la depășirea suplimentară a resurselor și degradarea performanței. Există câteva considerente de bază de date și de interogare care trebuie luate în considerare la proiectarea indexurilor.Bază de date
Așa cum am menționat anterior, indexurile pot îmbunătăți performanța sistemului deoarece acestea oferă motorului de interogare o cale rapidă pentru a găsi date. Totuși, ar trebui să luați în considerare cât de des doriți să introduceți, să actualizați sau să ștergeți datele. Când schimbați datele, indexurile trebuie, de asemenea, schimbate pentru a reflecta acțiunile corespunzătoare asupra datelor, care pot degrada semnificativ performanțele sistemului. Când planificați strategia de indexare, luați în considerare următoarele recomandări:- Utilizați cât mai puțini indici posibil pentru tabele care sunt actualizate frecvent.
- Dacă tabelul conține o cantitate mare de date, dar modificările acestora sunt minore, atunci utilizați cât mai mulți indici necesari pentru a îmbunătăți performanța interogărilor dvs. Cu toate acestea, gândiți-vă cu atenție înainte de a utiliza indexuri pe tabele mici. poate că folosirea unei căutări în index poate dura mai mult decât scanarea tuturor rândurilor.
- Pentru indexuri grupate, încercați să păstrați câmpurile cât mai scurt. Cel mai bine este să folosiți un indice grupat pe coloane cu valori unice și să nu permiteți NULL-uri. Acesta este motivul pentru care cheia principală este adesea folosită ca un indice grupat.
- Unicitatea valorilor din coloană afectează performanța indexului. În general, cu cât aveți mai multe duplicate într-o coloană, cu atât va fi mai rău indexul. Pe de altă parte, cu cât există mai multe valori unice, cu atât este mai bună sănătatea indicelui. Utilizați un indice unic ori de câte ori este posibil.
- Pentru un index compus, țineți cont de ordinea coloanelor din index. Coloane utilizate în expresii UNDE(de exemplu, WHERE FirstName \u003d "Charlie") trebuie să fie primul în index. Coloanele ulterioare ar trebui să fie listate pe baza unicității lor (coloanele cu cel mai mare număr de valori unice vin în primul rând).
- De asemenea, puteți specifica un index pe coloanele calculate dacă îndeplinesc unele cerințe. De exemplu, expresia folosită pentru a obține valoarea unei coloane trebuie să fie deterministă (întoarce întotdeauna același rezultat pentru un set de parametri de intrare).
Interogări de baze de date
O altă considerație de care trebuie să țineți cont atunci când se proiectează indexuri este ce întrebări sunt efectuate în baza de date. După cum am menționat anterior, ar trebui să luați în considerare cât de des se schimbă datele. În plus, trebuie utilizate următoarele principii:- Încercați să inserați sau să modificați cât mai multe rânduri într-o singură interogare posibil, decât să o faceți în mai multe interogări.
- Creați un index nonclustered pe coloane care sunt frecvent utilizate în interogările dvs. ca termeni de căutare UNDEși conexiuni în A TE ALATURA.
- Luați în considerare coloanele de indexare utilizate în interogările de căutare string pentru valori exacte de potrivire.
Și acum, de fapt:
14 întrebări pe care ai fost prea timid să le pui despre indexuri în SQL Server
De ce un tabel nu poate avea doi indici în grup?
Vrei un răspuns scurt? Un indice grupat este un tabel. Când creați un index grupat pe o tabelă, motorul de stocare sortează toate rândurile din tabel în ordine crescătoare sau descendentă în conformitate cu definiția indexului. Un index grupat nu este o entitate separată ca alți indici, ci un mecanism pentru sortarea datelor într-un tabel și pentru a facilita accesul rapid la rândurile de date.Să spunem că aveți un tabel care conține istoricul tranzacțiilor de vânzări. Tabelul de vânzări include informații precum ID-ul comenzii, poziția articolului în comandă, numărul articolului, cantitatea articolului, numărul comenzii și data etc. Creați un index grupat pe coloane Comanda IDși LineID, ordonate în ordine crescătoare, așa cum se arată în cele ce urmează T-SQL cod:
CREĂ UNICE CLUSTERED INDEX ix_oriderid_lineid ON dbo.Sales (OrderID, LineID);
Când executați acest script, toate rândurile din tabel vor fi sortate fizic mai întâi de coloana OrderID și apoi de LineID, dar datele în sine vor rămâne într-un singur bloc logic, în tabel. Din acest motiv, nu puteți crea doi indici clusteri. Poate fi o singură tabelă cu o singură dată, iar acest tabel poate fi sortat o singură dată într-o ordine specifică.
Dacă un tabel grupat oferă multe beneficii, de ce să folosiți o grămadă?
Ai dreptate. Tabelele grupate sunt minunate, iar majoritatea întrebărilor dvs. vor funcționa mai bine pe tabele care au un indice grupat. Dar, în unele cazuri, s-ar putea să doriți să lăsați tabelele în starea lor naturală, curată, adică. ca grămadă și creați doar indexuri neexclusive pentru a vă menține întrebările sănătoase.Mormanul, după cum vă amintiți, stochează datele într-o ordine aleatoare. De obicei, subsistemul de stocare adaugă date în tabel în ordinea în care sunt inserate, dar subsistemul îi place să mute rândurile în jurul pentru o stocare mai eficientă. Drept urmare, nu aveți nicio șansă de a prezice în ce ordine vor fi stocate datele.
Dacă motorul de interogare trebuie să găsească date fără beneficiile unui indice necluzat, va face o scanare completă a tabelelor pentru a găsi rândurile de care are nevoie. Pe mesele foarte mici, aceasta nu este de obicei o problemă, dar pe măsură ce grămada crește în dimensiune, performanța scade rapid. Desigur, un index nonclustered poate fi de folos folosind un pointer la fișierul, pagina și șirul în care sunt stocate datele - de obicei o alternativă mult mai bună la scanarea tabelelor. Chiar și așa, este dificil să compari beneficiile unui indice grupat atunci când analizezi performanța interogării.
Cu toate acestea, grămada poate ajuta la îmbunătățirea performanței în anumite situații. Luați în considerare un tabel cu un număr mare de inserții, dar actualizări sau ștergeri de date rare. De exemplu, un tabel care stochează un jurnal este utilizat în principal pentru a insera valori până la arhivare. În morman, nu veți vedea paginarea și fragmentarea datelor așa cum se întâmplă cu un index grupat, deoarece rândurile sunt pur și simplu anexate la sfârșitul grupului. Prea multă separare a paginilor poate avea un impact semnificativ asupra performanței și într-un mod nu atât de bun. În general, heap-ul vă permite să inserați date relativ nedureros și nu trebuie să vă luptați cu cheltuielile de stocare și întreținere, așa cum s-ar face cu un indice grupat.
Dar lipsa actualizării și ștergerii datelor nu trebuie considerată singurul motiv. Modul în care sunt eșantionate datele este, de asemenea, un factor important. De exemplu, nu ar trebui să utilizați heap-ul dacă solicitați frecvent intervale de date sau dacă datele solicitate trebuie adesea sortate sau grupate.
Acest lucru înseamnă că ar trebui să luați în considerare utilizarea mormanului doar atunci când lucrați cu tabele foarte mici sau că toată interacțiunea dvs. cu tabelul este limitată la inserarea de date, iar întrebările dvs. sunt extrem de simple (și utilizați în continuare indexuri neincluse). În caz contrar, rămâneți la un indice grupat bine conceput, de exemplu definit pe un câmp cheie ascendent simplu, cum ar fi o coloană folosită frecvent IDENTITATE.
Cum modific factorul de umplere implicit pentru un index?
Modificarea factorului de umplere implicit al unui index este un lucru. Înțelegerea modului de funcționare a raportului implicit este diferită. Dar mai întâi, câțiva pași înapoi. Factorul de umplere a indexului determină cantitatea de spațiu dintr-o pagină pentru a stoca indexul la nivelul de jos (nivelul frunzelor) înainte de a începe să completați o nouă pagină. De exemplu, dacă coeficientul este setat la 90, atunci cu creșterea indicele va lua 90% pe pagină, apoi mergeți la pagina următoare.În mod implicit, valoarea factorului de umplere a indexului din SQL Servereste egal cu 0, care este egal cu 100. Ca urmare, toți indexurile noi vor moșteni automat această setare, cu excepția cazului în care specificați în cod specific o valoare diferită de valoarea standard pentru sistem sau modificați comportamentul implicit. Poți să folosești SQL Server Management Studio pentru a corecta valoarea implicită sau a rula o procedură stocată de sistem sp_configure... De exemplu, setul următor T-SQL comenzile setează valoarea coeficientului la 90 (trebuie mai întâi să treceți la modul setări avansate):
EXEC sp_configure "arată opțiuni avansate", 1; GO RECONFIGURE; GO EXEC sp_configure "factor de umplere", 90; GO RECONFIGURE; MERGE
După modificarea valorii factorului de umplere a indicelui, trebuie să reporniți serviciul SQL Server... Acum puteți verifica valoarea setată rulând sp_configure fără al doilea argument specificat:
EXEC sp_configurează „factorul de umplere” GO
Această comandă ar trebui să returneze o valoare de 90. Ca urmare, toți indexurile nou create vor folosi această valoare. Puteți verifica acest lucru creând un index și solicitând o valoare a factorului de completare:
USE AdventureWorks2012; - baza de date GO CREATE NONCLUSTERED INDEX ix_people_lastname ON Person.Person (LastName); GO SELECT fill_factor FROM sys.indexes WHERE object_id \u003d object_id ("Person.Person") AND name \u003d "ix_people_lastname";
În acest exemplu, am creat un indice non-grupat pe tabelă Persoanăîn baza de date AdventureWorks2012... După crearea indexului, putem obține valoarea factorului de umplere din tabelele de sistem sys.indexes. Cererea ar trebui să returneze 90.
Cu toate acestea, să zicem că ștergem indexul și îl creăm din nou, dar acum am specificat o valoare specifică a factorului de umplere:
CREATE NDECLUSTERED INDEX ix_people_lastname ON Person.Person (LastName) WITH (fillfactor \u003d 80); GO SELECT fill_factor FROM sys.indexes WHERE object_id \u003d object_id ("Person.Person") AND name \u003d "ix_people_lastname";
De data aceasta am adăugat instrucțiunea CUși opțiune factor de umplerepentru operarea noastră de creare a indexului CREAȚI INDEX și a indicat valoarea 80. Operator SELECTAȚIreturnează acum valoarea corespunzătoare.
Până acum, totul a fost destul de simplu. În cazul în care vă puteți bloca cu adevărat în tot acest proces este atunci când creați un index folosind valoarea implicită a coeficientului, presupunând că cunoașteți această valoare. De exemplu, cineva ticăloște în mod neplăcut cu setările serverului și este atât de ridicat încât stabilește valoarea factorului de umplere a indexului egal cu 20. Între timp, continuați să creați indexuri, presupunând o valoare implicită de 0. Din păcate, nu aveți de unde să aflați valoarea coeficientului înainte atâta timp cât nu creați un index și apoi verificați valoarea așa cum am făcut-o în exemplele noastre. În caz contrar, va trebui să aștepți momentul în care performanța de interogare scade atât de mult încât să începi să bănuiești ceva.
O altă problemă de care trebuie să țineți cont este reconstruirea indexului. Ca și în cazul creării unui index, puteți specifica factorul de umplere a indexului atunci când îl reconstruiți. Cu toate acestea, spre deosebire de comanda create index, reconstruirea nu utilizează setările implicite ale serverului, în ciuda a ceea ce ar putea părea. Și mai mult, dacă nu specificați în mod specific valoarea factorului de umplere a indicelui, atunci SQL Server va folosi valoarea coeficientului cu care a existat acest indice înainte de restructurarea sa. De exemplu, următoarea operație ALTER INDEX reconstruiește indexul pe care tocmai l-am creat:
ALTER INDEX ix_people_lastname ON Person.Person REBUILD; GO SELECT fill_factor FROM sys.indexes WHERE object_id \u003d object_id ("Person.Person") AND name \u003d "ix_people_lastname";
Când verificăm valoarea factorului de umplere, obținem o valoare de 80, deoarece aceasta este ceea ce am specificat când am creat ultima dată indexul. Valoarea implicită este ignorată.
După cum puteți vedea, schimbarea valorii factorului de umplere a indicelui nu este atât de dificilă. Este mult mai dificil să cunoașteți valoarea curentă și să înțelegeți atunci când este aplicată. Dacă specificați întotdeauna raportul în mod specific la crearea și reconstruirea indexurilor, atunci cunoașteți întotdeauna rezultatul specific. Cu excepția cazului în care trebuie să vă asigurați că altcineva nu vă încurcă din nou setările serverului, provocând reconstrucția tuturor indexurilor cu factori de umplere a indexului ridicol de mici.
Pot crea un index grupat pe o coloană care conține duplicate?
Da și nu. Da, puteți crea un index grupat pe o coloană cheie care conține valori duplicate. Nu, valoarea coloanei cheie nu poate fi lăsată într-o stare care nu este unică. Lasă-mă să explic. Dacă creați un index cluster nu unic pe o coloană, motorul de stocare adaugă un unificator la valoarea duplicată pentru a asigura unicitatea și, astfel, pentru a asigura identificarea fiecărui rând din tabelul grupat.De exemplu, puteți decide să creați un indice grupat pe o coloană de pe o tabelă de date a clienților Numele de familieținând numele. Coloana conține valori precum Franklin, Hancock, Washington și Smith. Apoi introduceți valorile pentru Adams, Hancock, Smith și din nou pentru Smith. Dar valoarea coloanei cheie trebuie să fie unică, astfel încât subsistemul de stocare va schimba valoarea duplicatelor, astfel încât să arate așa ceva: Adams, Franklin, Hancock, Hancock1234, Washington, Smith, Smith4567 și Smith5678.
La prima vedere, această abordare pare normală, dar o valoare întreagă crește dimensiunea cheii, ceea ce poate fi o problemă cu un număr mare de duplicate, iar aceste valori vor deveni baza unui index sau a unei referințe de cheie străină. Din aceste motive, trebuie să încercați întotdeauna să creați indici unici în cluster, ori de câte ori este posibil. Dacă acest lucru nu este posibil, atunci încercați cel puțin să utilizați coloane cu un conținut foarte ridicat de valori unice.
Cum se păstrează tabelul dacă nu a fost creat un indice grupat?
SQL Server acceptă două tipuri de tabele: tabele grupate având un indice grupat și tabele de grădină sau doar hamei. Spre deosebire de tabelele grupate, datele referitoare la grămadă nu sunt sortate în niciun fel. De fapt, aceasta este o grămadă de date. Dacă adăugați un rând la un astfel de tabel, subsistemul de stocare îl va adăuga pur și simplu la sfârșitul paginii. Când pagina va fi umplută cu date, aceasta va fi adăugată la noua pagină. În cele mai multe cazuri, veți dori să creați un index grupat pe un tabel pentru a profita de capacitatea de sortare și a accelera interogările (încercați să vă imaginați găsind un număr de telefon într-o agendă care nu este sortată după niciun principiu). Cu toate acestea, dacă alegeți să nu creați un index grupat, puteți crea totuși un indice neîncorporat pe bucată. În acest caz, fiecare rând al indexului va avea un indicator către un rând de heap. Indicatorul include un ID de fișier, numărul de pagină și un număr de linie de date.Care este relația dintre constrângerile de unicitate valorică și cheia primară cu indici de tabel?
Cheia principală și și restricția unică asigură că valorile din coloană sunt unice. Puteți crea o singură cheie primară pentru un tabel și nu poate conține valori NUL... Puteți crea mai multe restricții privind unicitatea unei valori pentru un tabel și fiecare dintre ele poate avea o singură înregistrare cu NUL.Când creați o cheie primară, subsistemul de stocare va crea, de asemenea, un indice grupat unic, dacă nu a fost creat un index deja grupat. Cu toate acestea, puteți înlocui comportamentul implicit și va fi creat apoi un index neincluzat. Dacă există un index grupat atunci când creați o cheie primară, atunci va fi creat un indice unic neaglomerat.
Când creați o restricție de unicitate, subsistemul de stocare creează un index unic, neincluzat. Cu toate acestea, puteți specifica crearea unui index unic grupat dacă nu a fost creat anterior.
În general, constrângerea asupra unicității valorii și a indicelui unic sunt același lucru.
De ce sunt numiți indexuri cluster și non-cluster, B-tree în SQL Server?
Indici de bază în SQL Server, indiferent dacă sunt grupate sau neincluse, sunt propagate pe seturi de pagini care sunt noduri de index. Aceste pagini sunt organizate într-o ierarhie specifică cu o structură de arbore numită arbore echilibrat. La nivelul superior se află nodul rădăcină, în partea inferioară, nodurile de capăt de frunze, cu noduri intermediare între nivelurile de sus și de jos, așa cum se arată în figură:Nodul rădăcină furnizează punctul principal de intrare pentru interogări care încearcă să obțină date prin index. Începând de la acest nod, motorul de interogare inițiază o navigație ierarhică către un nod final adecvat care conține date.
De exemplu, să presupunem că se primește o solicitare pentru a obține rânduri care conțin o valoare cheie egală cu 82. Motorul de interogare pornește de la nodul rădăcină, care se referă la un nod intermediar adecvat, în cazul nostru 1-100. De la nodul intermediar 1-100, trecerea trece la nodul 51-100, iar de acolo la nodul final 76-100. Dacă este un indice grupat, atunci frunza de nod conține datele de rând asociate cu cheia 82. Dacă este un indice necluzat, atunci frunza de index conține un pointer către tabelul grupat sau un rând specific din grămadă.
Cum poate un indice, în general, să îmbunătățească performanța interogării dacă trebuie să parcurgi toate aceste noduri de index?
În primul rând, indexurile nu îmbunătățesc întotdeauna performanța. Prea multe indexuri create incorect fac ca sistemul să se umple și să încetinească performanța interogării. Ar fi mai exact să spunem că, dacă indicii sunt aplicați cu atenție, aceștia pot oferi câștiguri semnificative ale performanței.Gândește-te la o carte uriașă privind reglarea performanței SQL Server (hârtie, nu versiune electronică). Imaginați-vă că doriți să găsiți informații despre configurarea Administratorului resurselor. Puteți glisa degetul pe întreaga pagină a cărții cu pagină sau puteți deschide cuprinsul și aflați numărul exact al paginii cu informațiile pe care le căutați (cu condiția ca cartea să fie corect indexată și indexurile să fie corecte în cuprins). Desigur, acest lucru vă va economisi mult timp, chiar dacă trebuie să mergeți mai întâi la o structură (index) complet diferită pentru a obține informațiile de care aveți nevoie din structura primară (carte).
Ca un index al cărții, indexul din SQL Server vă permite să efectuați întrebări precise asupra datelor dorite, în loc de o scanare completă a tuturor datelor conținute în tabel. În cazul tabelelor mici, scanările complete nu sunt de obicei o problemă, dar tabelele mari ocupă multe pagini de date, ceea ce poate duce la un timp de interogare semnificativ dacă nu există un index care să permită motorului de interogare să obțină imediat locația corectă a datelor. Imaginați-vă că vă pierdeți pe o intersecție rutieră pe mai multe niveluri, în fața unei metropole mari, fără hartă și veți primi ideea.
Dacă indexurile sunt atât de grozave, de ce nu creați doar unul pe fiecare coloană?
Nicio faptă bună nu trebuie să rămână nepedepsită. Cel puțin acesta este cazul indiciilor. Desigur, indexurile funcționează bine atât timp cât executați interogări cu privire la preluarea datelor cu operatorul SELECTAȚI, dar imediat ce începe apelul frecvent al operatorilor INTRODUCE, ACTUALIZAȚIși ȘTERGEdeci peisajul se schimbă foarte repede.Când inițiați o solicitare de date de către un operator SELECTAȚI, motorul de interogare găsește indexul, traversează structura arborelui său și găsește datele pe care le caută. Ce ar putea fi mai ușor? Dar totul se schimbă dacă inițiați o declarație de modificare, cum ar fi ACTUALIZAȚI... Da, pentru prima parte a declarației, motorul de interogare poate folosi din nou indexul pentru a găsi modificarea rândului - aceasta este o veste bună. Și dacă există o simplă modificare a datelor dintr-un rând care nu afectează modificarea coloanelor cheie, procesul de modificare va fi complet nedureros. Dar dacă schimbarea face ca paginile care conțin datele să fie împărțite sau valoarea coloanei cheie să se schimbe, determinând mutarea acesteia într-un inod diferit - acest lucru ar face ca indexul să necesite o reorganizare care să afecteze toți indexurile și operațiile asociate, rezultând în scădere răspândită a productivității.
Procese similare apar atunci când este apelat operatorul ȘTERGE... Indexul poate ajuta la găsirea locației datelor șterse, dar ștergerea datelor în sine poate duce la rearanjări ale paginii. Operator INTRODUCE, principalul inamic al tuturor indexurilor: începeți să adăugați cantități mari de date, ceea ce duce la modificări și reorganizări ale indexului și toată lumea suferă.
Așadar, luați în considerare tipurile de interogări ale bazei de date atunci când vă gândiți ce tip de indici și câți creați. Mai mare nu este mai bun. Înainte de a adăuga un nou index într-un tabel, luați în considerare costul nu numai a interogărilor de bază, ci și a cantității de spațiu pe disc utilizat, a costului de menținere a operativității și a indexurilor, ceea ce poate duce la un efect domino pentru alte operațiuni. Strategia de proiectare a indexului este unul dintre cele mai importante aspecte ale implementării și ar trebui să includă multe considerente, de la mărimea indexului, numărul de valori unice, la tipul de interogări pe care le suportă indexul.
Este obligatorie crearea unui indice grupat pe o coloană de chei primare?
Puteți crea un index grupat pe orice coloană care îndeplinește condițiile cerute. Este adevărat că indicele grupat și constrângerea cheii primare sunt create unul pentru celălalt și sunt căsătoriți în cer, așa că rețineți că atunci când creați o cheie primară, atunci indicele grupat va fi creat automat dacă nu a fost creat anterior. Cu toate acestea, puteți decide că un indice grupat va funcționa mai bine în altă parte și de multe ori decizia dvs. va merita.Scopul principal al unui indice grupat este de a sorta toate rândurile în tabelul dvs. pe baza coloanei cheie specificată la indicarea. Acest lucru permite căutări rapide și acces facil la datele din tabel.
Cheia principală a unei tabele poate fi o alegere bună, deoarece identifică în mod unic fiecare rând din tabele fără a fi nevoie să adăugați date suplimentare. În unele cazuri, cea mai bună alegere este o cheie primară care este nu numai unică, ci și mărime mică și incrementată, făcând mai eficienți indexurile noncluster bazate pe această valoare. Optimizatorul de interogări iubește, de asemenea, această combinație de un index grupat și o cheie primară, deoarece unirea tabelelor este mai rapidă decât alăturarea într-un alt mod care nu folosește cheia primară și indexul grupat asociat. După cum am spus, aceasta este o căsătorie făcută în ceruri.
La final, însă, este demn de remarcat faptul că atunci când se creează un indice grupat, există mai multe aspecte care trebuie luate în considerare: câți indici neinclusi se vor baza pe el, cât de des se va modifica valoarea coloanei cheie de index și cât de mare. Atunci când valorile din coloanele de index grupate se modifică sau indexul nu funcționează așa cum este de așteptat, atunci toți ceilalți indici din tabel pot fi afectați. Indicele grupat trebuie să se bazeze pe coloana cea mai stabilă, ale cărei valori sunt incrementate într-o ordine specifică, dar nu aleatoriu. Indexul trebuie să accepte interogări cu privire la datele tabelelor cel mai frecvent accesate, astfel încât interogările profită din plin de datele care sunt sortate și disponibile la nodurile rădăcină, frunzele indexului. Dacă cheia principală se potrivește cu acest scenariu, atunci utilizați-l. Dacă nu, atunci selectați un set de coloane diferit.
Ce se întâmplă dacă indici o vizualizare, este încă o vizualizare?
O vizualizare este o tabelă virtuală care generează date dintr-una sau mai multe tabele. Practic, este o interogare numită care preia datele din tabelele de bază atunci când invocați o interogare pe acea vizualizare. Puteți îmbunătăți performanța interogării prin crearea unui indice grupat și a unor indexuri nonclutate în această vizualizare, similar cu modul în care creați indexuri pe o tabelă, dar principalul avertisment este că inițial este creat un indice grupat și apoi puteți crea unul neclasificat.Când este creată o vizualizare indexată (vizualizare materializată), definiția vizualizării în sine rămâne o entitate separată. Acesta este, până la urmă, doar un operator hardcodat SELECTAȚIstocate în baza de date. Însă indexul este o cu totul altă poveste. Atunci când creați un index cluster sau non-cluster într-o vizualizare, datele sunt salvate fizic pe disc, la fel ca un index normal. În plus, atunci când se modifică datele din tabelele subiacente, indexul vizualizării este modificat automat (asta înseamnă că poate doriți să evitați indexarea vizualizărilor acelor tabele care se află sub modificări frecvente). În orice caz, vizualizarea rămâne o vedere - o privire asupra tabelelor, dar executată exact în acest moment, cu indicii corespunzători acesteia.
Înainte de a putea crea un index pe o vizualizare, acesta trebuie să îndeplinească mai multe constrângeri. De exemplu, o vizualizare poate doar tabele de referință de referință, nu alte vizualizări, iar aceste tabele trebuie să fie în aceeași bază de date. De fapt, există multe alte restricții, așa că asigurați-vă că verificați documentația SQL Serverîn spatele tuturor detaliilor murdare.
De ce să folosiți un indice de acoperire în loc de un indice compozit?
În primul rând, să ne asigurăm că înțelegem diferența dintre cei doi. Un index compus este doar un indice obișnuit care conține mai mult de o coloană. Mai multe coloane cheie pot fi utilizate pentru a vă asigura că fiecare rând dintr-un tabel este unic, este posibil, de asemenea, atunci când cheia primară are mai multe coloane pentru a vă asigura că este unică sau încercați să optimizați execuția de interogări numite frecvent împotriva mai multor coloane. În general, cu toate acestea, cu cât mai multe coloane cheie conține un indice, cu atât este mai puțin eficient indexul și, prin urmare, ar trebui să se utilizeze în mod înțelept indexuri compuse.După cum am menționat, o interogare poate beneficia enorm dacă toate datele necesare sunt localizate imediat pe frunzele indexului, la fel ca indexul în sine. Aceasta nu este o problemă pentru un index grupat deoarece toate datele sunt deja acolo (motiv pentru care este atât de important să te gândești cu atenție când creezi un index grupat). Dar indicele neexclusat pe frunze conține doar coloane cheie. Sunt necesari pași suplimentari pentru ca optimizatorul de interogare să acceseze toate celelalte date, ceea ce poate duce la completarea întrebărilor suplimentare suplimentare.
Aici indicele de acoperire este util. Când definiți un index nonclustered, puteți adăuga coloane suplimentare coloanelor dvs. cheie. De exemplu, să presupunem că aplicația dvs. solicită frecvent date de coloană Comanda IDși Data comandăin masa Vânzări:
SELECTA OrderID, OrderDate din vânzări WHERE OrderID \u003d 12345;
Puteți crea un index necompletat compus pe ambele coloane, dar coloana OrderDate va adăuga doar întreținerea indexului, dar niciodată nu va servi drept o coloană cheie deosebit de utilă. Cea mai bună soluție ar fi crearea unui indice de acoperire cu o coloană de cheie Comanda IDși o coloană inclusă în plus Data comandă:
CREATE INDEX NONCLUSTERED ix_orderid ON dbo.Sales (OrderID) INCLUDE (OrderDate);
Făcând acest lucru, evitați dezavantajele indexării coloanelor redundante, păstrând în același timp beneficiile stocării datelor pe frunze atunci când executați interogări. Coloana inclusă nu face parte din cheie, dar datele sunt stocate în nodul final, foaia de index. Acest lucru poate îmbunătăți performanța interogării fără costuri suplimentare. În plus, coloanele incluse în indicele de acoperire au mai puține constrângeri decât coloanele cheie ale indexului.
Numărul de duplicate dintr-o coloană cheie contează?
Când creați un index, trebuie să încercați să reduceți numărul de duplicate din coloanele dvs. cheie. Sau mai exact: încercați să păstrați raportul de repetare cât mai scăzut posibil.Dacă lucrați cu un index compus, atunci duplicarea se aplică tuturor coloanelor cheie în general. O singură coloană poate conține multe valori duplicate, dar ar trebui să existe o duplicare minimă între toate coloanele din index. De exemplu, creați un index compus neclasificat pe coloane Numeși Numele de familie, puteți avea multe valori John Doe și multe valori Doe, dar doriți cât mai puține valori John Doe sau mai bine doar o valoare John Doe.
Factorul de unicitate pentru valorile unei coloane cheie se numește selectivitate index. Cu cât sunt mai unice valori, cu atât selectivitatea este mai mare: indexul unic are cea mai mare selectivitate posibilă. Motorul de interogare este foarte îndrăgit de coloanele cu selectivitate ridicată, mai ales dacă acele coloane participă la clauzele WHERE ale interogărilor dvs. cel mai frecvent executate. Cu cât selectivitatea indexului este mai mare, cu atât mai rapid motorul de interogare poate reduce dimensiunea setului de date rezultat. Dezavantajul este, desigur, că coloane cu valori relativ puține unice sunt rareori candidați buni pentru indexare.
Este posibil să se creeze un index nonclustered doar pe un subset specific de date ale coloanei cheie?
În mod implicit, un index noncluster conține un rând pentru fiecare rând din tabel. Desigur, puteți spune același lucru și pentru un index grupat, presupunând că indicele este de fapt un tabel. Dar, în ceea ce privește indicele nonclustered, relația unu-la-unu este un concept important, deoarece începe cu versiunea SQL Server 2008, aveți opțiunea de a crea un indice filtrabil care limitează rândurile incluse în acesta. Un indice filtrabil poate îmbunătăți performanța interogării deoarece este mai mică și conține statistici filtrate, mai exacte decât toate statisticile tabulare - acest lucru duce la planuri de execuție mai bune. Un indice filtrabil necesită, de asemenea, mai puțin spațiu de stocare și costuri de întreținere mai mici. Indexul este actualizat numai atunci când datele care se potrivesc filtrului se schimbă.În plus, un indice filtrabil este ușor de creat. În operator CREAȚI INDEX trebuie doar să fie specificat în UNDEstarea de filtrare. De exemplu, puteți filtra toate rândurile NULL din index, așa cum se arată în cod:
CREATE NDECLUSTERED INDEX ix_trackingnumber ON Sales.SalesOrderDetail (CarrierTrackingNumber) WHERE CarrierTrackingNumber NU ESTE NULL;
De fapt, putem filtra orice date care nu sunt importante în interogările critice. Dar fii atent, pentru că SQL Server impune mai multe restricții asupra indexurilor filtrabile, cum ar fi incapacitatea de a crea un indice filtrabile pe o vizualizare, așadar citiți cu atenție documentația.
De asemenea, se poate întâmpla că puteți obține rezultate similare prin crearea unei vizualizări indexate. Cu toate acestea, un indice filtrat are mai multe avantaje, cum ar fi posibilitatea de a reduce costurile de întreținere și de a îmbunătăți calitatea planurilor de execuție. Indicii filtrați pot fi, de asemenea, reconstruiți online. Încercați acest lucru cu o vizualizare indexată.
Și din nou un pic de la traducător
Scopul apariției acestei traduceri pe paginile Habrahabr a fost să vă spun sau să vă amintesc despre blogul din SimpleTalk Redgate.
Conține multe intrări interesante și interesante.
Nu sunt afiliat cu niciun produs al companiei Redgatenici cu vânzarea lor.
După cum a promis, cărțile sunt destinate celor care vor să știe mai multe
Vă voi recomanda trei cărți foarte bune de la mine (linkurile duc la aprindeversiuni în magazin Amazon):
 |
Fundamente T-SQL Microsoft SQL Server 2012 (Referință pentru dezvoltatori) Autor Itzik Ben-Gan Data publicării: 15 iulie 2012 Autorul, un maestru al meșteșugului său, oferă cunoștințe de bază despre lucrul cu baze de date. Dacă ai uitat totul sau nu ai știut niciodată, atunci merită cu siguranță să-l citești. | Practic, puteți deschide indicii simple Adăugați etichete
Dacă există multe înregistrări în tabel, atunci poate fi foarte dificil să găsiți înregistrarea necesară. Căutarea datelor se efectuează prin metoda de enumerare, adică toate înregistrările tabelelor de la prima înregistrare până la ultima înregistrare sunt scanate, ceea ce duce la o pierdere mare de timp. Se folosesc indexuri pentru a facilita găsirea datelor într-un tabel. Un index, uneori numit indicator, este numărul ordinal al unei intrări dintr-un tabel. Indicele este construit pe valorile unui câmp sau pe valorile mai multor câmpuri. Un indice bazat pe valorile unui câmp se numește simplu și, pe baza valorilor a două sau mai multe câmpuri, se numește complex. Când este construit indexul, înregistrările din tabel sunt sortate după valorile câmpului (sau câmpurilor) viitorului index. Apoi, primului rând al tabelului i se atribuie indexul numărul unu, celui de-al doilea rând i se atribuie indexul numărul doi și așa mai departe până la sfârșitul tabelului.
Atât indexurile simple, cât și cele complexe au propriul tip (Type). Indicele primar (cheie) este un câmp sau un grup de câmpuri care identifică în mod unic o înregistrare, adică valorile indexului primar sunt unice (nu se repetă). Într-o bază de date relațională, fiecare tabel poate avea o singură cheie primară. Un tabel poate avea multe chei străine și va avea unul dintre tipuri:
Candidat - Un candidat pentru o cheie primară sau o cheie alternativă. Are toate proprietățile unei chei primare.
Unic - permite duplicarea valorilor în câmpul pe care este construită, dar va fi afișată doar o primă înregistrare dintr-un grup de înregistrări cu aceeași valoare a câmpului index.
Regular - nu impune nicio restricție asupra valorilor câmpului index și asupra ieșirii înregistrărilor pe ecran. Indexul controlează numai ordinea în care sunt afișate intrările. Acesta este cel mai popular tip de index.
Relația dintre tabele se bazează pe indexuri, care se numesc chei.
Indicele construit este stocat într-un fișier index special. Dacă fișierul index conține un singur index, atunci se numește index unic și are extensia .idx. Fișierele de index care stochează mai mulți indici se numesc fișiere multi-index și au extensia .cdx. Fiecare index care este stocat într-un fișier multi-index se numește etichetă. Fiecare etichetă are propriul său nume unic.
Există două tipuri de fișiere multi-index: fișiere simple multi-index (descrise mai sus) și fișiere multi-index structurate. Un fișier structural multi-index are același nume ca tabelul din care face parte (singura diferență este în extensia fișierului) și are următoarele proprietăți:
Se deschide automat cu propria masă;
Nu poate fi închisă, dar poate fi făcută nu principală.
Un tabel poate avea multe fișiere index, atât un singur index cât și multi-index. Versiunile mai vechi de FoxPro folosesc fișiere Multi-index.
Crearea indexului
Există două moduri de a crea un index.
și.Cu comanda:
INDEX ACTIVAT<индексное выражение> LA< idx-file\u003e | ETICHETĂ<имя тега>
Opțiuni alocare:
<expresie index\u003e- numele câmpului (sau câmpurilor), în funcție de valorile cărora ar trebui construit indexul. Când construiți un index complex, numele câmpurilor sunt listate separat printr-un semn + (plus). Dacă un index complex este construit de:
Pentru câmpurile numerice, indexul se bazează pe suma valorilor câmpului;
Câmpuri simbolice, apoi indexul este construit mai întâi după valoarea primului câmp, și cu valori repetate ale primului câmp - de valorile celui de-al doilea câmp; cu valori repetate ale primului și celui de-al doilea câmp - în funcție de valorile câmpului al treilea, etc .;
Pentru câmpuri de diferite tipuri, atunci mai întâi valorile câmpului sunt convertite într-un tip, de obicei simbolic, iar apoi este construit indexul.
Expresia indexului nu trebuie să depășească 254 de caractere.
LA< idx-fișier\u003e- este indicat numele fișierului cu un singur index.
ETICHETĂ<имя тега> - numele etichetei este indicat în fișierul multi-index. Dacă opțiunea este utilizată, eticheta creată este plasată în fișierul multi-index specificat, iar dacă fișierul multi-index necesar lipsește, atunci se va construi un fișier multi-index structural. Dacă opțiunea este omisă, eticheta creată va fi plasată în fișierul multi-index actual.
PENTRU<условие> - stabilește modul de selecție la indexul acelor înregistrări ale tabelului care sunt satisfăcute<условию>.
COMPACT- gestionează crearea unui fișier compact cu un singur index. Nu este utilizat în versiunile mai vechi de FoxPro.
DESCENDENTĂ- creează indexul în ordine descrescătoare. Valoarea implicită este construirea indexului în ordine crescătoare (ASCENDING). Pentru fișiere cu un singur index, puteți construi doar un index ascendent. Dacă emiteți comanda SET COLLATE înainte de a utiliza comanda INDEX ON ..., puteți construi un fișier one-in-dex în ordine descrescătoare.
UNIC- creează un index unic. Dacă câmpurile (câmpurile) de index conțin valori duplicate, atunci o primă înregistrare intră în index și restul înregistrărilor nu vor fi disponibile.
ADITIV- fișierul index nou creat nu închide fișierele index deja deschise până în acest moment. Dacă opțiunea este omisă, fișierul index nou creat închide toate fișierele index deschise anterior.
b.Utilizarea meniului principal:
În acest caz, indexul este creat fie când se creează tabela, fie când se modifică structura tabelului. Pentru a face acest lucru, selectați fila Index în panoul de dialog Designer tabel (Fig. 3.1).
Fiecare index este descris de o linie în fereastra de dialog Designer tabelă.
Coloana Nume conține numele etichetei fișierului multi-index. Dacă unul dintre fișierele multi-index a fost deschis mai devreme, atunci indexul nou construit este plasat în fișierul multi-index deschis. Dacă indexul este construit simultan cu crearea fișierului tabel, sau fișierul tabel nu are fișiere multi-index, atunci indexul nou construit este plasat în fișierul multi-index creat structural automat.

Coloana Tip cu o listă derulantă indică unul dintre tipurile de index permise. Dacă indexul este construit pe un tabel care face parte din baza de date, atunci sunt posibile patru valori: primar, candidat, unic și regulat. Dacă indexul este construit pentru un tabel gratuit, atunci valoarea primară lipsește din lista verticală.
Coloana Expression listează numele câmpurilor, în funcție de valorile cărora ar trebui construit indexul. Dacă creați un index complex, atunci este mai convenabil să folosiți Expression Builder, care este lansat făcând clic pe butonul situat în dreapta câmpului de introducere.
În coloana Filtru, puteți seta o condiție logică și construi un index nu pentru toate înregistrările de tabel, ci doar pentru înregistrările care îndeplinesc condiția filtrului. Acest grafic este, de asemenea, echipat cu un constructor de expresii. Conținutul și aspectul ambilor constructori sunt identici (Fig. 3.2).
În fig. 3.2 prezintă construcția unui index complex folosind două câmpuri de caractere ush_step și uch_zvan (numele etichetei uch a fost atribuit înainte de a fi apelat pe ecran constructorul de expresii). Semnul "+" care indică construcția unui index complex este preluat din lista derulantă String,
Meniul derulant String listează funcțiile de șir valabile. De asemenea, listele derulante Math, Logical și Date arată funcții matematice, logice și date valabile. Funcția dorită este selectată din aceste liste derulante făcând clic pe butonul stânga al mouse-ului. Numele câmpurilor (Lista câmpurilor) și numele variabilelor (lista Variabilelor) sunt selectate făcând dublu clic pe butonul stânga al mouse-ului. Expresia rezultată este plasată în fereastra Expression.
Lista derulantă Din tabel indică numele tabelului din care sunt luate câmpurile pentru a construi indexul. Dacă doriți, puteți comanda orice tabel din baza de date curentă și puteți lua orice câmp pentru a construi indexul.
În acest material, astfel de obiecte de bază de date vor fi luate în considerare Microsoft SQL Server la fel de indiciiVei afla ce sunt indexurile, ce tipuri de indici sunt, cum să le creezi, să le optimizezi și să le ștergi.
Ce sunt indexurile dintr-o bază de date?
Index Este un obiect de bază de date care este o structură de date alcătuită din chei bazate pe una sau mai multe coloane dintr-un tabel sau vizualizare și indicatoare care se asortează la locul în care sunt stocate datele. Indexurile sunt concepute pentru a obține rândurile dintr-un tabel mai repede, cu alte cuvinte, indexurile oferă căutări rapide de date dintr-un tabel, ceea ce îmbunătățește considerabil performanța interogării și a aplicației. De asemenea, indexurile pot fi utilizate pentru a asigura unicitatea rândurilor de tabele, asigurând astfel integritatea datelor.
Tipuri de index în Microsoft SQL Server
Următoarele tipuri de indexuri există în Microsoft SQL Server:
- grupată (grupată) Este un index care stochează datele tabelelor sortate după valoarea cheii indexului. Un tabel poate avea doar un singur indice grupat, deoarece datele pot fi sortate doar într-o singură ordine. Ori de câte ori este posibil, fiecare tabelă ar trebui să aibă un indice grupat, dacă tabelul nu are un indice grupat, un astfel de tabel se numește " morman“. Indicele grupat este creat automat atunci când PRIMAR KEY ( cheia principala) și UNIQUE dacă un index nu a fost încă definit pe tabelă. Când creați un indice grupat pe tabelă ( grămezi) care are indexuri neincluse, toate acestea trebuie reconstruite după creare.
- Non-cluster (Nonclustered) Este un index care conține o valoare cheie și un pointer către un șir de date care conține valoarea cheii respective. Un tabel poate avea mai mulți indici neinclusi. Indecși neîncadrați pot fi creați pe tabele cu sau fără un indice grupat. Acest tip de indice este utilizat pentru a îmbunătăți performanța interogărilor frecvent utilizate, deoarece indexurile neincluse oferă căutare rapidă și acces la date prin valori cheie;
- Filtrabil (Filtrate) Este un index optimizat necluzat care utilizează un predicat de filtrare pentru a indexa un subset de rânduri dintr-un tabel. Dacă este bine conceput, acest tip de index poate îmbunătăți performanța interogării și poate reduce, de asemenea, costurile de întreținere și stocare a indexurilor, comparativ cu indexurile cu tabel complet;
- Unic (Unic) Este un index care asigură că nu există duplicate ( la fel) valorile cheii index, garantând astfel unicitatea rândurilor pentru această cheie. Atât indexul cât și cel neincluzat pot fi unici. Dacă creați un index unic pe mai multe coloane, indexul asigură că fiecare combinație de valori din cheie este unică. Când creați restricții PRIMARY KEY sau UNIQUE, serverul SQL creează automat un index unic pe coloanele cheie. Un index unic poate fi creat numai dacă tabelul nu are în prezent valori duplicate pentru coloanele cheie;
- în formă de coloană (Columnstore) Este un indice bazat pe tehnologia de stocare pe coloane. Acest tip de index este eficient pentru depozitele mari de date, deoarece poate crește performanța interogărilor la stocare de până la 10 ori și, de asemenea, poate reduce dimensiunea datelor de până la 10 ori, deoarece datele din indexul Columnstore sunt comprimate. Există atât indexuri columnare grupate, cât și altele neexcluse;
- Text complet (Text complet) Este un tip special de index care oferă asistență eficientă pentru căutări complexe de cuvinte în datele șirului de caractere. Procesul de creare și menținere a unui index cu text complet se numește " umplere“. Există tipuri de umplere, cum ar fi completarea completă și completarea urmăririi. În mod implicit, serverul SQL populează complet un nou index cu text complet imediat după crearea acestuia, dar acest lucru poate necesita o cantitate semnificativă de resurse, în funcție de dimensiunea tabelului, astfel încât este posibil să amânați semințarea completă. Paddingul de urmărire a modificărilor este utilizat pentru a menține un index cu text complet după ce este inițial complet;
- spațial (spațial) Este un index care vă permite să utilizați mai eficient operațiuni specifice pe caracteristici pe coloane cu tipul de date de geometrie sau geografie. Acest tip de index poate fi creat doar pentru o coloană spațială, iar tabelul pentru care este definit indexul spațial trebuie să conțină o cheie primară ( CHEIA PRINCIPALA);
- XML Este un alt tip special de index care este proiectat pentru coloane cu tipul de date XML. Indicele XML îmbunătățește eficiența procesării interogărilor pe coloane XML. Există două tipuri de indici XML: primar și secundar. Un index XML primar indexează toate etichetele, valorile și căile stocate într-o coloană XML. Poate fi creat numai dacă tabelul are un indice grupat pe cheia primară. Un indice XML secundar poate fi creat numai dacă tabelul are un indice XML primar și este utilizat pentru a îmbunătăți performanța interogărilor pe un anumit tip de acces la o coloană XML, prin urmare, există mai multe tipuri de indici secundari: PATH, VALUE și PROPERTY;
- Există, de asemenea, indexuri speciale pentru tabele optimizate de memorie ( OLTP în memorie) cum ar fi: Hash ( hașiș) indexuri și indexări optimizate pentru memorie neclasate, care sunt create pentru scanări de gamă și scanări comandate.
Crearea și eliminarea indexurilor în Microsoft SQL Server
Înainte de a începe crearea unui indice, trebuie să-l proiectați bine pentru a utiliza indexul eficient, întrucât indexurile slab proiectate ar putea să nu crească performanța, ci să le scadă. De exemplu, un număr mare de indici de pe un tabel degradează performanța instrucțiunilor INSERT, UPDATE, DELETE și MERGE, deoarece atunci când datele din tabel se schimbă, toți indexurile trebuie schimbate în consecință. Vom lua în considerare orientările generale pentru proiectarea indexurilor într-un articol separat, dar acum să trecem direct la procesul de creare și abandonare a indexurilor.
Notă! Serverul meu SQL este Microsoft SQL Server 2016 Express.
Crearea indexurilor
Există două moduri de a crea indexuri în Microsoft SQL Server: prima este folosirea interfeței grafice a SQL Server Management Studio (SSMS), iar a doua utilizând limbajul Transact-SQL, vă vom parcurge ambele metode.
Date inițiale pentru exemple
Să ne imaginăm că avem un tabel de produse numit TestTable care are trei coloane:
- ProductId - identificator de produs;
- ProductName - numele produsului;
- CategorieID - categorie de produse.
Exemplu de creare a unui indice grupat
Așa cum spuneam, un indice grupat este creat automat dacă, de exemplu, atunci când creăm un tabel, specificăm o anumită coloană ca cheie primară ( CHEIA PRINCIPALA), dar din moment ce nu am făcut-o, să ne uităm la un exemplu de creare a unui index în grup.
Pentru a crea un indice grupat, putem specifica o cheie primară pe tabelă și, astfel, indexul grupat va fi creat automat sau putem crea un indice grupat separat.
De exemplu, haideți să creăm doar un indice grupat fără a crea o cheie primară. În primul rând, să facem acest lucru folosind Management Studio.
Deschideți SSMS și în exploratorul de obiecte găsiți tabelul necesar și faceți clic dreapta pe elementul " Indici ai", Alegeți" Creați index„Și tipul de index, în cazul nostru” grupată».

Forma " Index nou", Unde trebuie să specificăm numele noului index ( trebuie să fie unic în tabel), indicăm, de asemenea, dacă acest index va fi unic, dacă vorbim despre identificatorul produsului din tabelul de produse, atunci, desigur, trebuie să fie unic. Apoi selectați coloana ( cheie index), pe baza căreia vom crea un indice grupat, adică. rândurile de date din tabel vor fi sortate cu ajutorul butonului " Adauga la».

După introducerea tuturor parametrilor necesari, faceți clic pe „ O.K", Ca rezultat, va fi creat un indice grupat.

De asemenea, s-ar putea crea un index grupat folosind o instrucțiune T-SQL INDEX CREATREde exemplu ca acesta
CREĂ UNICE CLUSTERED INDEX IX_Clustered ON TestTable (ProductId ASC) GO
Sau, așa cum am spus, se poate utiliza, de asemenea, instrucțiunea pentru a crea o cheie primară
ALTER TABLE TestTable ADAUGĂ CONSTRAINT PK_TestTable PRIMAR CLYTERED KEY (Produs ASC) GO
Exemplu de creare a unui index nonclustered cu coloane incluse
Acum să ne uităm la un exemplu de creare a unui indice neaglomerat, în timp ce vom indica coloanele care nu vor fi cheie, dar vor fi incluse în index. Acest lucru este util în cazurile în care creați un index pentru o interogare specifică, de exemplu, astfel încât indexul acoperă complet interogarea, adică. conținea toate coloanele ( aceasta se numește „Solicitare acoperire”). Acoperirea de interogare îmbunătățește performanța, deoarece optimizatorul de interogări poate găsi toate valorile coloanei din index fără a accesa datele din tabel, rezultând în mai puține operații de I / O pe disc. Amintiți-vă însă că includerea coloanelor nonkey în index crește dimensiunea indexului; mai mult spațiu pe disc este necesar pentru a stoca indexul, iar performanțele operațiunilor INSERT, UPDATE, DELETE și MERGE de pe tabelul de bază pot de asemenea să se degradeze.
Pentru a crea un index necluzat folosind GUI-ul Management Studio, găsim de asemenea tabelul dorit și elementul indexuri, doar în acest caz selectăm „ Creați -\u003e Index neexclus».

După deschiderea formularului " Index nou"Indicăm numele indexului, adăugăm o coloană sau coloane cheie folosind butonul" Adauga la", De exemplu, pentru cazul nostru de test, să specificăm CategoryID.

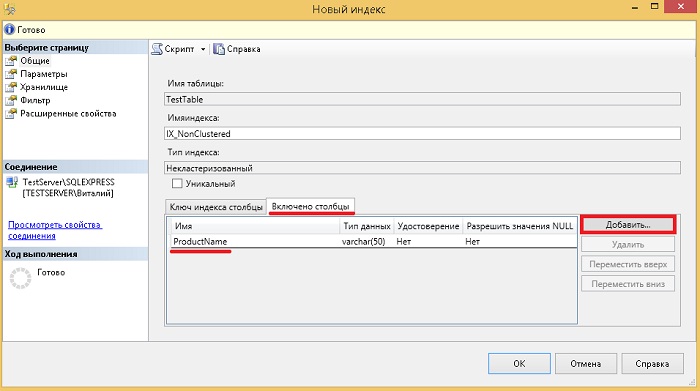
În Transact-SQL, arată așa.
CREATE INDEX NONCLUSTERED IX_NonClustered ON TestTable (CategoryID ASC) INCLUDE (ProductName) GO
Exemplu de renunțare la un index în Microsoft SQL Server
Pentru a șterge un index, puteți face clic dreapta pe indexul dorit și faceți clic pe „ Șterge", Apoi confirmați-vă acțiunea făcând clic pe" O.K».

sau puteți utiliza, de asemenea, instrucțiunea INDEX DROP, de exemplu
DROP INDEX IX_NonClustered ON TestTable
Rețineți că instrucțiunea DROP INDEX nu se aplică indexurilor care au fost create prin crearea de constrângeri PRIMARY KEY și UNIQUE. În acest caz, pentru a renunța la index, trebuie să utilizați instrucțiunea ALTER TABLE cu clauza DROP CONSTRAINT.
Optimizarea indexurilor în Microsoft SQL Server
Ca urmare a efectuării operațiunilor de actualizare, adăugare sau ștergere a datelor din tabelele SQL, serverul face automat modificările corespunzătoare indexurilor, dar în timp, toate aceste modificări pot provoca fragmentarea datelor în index, adică. acestea vor fi împrăștiate în toată baza de date. Fragmentarea indexurilor implică o scădere a performanței de interogare, astfel încât periodic este necesar să se efectueze operațiuni de întreținere a indexului, și anume defragmentarea, cum ar fi operațiunile de reorganizare și reconstrucție a indexului.
Când să folosiți reorganizarea indexului și când să reconstruiți?
Pentru a răspunde la această întrebare, mai întâi trebuie să determinați gradul de fragmentare a indexului, deoarece în funcție de fragmentarea indexului, una sau alta metodă de defragmentare va fi de preferat și eficientă. Puteți utiliza funcția tabelului de sistem pentru a determina gradul de fragmentare a unui indice sys.dm_db_index_physical_statscare returnează informații detaliate despre mărimea și fragmentarea indexurilor. De exemplu, folosind următoarea interogare, puteți afla gradul de fragmentare a indexului pentru toate tabelele din baza de date curentă.
SELECT OBJECT_NAME (T1.object_id) AS NameTable, T1.index_id AS IndexId, T2.name AS IndexName, T1.avg_fragmentation_in_percent AS Fragmentare din sys.dm_db_index_physical_stats (DB_ID (), NULL, NULL), AS TULL, NULL) indexează AS T2 ON T1.object_id \u003d T2.object_id AND T1.index_id \u003d T2.index_id
În acest caz, ne interesează coloana avg_fragmentation_in_percent, adică procentul de fragmentare logică.
- Dacă rata de fragmentare este mai mică de 5%, atunci reorganizarea sau reconstruirea indicelui nu ar trebui să fie executată deloc;
- Dacă gradul de fragmentare este de la 5 la 30%, atunci are sens să începeți reorganizarea indexului, deoarece această operațiune folosește resurse de sistem minime și nu necesită blocări pe termen lung;
- Dacă gradul de fragmentare este mai mare de 30%, atunci este necesară reconstruirea indexului, deoarece această operație, cu fragmentare semnificativă, are un efect mai mare decât operarea reorganizării indexului.
Personal, pot adăuga următoarele, dacă aveți o companie mică și baza de date nu necesită eficiență maximă 24 de ore pe zi, adică. Deoarece nu este o bază de date super-activă, puteți efectua periodic o operație de reconstrucție a indexului fără a determina chiar gradul de fragmentare.
Reorganizarea indexurilor
Reorganizarea indexului Este un proces de defragmentare a indexului care defragmentează nivelul frunzelor de indexuri grupate și neincluse în tabele și vizualizări, reordonând fizic paginile la nivel de frunze în conformitate cu ordinea logică ( de la stanga la dreapta) noduri terminale.
Puteți utiliza atât instrumentul SSMS grafic cât și o instrucțiune Transact-SQL pentru a reorganiza indexul.
Reorganizarea unui index folosind Management Studio

Reorganizarea unui index folosind Transact-SQL
ALTER INDEX IX_NonClustered ON TestTable REORGANIZE GO
Reconstruirea indexurilor
Reconstrucția indexului Este procesul prin care se șterge indicele vechi și se creează unul nou, ca urmare a eliminării fragmentării.
Puteți utiliza două metode pentru a reconstrui indexuri.
Primul. Utilizarea instrucțiunii ALTER INDEX cu clauza REBUILD. Această declarație înlocuiește instrucțiunea DBCC DBREINDEX. În mod obișnuit, aceasta este metoda folosită pentru a reconstrui în masă indicii.
Exemplu
ALTER INDEX IX_NonClustered ON TestTable REBUILD GO
Și în al doilea rând, folosind instrucțiunea CREATE INDEX cu clauza DROP_EXISTING. Poate fi folosit, de exemplu, pentru a reconstrui un index cu o modificare a definiției sale, adică. adăugarea sau eliminarea coloanelor cheie.
Exemplu
CREAȚI INDEX NONCLUSTERED IX_NonClustered ON TestTable (CategoryID ASC) CU (DROP_EXISTING \u003d ON) GO
Funcționalitatea de reconstruire este disponibilă și în Studio Studio. Faceți clic dreapta pe indicele dorit " Reconstrui».

Acest lucru concluzionează materialul de bază a indexurilor din Microsoft SQL Server, dacă sunteți interesat de limbajul T-SQL, atunci vă recomand să citiți cartea mea „



