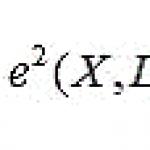1. Direkt användning av uppgifterna, eller datalagring.
I detta fall lagras de initiala uppgifterna i en uttryckligen detaljerad form och används direkt i stadier och/eller tolka undantag... Problemet med denna grupp av metoder är att när man använder dem kan det vara svårt att analysera mycket stora databaser.
Metoder för denna grupp: klusteranalys, närmaste granne-metod, k-närmaste granne-metod, resonemang genom analogi.
2. Identifiering och användning av formaliserade mönster, eller destillationsmallar.
Med teknik destillationsmallar ett prov (mall) av information extraheras från den initiala datan och omvandlas till några formella konstruktioner, vars form beror på vilken Data Mining-metod som används. Denna process utförs på scenen fri sökning, den första gruppen av metoder har i princip inte detta stadium. I etapper prediktiv modellering och tolka undantag resultat från scenen används fri sökning, de är mycket mer kompakta än själva databaserna. Låt oss komma ihåg att konstruktionerna av dessa modeller kan tolkas av analytikern eller ospåras ("svarta lådor").
Metoder i denna grupp: logiska metoder; visualiseringsmetoder; korstabuleringsmetoder; metoder baserade på ekvationer.
Logiska metoder, eller metoder för logisk induktion, inkluderar: suddiga frågor och analyser; symboliska regler; beslutsträd; genetiska algoritmer.
Metoderna för denna grupp är kanske de mest tolkbara - de formaliserar de hittade mönstren, i de flesta fall i en ganska transparent form ur användarens synvinkel. De resulterande reglerna kan inkludera kontinuerliga och diskreta variabler. Det bör noteras att beslutsträd enkelt kan konverteras till symboliska regeluppsättningar genom att generera en regel längs vägen från trädets rot till dess terminal topp... Beslutsträd och regler är faktiskt olika sätt att lösa ett problem och skiljer sig bara åt i deras förmåga. Dessutom genomförs implementeringen av reglerna av långsammare algoritmer än induktion av beslutsträd.
Korstabellmetoder: agenter, Bayesianska (förtroende) nätverk, tvärtabellvisualisering. Den sista metoden motsvarar inte riktigt en av egenskaperna hos Data Mining - oberoende sökning mönster analytiskt system. Men tillhandahållandet av information i form av korstabeller säkerställer genomförandet av huvuduppgiften för Data Mining - sökandet efter mönster, därför kan denna metod också betraktas som en av Data Mining-metoderna.
Ekvationsbaserade metoder.
Metoderna i denna grupp uttrycker de avslöjade mönstren i form av matematiska uttryck - ekvationer. Därför kan de bara fungera med numeriska variabler, och variabler av andra typer måste kodas därefter. Detta begränsar till viss del tillämpningen av metoderna för denna grupp, men de används i stor utsträckning för att lösa olika problem, särskilt prognosproblem.
De huvudsakliga metoderna för denna grupp: statistiska metoder och neurala nätverk
Statistiska metoder används oftast för att lösa prognosproblem. Det finns många metoder för statistisk dataanalys, bland dem, till exempel korrelations-regressionsanalys, korrelation av tidsserier, identifiering av trender i tidsserier, harmonisk analys.
En annan klassificering delar in hela mängden datautvinningsmetoder i två grupper: statistiska och cybernetiska metoder. Detta uppdelningsschema är baserat på olika tillvägagångssätt för att lära ut matematiska modeller.
Det bör noteras att det finns två metoder för att klassificera statistiska metoder som Data Mining. Den första av dem kontrasterar statistiska metoder och Data Mining, dess anhängare anser att klassiska statistiska metoder är en separat riktning för dataanalys. Enligt det andra tillvägagångssättet är statistiska analysmetoder en del av Data Mining matematiska verktygslåda. De flesta välrenommerade källor använder det andra tillvägagångssättet.
I denna klassificering särskiljs två grupper av metoder:
- statistiska metoder baserade på användning av genomsnittlig ackumulerad erfarenhet, vilket återspeglas i retrospektiva data;
- cybernetiska metoder, som inkluderar många heterogena matematiska tillvägagångssätt.
Nackdelen med en sådan klassificering: både statistiska och cybernetiska algoritmer på ett eller annat sätt förlitar sig på jämförelsen av statistisk erfarenhet med resultaten av övervakningen av den nuvarande situationen.
Fördelen med denna klassificering är dess bekvämlighet för tolkning - den används för att beskriva de matematiska verktygen för det moderna förhållningssättet till kunskapsutvinning från uppsättningar av initiala observationer (operativa och retrospektiva), dvs. i Data Mining-uppgifter.
Låt oss ta en närmare titt på grupperna som presenteras ovan.
Statistiska datautvinningsmetoder
Metoderna representerar fyra inbördes relaterade avsnitt:
- preliminär analys av arten av statistiska data (testning av hypoteser om stationaritet, normalitet, oberoende, homogenitet, bedömning av distributionsfunktionens form, dess parametrar, etc.);
- identifiera länkar och mönster(linjär och olinjär regressionsanalys, korrelationsanalys, etc.);
- multivariat statistisk analys (linjär och icke-linjär diskriminantanalys, klusteranalys, komponentanalys, faktoranalys och så vidare.);
- dynamiska modeller och tidsserieprognos.
Arsenalen av statistiska metoder Data Mining klassificeras i fyra grupper av metoder:
- Beskrivande analys och beskrivning av initialdata.
- Relationsanalys (korrelations- och regressionsanalys, faktoranalys, variansanalys).
- Multivariat statistisk analys (komponentanalys, diskriminantanalys, multivariat regressionsanalys, kanoniska korrelationer, etc.).
- Tidsserieanalys ( dynamiska modeller och prognoser).
Cybernetiska metoder för datautvinning
Den andra riktningen för Data Mining är en uppsättning tillvägagångssätt som förenas av idén om datormatematik och användningen av teorin om artificiell intelligens.
data mining) och om "grov" utforskande analys, som utgör grunden för online analytisk bearbetning (OnLine Analytical Processing, OLAP), medan en av huvudbestämmelserna i Data Mining är sökandet efter icke-uppenbara mönster... Data Mining-verktyg kan hitta sådana mönster på egen hand och även självständigt forma hypoteser om relationer. Eftersom det är formuleringen av en hypotes om beroenden som är den svåraste uppgiften är fördelen med Data Mining i jämförelse med andra analysmetoder uppenbar.De flesta statistiska metoder för att identifiera samband i data använder begreppet medelvärde över ett urval, vilket leder till operationer på obefintliga värden, medan Data Mining arbetar på verkliga värden.
OLAP är mer lämpad för att förstå historisk data, Data Mining förlitar sig på historisk data för att svara på frågor om framtiden.
Data Mining Technology Perspectives
Data Minings potential ger grönt ljus för att tänja på teknikens gränser. När det gäller utsikterna för Data Mining är följande utvecklingsriktningar möjliga:
- identifiering av typerna av ämnesområden med motsvarande heuristik, vars formalisering kommer att underlätta lösningen av motsvarande datautvinningsproblem relaterade till dessa områden;
- skapandet av formella språk och logiska medel, med hjälp av vilka resonemang kommer att formaliseras och vars automatisering kommer att bli ett verktyg för att lösa datautvinningsproblem inom specifika ämnesområden;
- Skapande av Data Mining-metoder som inte bara kan extrahera mönster från data, utan också bilda några teorier baserade på empirisk data;
- övervinna en betydande klyfta mellan datautvinningsverktygens kapacitet och teoretiska framsteg inom detta område.
Om vi betraktar framtiden för Data Mining på kort sikt, så är det uppenbart att utvecklingen av denna teknologi är mest inriktad mot områden som är relaterade till affärer.
På kort sikt kan Data Mining-produkter bli lika vanliga och väsentliga som e-post och till exempel användas av användare för att hitta de lägsta priserna för en viss produkt eller de billigaste biljetterna.
På lång sikt är framtiden för Data Mining verkligen spännande - det kan vara ett sökande av intelligenta agenter efter både nya behandlingar för olika sjukdomar och en ny förståelse av universums natur.
Data Mining är dock fylld av potentiella faror - trots allt blir en ökande mängd information tillgänglig via det världsomspännande nätverket, inklusive privat information, och mer och mer kunskap kan erhållas från den:
För inte så länge sedan var den största nätbutiken "Amazon" i centrum för en skandal över patentet "Metoder och system för att hjälpa användare att köpa varor", vilket inte är något annat än en annan Data Mining-produkt utformad för att samla in personlig information om butiken besökare. Den nya metoden gör det möjligt att förutsäga framtida förfrågningar baserat på fakta om köp, samt dra slutsatser om deras syfte. Syftet med denna teknik är, som nämnts ovan, att få så mycket information som möjligt om klienter, inklusive av privat karaktär (kön, ålder, preferenser, etc.). På så sätt samlas data in om butiksköparnas integritet, såväl som deras familjemedlemmar, inklusive barn. Det senare är förbjudet enligt lagstiftningen i många länder - insamling av information om minderåriga är endast möjlig där med tillstånd från föräldrarna.
Forskning konstaterar att det finns både framgångsrika lösningar som använder Data Mining och dåliga erfarenheter av denna teknik. De områden där datautvinningsteknik är mest sannolikt att vara framgångsrik har följande funktioner:
- kräver kunskapsbaserade lösningar;
- ha en föränderlig miljö;
- ha tillgängliga, tillräckliga och meningsfulla uppgifter;
- ge hög utdelning från rätt beslut.
Befintliga metoder för analys
Under lång tid var Data Mining-disciplinen inte erkänd som ett fullfjädrat oberoende område för dataanalys, ibland kallas det "statistikens bakgård" (Pregibon, 1997).
Hittills har flera synpunkter på Data Mining fastställts. Anhängare av en av dem anser att det är en hägring som distraherar uppmärksamheten från klassisk analys.
Ministeriet för utbildning och vetenskap i Ryska federationen
Federal State Budgetary Educational Institute of Higher Professional Education
"NATIONAL FORSKNING TOMSK POLYTECHNICAL UNIVERSITY"
Institutet för cybernetik
Inriktning Informatik och datateknik
Institutionen för VT
Testa
inom disciplinen informatik och datateknik
Ämne: Datautvinningsmetoder
Introduktion
Data Mining. Grundläggande begrepp och definitioner
1 Steg i datautvinningsprocessen
2 Komponenter i gruvsystem
3 Metoder för datautvinning i datautvinning
Datautvinningsmetoder
1 Härledning av föreningsregler
2 Neurala nätverksalgoritmer
3 Närmaste granne och k-Närmaste granne metoder
4 Beslutsträd
5 klustringsalgoritmer
6 genetiska algoritmer
Ansökningar
Tillverkare av verktyg för datautvinning
Kritik av metoder
Slutsats
Bibliografi
Introduktion
Resultatet av utvecklingen av informationsteknologi är en kolossal mängd data som ackumuleras i elektronisk form, som växer i snabb takt. Dessutom har data som regel en heterogen struktur (texter, bilder, ljud, video, hypertextdokument, relationsdatabaser). Data som ackumuleras under en lång tidsperiod kan innehålla mönster, trender och samband, som är värdefull information vid planering, prognoser, beslutsfattande och processkontroll. Men en person är fysiskt oförmögen att effektivt analysera sådana volymer av heterogen data. Metoder för traditionell matematisk statistik har länge gjort anspråk på att vara det främsta verktyget för dataanalys. De tillåter dock inte att syntetisera nya hypoteser, utan kan endast användas för att bekräfta tidigare formulerade hypoteser och ”grov” utforskande analys, som ligger till grund för online analytisk bearbetning (OLAP). Ofta är det formuleringen av en hypotes som visar sig vara den svåraste uppgiften när man gör analys för efterföljande beslutsfattande, eftersom inte alla mönster i data är uppenbara vid första anblicken. Därför betraktas datautvinningsteknologier som ett av de viktigaste och mest lovande ämnena för forskning och tillämpning inom informationsteknologibranschen. I detta fall avser datautvinning processen att fastställa ny, korrekt och potentiellt användbar kunskap baserad på stora mängder data. Således beskrev MIT Technology Review Data Mining som en av tio framväxande teknologier som kommer att förändra världen.
1. Data Mining. Grundläggande begrepp och definitioner
Data Mining är en process för att upptäcka tidigare okänd, icke-trivial, praktiskt användbar och tillgänglig tolkning av kunskap i "rå" data, som är nödvändig för att fatta beslut inom olika sfärer av mänsklig aktivitet.
Kärnan och syftet med Data Mining-teknologi kan formuleras på följande sätt: det är en teknik som är designad för att söka i stora mängder data efter icke-uppenbara, objektiva och användbara i praktiken mönster.
Icke-uppenbara mönster är mönster som inte kan upptäckas med standardmetoder för informationsbehandling eller genom expertråd.
Objektiva regelbundenheter bör förstås som regelbundenheter som helt överensstämmer med verkligheten, till skillnad från expertutlåtanden, som alltid är subjektiv.
Detta dataanalyskoncept förutsätter att:
§ data kan vara felaktiga, ofullständiga (innehålla luckor), motsägelsefulla, heterogena, indirekta och samtidigt ha gigantiska volymer; därför kräver förståelse av data i specifika tillämpningar betydande intellektuell ansträngning;
§ själva algoritmerna för dataanalys kan ha "inslag av intelligens", i synnerhet förmågan att lära av prejudikat, det vill säga att dra allmänna slutsatser baserade på privata observationer; utvecklingen av sådana algoritmer kräver också betydande intellektuell ansträngning;
§ Processerna att bearbeta rådata till information och information till kunskap kan inte utföras manuellt och kräver automatisering.
Data Mining-tekniken är baserad på konceptet med mönster (mönster) som återspeglar fragment av multidimensionella relationer i data. Dessa mönster representerar mönster som är inneboende i delprover av data som kan uttryckas kompakt i en läsbar form.
Sökandet efter mönster utförs med metoder som inte är begränsade av ramen för a priori antaganden om strukturen hos provet och typen av fördelningar av värdena för de analyserade indikatorerna.
En viktig egenskap hos Data Mining är att de sökta mönstren inte är standard och inte är självklara. Med andra ord skiljer sig Data Mining-verktyg från statistiska databearbetningsverktyg och OLAP-verktyg genom att istället för att kontrollera de ömsesidiga beroenden som antagits av användare i förväg, kan de hitta sådana ömsesidiga beroenden på egen hand baserat på tillgänglig data och bygga hypoteser om deras natur . Det finns fem standardtyper av mönster som identifieras av Data Mining-metoder:
· Association - en hög sannolikhet för kopplingen av händelser med varandra. Ett exempel på en förening är varor i en butik som ofta köps ihop;
· Sekvens - en hög sannolikhet för en kedja av händelser relaterad i tid. Ett exempel på en sekvens är en situation där, inom en viss tid efter förvärvet av en produkt, en annan kommer att köpas med hög grad av sannolikhet;
· Klassificering - det finns tecken som kännetecknar den grupp som den eller den händelsen eller objektet tillhör;
· Clustering - ett mönster som liknar klassificering och skiljer sig från det genom att själva grupperna inte specificeras - de upptäcks automatiskt under databehandling;
· Tillfälliga mönster - förekomsten av mönster i dynamiken i beteendet hos vissa data. Ett typiskt exempel på ett tidsmönster är säsongsmässiga fluktuationer i efterfrågan på vissa varor eller tjänster.
1.1 Steg i datautvinningsprocessen
Traditionellt särskiljs följande steg i datautvinningsprocessen:
1. Studie av ämnesområdet, varvid huvudmålen för analysen formuleras.
2. Insamling av data.
Dataförbehandling:
a. Datarensning - eliminering av inkonsekvenser och slumpmässigt "brus" från originaldata
b. Dataintegration är konsolideringen av data från flera möjliga källor till ett enda arkiv. Datatransformation. I detta skede omvandlas data till en form som lämpar sig för analys. Dataaggregation, attributsampling, datakomprimering och dimensionsreduktion används ofta.
4. Dataanalys. Inom detta stadium används gruvalgoritmer för att extrahera mönster.
5. Tolkning av de hittade mönstren. Det här steget kan innefatta att visualisera de extraherade mönstren, identifiera riktigt användbara mönster baserat på någon hjälpfunktion.
Användning av ny kunskap.
1.2 Komponenter i gruvsystem
Vanligtvis har datautvinningssystem följande huvudkomponenter:
1. Databas, datalager eller annat informationsarkiv. Det kan vara en eller flera databaser, datalager, kalkylblad, andra sorters förråd som kan saneras och integreras.
2. Databasserver eller datalager. Den angivna servern ansvarar för att extrahera väsentlig data baserat på användarens begäran.
Kunskapsbas. Det är domänkunskap som indikerar hur man söker och utvärderar användbarheten av de resulterande mönstren.
Kunskapstjänst för gruvdrift. Det är en integrerad del av data mining-systemet och innehåller en uppsättning funktionsmoduler för uppgifter som karaktärisering, hitta associationer, klassificering, klusteranalys och variansanalys.
Mönsterutvärderingsmodul. Denna komponent beräknar mått på intresse eller användbarhet av mönster.
Grafiskt användargränssnitt. Denna modul ansvarar för kommunikationen mellan användaren och dataminingsystemet, visualisering av mönster i olika former.
1.3 Metoder för datautvinning i datautvinning
De flesta av de analysmetoder som används inom Data Mining-tekniken är välkända matematiska algoritmer och metoder. Nytt i deras tillämpning är möjligheten att använda dem för att lösa vissa specifika problem, på grund av de framväxande kapaciteterna hos hårdvara och mjukvara. Det bör noteras att de flesta av Data Mining-metoderna utvecklades inom ramen för teorin om artificiell intelligens. Låt oss överväga de mest använda metoderna:
Slutande av föreningsregler.
2. Neurala nätverksalgoritmer, vars idé är baserad på en analogi med nervvävnadens funktion och ligger i det faktum att de initiala parametrarna betraktas som signaler som omvandlas i enlighet med de befintliga kopplingarna mellan "neuroner", och svaret från hela nätverket betraktas som svaret som härrör från analysen av originaldata.
Val av en nära analog till initialdata från befintliga historiska data. Kallas även "närmaste granne"-metoden.
Beslutsträd är en hierarkisk struktur baserad på en uppsättning frågor som kräver ett "Ja" eller "Nej" svar.
Klustermodeller används för att gruppera liknande händelser i grupper baserat på liknande värden för flera fält i en datauppsättning.
I nästa kapitel kommer vi att beskriva ovanstående metoder mer i detalj.
2. Datautvinningsmetoder
2.1 Slutledning av föreningsregler
Föreningsregler är regler av formen "om ... då ...". Att söka efter sådana regler i en datauppsättning avslöjar dolda samband i till synes orelaterade data. Ett av de vanligaste exemplen på sökandet efter föreningsregler är problemet med att hitta stabila relationer i varukorgen. Utmaningen är att avgöra vilka varor som köps av kunder tillsammans så att marknadsförare kan placera dem på rätt sätt i butiken för att öka försäljningen.
Associationsregler definieras som uttalanden av formen (X1, X2, ..., Xn) -> Y, där det antas att Y kan vara närvarande i en transaktion, förutsatt att X1, X2, ..., Xn är närvarande i samma transaktion. Det bör noteras att ordet "kan" antyder att regeln inte är en identitet, utan bara gäller med viss sannolikhet. Dessutom kan Y vara en uppsättning objekt, snarare än bara ett objekt. Sannolikheten att hitta Y i en transaktion där det finns element X1, X2,..., Xn kallas konfidens. Andelen transaktioner som innehåller en regel av det totala antalet transaktioner kallas support. Den nivå av förtroende som en regel måste överskrida kallas intressanthet.
Det finns olika typer av föreningsregler. I sin enklaste form rapporterar föreningsregler endast närvaro eller frånvaro av en förening. Sådana regler kallas Boolean Association Rule. Ett exempel på en sådan regel skulle vara: "Kunder som köper yoghurt köper också smör med låg fetthalt."
Regler som sammanför flera associationsregler kallas Multilevel eller Generalized Association Rules. När man konstruerar sådana regler grupperas objekt vanligtvis enligt en hierarki och sökningar görs på högsta begreppsnivå. Till exempel "kunder som köper mjölk köper också bröd." I det här exemplet innehåller mjölk och bröd en hierarki av olika typer och märken, men sökning på bottennivån kommer inte att hitta intressanta regler.
En mer komplex typ av regel är Quantitative Association Rules. Den här typen av regel söks efter med kvantitativa (till exempel pris) eller kategoriska (till exempel kön) attribut, och definieras som (
Ovanstående regeltyper tar inte upp det faktum att transaktioner till sin natur är tidsberoende. Till exempel, sökning innan en produkt är listad för försäljning eller efter att den har försvunnit från marknaden kommer att påverka stödtröskeln negativt. Med detta i åtanke har konceptet med attributets livslängd i sökalgoritmer för Temporal Association Rules introducerats.
Problemet med att hitta associationsregler kan generellt delas upp i två delar: sökning efter ofta förekommande uppsättningar av element, och generering av regler baserat på de hittade ofta förekommande uppsättningarna. Till största delen har tidigare forskning följt dessa riktningar och utvidgat dem i olika riktningar.
Sedan tillkomsten av Apriori-algoritmen har denna algoritm varit den vanligaste i det första steget. Många förbättringar, till exempel i hastighet och skalbarhet, syftar till att förbättra Apriori-algoritmen, att korrigera dess felaktiga egenskap att generera för många kandidater för de vanligaste uppsättningarna av element. Apriori genererar artikeluppsättningar med endast de stora artikeluppsättningar som hittades i föregående steg, utan att ompröva transaktioner. Den modifierade AprioriTid-algoritmen förbättrar Apriori genom att endast använda databasen vid första passet. Beräkningarna i de efterföljande stegen använder endast de data som genererades i det första passet, vilket är mycket mindre än den ursprungliga databasen. Detta leder till enorma produktivitetsvinster. En ytterligare förbättrad version av algoritmen, kallad AprioriHybrid, kan erhållas genom att använda Apriori på de första passen, och sedan, vid senare pass, när de k:te kandidatuppsättningarna redan kan allokeras helt i datorns minne, byta till AprioriTid.
Ytterligare ansträngningar för att förbättra Apriori-algoritmen är relaterade till parallelliseringen av algoritmen (räknedistribution, datadistribution, kandidatdistribution, etc.), dess skalning (intelligent datadistribution, hybriddistribution), införandet av nya datastrukturer, såsom träd av ofta förekommande element (FP-tillväxt).
Det andra steget är mestadels autentiskt och intressant. Nya modifieringar lägger till dimensionen, kvaliteten och tidsmässiga stödet som beskrivs ovan till de traditionella booleska regelreglerna. En evolutionär algoritm används ofta för att hitta reglerna.
2.2 Neurala nätverksalgoritmer
Konstgjorda neurala nätverk dök upp som ett resultat av tillämpningen av en matematisk apparat för att studera hur det mänskliga nervsystemet fungerar för att reproducera det. Nämligen: nervsystemets förmåga att lära sig och rätta till fel, vilket borde göra det möjligt att simulera, om än ganska grovt, den mänskliga hjärnans arbete. Den huvudsakliga strukturella och funktionella delen av det neurala nätverket är den formella neuronen, som visas i fig. 1, där x0, x1, ..., xn är komponenterna i vektorn för ingångssignaler, w0, w1, ..., wn är värdena för vikterna av neurons insignaler, och y är utsignalen från neuronen.
Ris. 1. Formell neuron: synapser (1), adderare (2), transduktor (3).
En formell neuron består av 3 typer av element: synapser, adderare och transduktor. En synaps kännetecknar styrkan i sambandet mellan två neuroner.
Adderaren adderar ingångssignalerna förmultiplicerade med motsvarande vikter. Omvandlaren implementerar funktionen av ett argument - utdata från adderaren. Denna funktion kallas aktiveringsfunktionen eller neurons överföringsfunktion.
De formella neuronerna som beskrivs ovan kan kombineras på ett sådant sätt att utsignalerna från vissa neuroner matas in till andra. Den resulterande uppsättningen av sammankopplade neuroner kallas artificiella neurala nätverk (ANN), eller kort sagt neurala nätverk.
Det finns tre generella typer av neuroner, beroende på deras position i det neurala nätverket:
Ingångsneuroner, som tar emot ingångssignaler. Sådana neuroner, neuroner, har som regel en ingång med en enhetsvikt, det finns ingen bias, och värdet på utsignalen från neuronen är lika med ingångssignalen;
Utgångsneuroner (utgångsnoder), vars utgångsvärden representerar de resulterande utsignalerna från det neurala nätverket;
Dolda neuroner, som inte har direkta förbindelser med ingångssignalerna, medan värdena för utsignalerna från de dolda neuronerna inte är utsignalerna från ANN.
Enligt strukturen för internuronala anslutningar särskiljs två klasser av ANN:
ANN för direkt fortplantning, där signalen endast fortplantar sig från ingångsneuroner till utgående neuroner.
Återkommande ANN - ANN med feedback. I sådana ANN kan signaler överföras mellan alla neuroner, oavsett deras placering i ANN.
Det finns två allmänna sätt att lära ut ANN:
Lärande med en lärare.
Lärande utan lärare.
Övervakat lärande innebär användning av en fördefinierad uppsättning undervisningsexempel. Varje exempel innehåller en vektor av ingångssignaler och en motsvarande vektor av referensutgångssignaler, som beror på den aktuella uppgiften. Denna uppsättning kallas träningsset eller träningsset. Träningen av det neurala nätverket är inriktat på en sådan förändring av vikterna för ANN-anslutningarna, där värdet på ANN-utsignalerna skiljer sig så lite som möjligt från de erforderliga värdena för utsignalerna för en given ingångsvektor signaler.
Vid oövervakad inlärning justeras vikterna av anslutningar antingen som ett resultat av konkurrens mellan neuroner, eller med hänsyn till korrelationen av utsignalerna från neuroner mellan vilka det finns en koppling. Vid oövervakat lärande används inte träningsprovet.
Neurala nätverk används för att lösa en lång rad uppgifter, som att planera nyttolaster för rymdfärjor och förutsäga växelkurser. De används dock inte ofta i datautvinningssystem på grund av modellens komplexitet (kunskap som registrerats eftersom vikten av flera hundra interna kopplingar är helt bortom analys och tolkning av människor) och den långa träningstiden på ett stort träningsprov. Å andra sidan har neurala nätverk sådana fördelar för användning i dataanalysuppgifter som motstånd mot bullriga data och hög noggrannhet.
2.3 Metoder för närmaste granne och k-närmaste granne
Algoritmen för närmaste granne och k-närmaste granne-algoritmen (KNN) baseras på egenskapslikhet. Algoritmen för närmaste granne väljer ett objekt bland alla kända objekt som är så nära som möjligt (med hjälp av måtten för avståndet mellan objekt, till exempel euklidiskt) till ett nytt tidigare okänt objekt. Det största problemet med metoden närmaste granne är dess känslighet för extremvärden i träningsdata.
Det beskrivna problemet kan undvikas med KNN-algoritmen, som särskiljer från alla observationer redan k-närmaste grannar som liknar ett nytt objekt. Utifrån de närmaste grannarnas klasser tas beslut om det nya objektet. En viktig uppgift för denna algoritm är att välja koefficienten k - antalet poster som kommer att anses vara lika. En modifiering av algoritmen, där bidraget från en granne är proportionellt mot avståndet till det nya objektet (metoden för k-vägda närmaste grannar) gör det möjligt att uppnå större klassificeringsnoggrannhet. Metoden k närmaste grannar låter oss också uppskatta prognosens noggrannhet. Till exempel, alla k närmaste grannar har samma klass, då är sannolikheten att det markerade objektet kommer att ha samma klass mycket hög.
Bland funktionerna i algoritmen är det värt att notera motståndet mot onormala utbrott, eftersom sannolikheten för att ett sådant rekord faller in i antalet k-närmaste grannar är liten. Om detta hände, är inflytandet på röstningen (särskilt viktat) (för k> 2) sannolikt också obetydligt, och därför kommer inflytandet på klassificeringsresultatet också att vara litet. Fördelarna är också enkel implementering, enkel tolkning av resultatet av algoritmen, möjligheten att modifiera algoritmen genom att använda de mest lämpliga kombinationsfunktionerna och mätvärdena, vilket gör att du kan justera algoritmen för en specifik uppgift. KNN-algoritmen har också ett antal nackdelar. För det första måste datauppsättningen som används för algoritmen vara representativ. För det andra kan modellen inte separeras från data: alla exempel måste användas för att klassificera ett nytt exempel. Denna funktion begränsar kraftigt användningen av algoritmen.
2.4 Beslutsträd
Med termen "beslutsträd" menas en familj av algoritmer baserade på representation av klassificeringsregler i en hierarkisk, sekventiell struktur. Detta är den mest populära klassen av algoritmer för att lösa datautvinningsproblem.
En familj av algoritmer för att konstruera beslutsträd gör det möjligt att förutsäga värdet av en parameter för ett givet fall baserat på en stor mängd data om andra liknande fall. Vanligtvis används algoritmer av denna familj för att lösa problem som gör det möjligt att dela upp all källdata i flera diskreta grupper.
När algoritmer för att konstruera beslutsträd tillämpas på en uppsättning indata, visas resultatet i form av ett träd. Sådana algoritmer tillåter flera nivåer av en sådan uppdelning, och delar upp de resulterande grupperna (trädgrenar) i mindre baserat på andra funktioner. Uppdelningen fortsätter tills värdena som är tänkta att förutsägas blir desamma (eller, i fallet med ett kontinuerligt värde på den förutsagda parametern, nära) för alla erhållna grupper (trädet i trädet). Det är dessa värden som används för att göra förutsägelser baserade på denna modell.
Funktionen av algoritmer för att konstruera beslutsträd är baserad på tillämpningen av metoder för regression och korrelationsanalys. En av de mest populära algoritmerna i denna familj är CART (Classification and Regression Trees), baserad på att dela upp data i en trädgren i två undergrenar; i detta fall beror den ytterligare uppdelningen av en eller annan gren på hur mycket av den initiala datan som beskrivs av denna gren. Flera andra liknande algoritmer låter dig dela upp en gren i fler underordnade grenar. I detta fall görs divisionen på basis av den högsta korrelationskoefficienten för den beskrivna datagrenen mellan parametern enligt vilken divisionen sker och parametern som ska förutsägas i framtiden.
Tillvägagångssättets popularitet är förknippat med klarhet och tydlighet. Men beslutsträd kan i grunden inte hitta de "bästa" (mest kompletta och korrekta) reglerna i data. De implementerar den naiva principen om sekventiell visning av funktioner och hittar faktiskt delar av verkliga mönster, vilket bara skapar en illusion av en logisk slutsats.
2.5 Klustringsalgoritmer
Klustring är uppgiften att bryta ner en uppsättning objekt i grupper som kallas kluster. Den största skillnaden mellan klustring och klassificering är att listan över grupper inte är tydligt specificerad och bestäms under driften av algoritmen.
Tillämpningen av klusteranalys i allmänhet reduceras till följande steg:
· Val av ett urval av objekt för klustring;
· Bestämning av den uppsättning variabler som objekten i provet kommer att utvärderas med. Om det behövs, normalisera värdena för variabler;
· Beräkning av värden för måttet på likhet mellan objekt;
· Tillämpning av metoden för klusteranalys för att skapa grupper av liknande objekt (kluster);
· Presentation av analysresultat.
Efter att ha erhållit och analyserat resultaten är det möjligt att justera den valda metriken och klustringsmetoden tills det optimala resultatet erhålls.
Bland klustringsalgoritmer urskiljs hierarkiska och platta grupper. Hierarkiska algoritmer (även kallade taxonomialgoritmer) bygger inte en partition av ett prov till disjunkta kluster, utan ett system av kapslade partitioner. Algoritmens utdata är således ett träd av kluster, vars rot är hela provet, och löven är de minsta klustren. Platta algoritmer bygger upp en partition av objekt till osammanhängande kluster.
En annan klassificering av klustringsalgoritmer är i tydliga och otydliga algoritmer. Tydliga (eller icke-överlappande) algoritmer tilldelar ett klusternummer till varje exempelobjekt, det vill säga varje objekt tillhör endast ett kluster. Luddiga (eller överlappande) algoritmer associerar varje objekt med en uppsättning verkliga värden som visar graden av objektets relation till kluster. Varje objekt tillhör alltså varje kluster med viss sannolikhet.
Bland hierarkiska klustringsalgoritmer finns det två huvudtyper: bottom-up och top-down algoritmer. Top-down-algoritmer fungerar enligt top-down-principen: först placeras alla objekt i ett kluster, som sedan delas upp i mindre och mindre kluster. Bottom-up-algoritmer är vanligare, som i början av arbetet placerar varje objekt i ett separat kluster och sedan kombinerar klustren till större och större tills alla objekt i provet finns i ett kluster. Således konstrueras ett system av kapslade partitioner. Resultaten av sådana algoritmer presenteras vanligtvis i form av ett träd.
Nackdelen med hierarkiska algoritmer är systemet med fullständiga partitioner, som kan vara redundanta i samband med att problemet löses.
Överväg nu platta algoritmer. De enklaste bland denna klass är kvadratiska algoritmer. Klustringsproblemet för dessa algoritmer kan betraktas som att konstruera en optimal uppdelning av objekt i grupper. I det här fallet kan optimaliteten definieras som kravet på att minimera medelkvadratfelet för partitionen:
 ,
,
var c j - "massacentrum" för klustret j(punkt med genomsnittliga värden för egenskaper för ett givet kluster).
Den vanligaste algoritmen i denna kategori är k-medelmetoden. Denna algoritm bygger ett givet antal kluster placerade så långt ifrån varandra som möjligt. Funktionen av algoritmen är uppdelad i flera steg:
Välj slumpmässigt k punkter som är de initiala "masscentrumen" för klustren.
2. Tilldela varje objekt till klustret med närmaste "massacentrum".
Om kriteriet för att stoppa algoritmen inte är uppfyllt, återgå till punkt 2.
Som ett kriterium för att stoppa driften av algoritmen väljs vanligtvis den minsta ändringen i rotmedelkvadratfelet. Det är också möjligt att stoppa driften av algoritmen om i steg 2 inga objekt flyttades från kluster till kluster. Nackdelarna med denna algoritm inkluderar behovet av att specificera antalet kluster för partitionering.
Den mest populära fuzzy klustringsalgoritmen är c-means-algoritmen. Det är en modifiering av k-medelmetoden. Algoritmsteg:
1. Välj en initial fuzzy partition n föremål på k kluster genom att välja medlemsmatrisen U storlek n x k.
2. Använd matrisen U för att hitta värdet för det luddiga felkriteriet:
 ,
,
var c k - "massacentrum" för ett suddigt kluster k:
3. Gruppera om objekt för att minska detta värde på kriteriet för luddigt fel.
4. Gå tillbaka till steg 2 tills matrisen ändras U kommer inte att bli obetydlig.
Denna algoritm kanske inte fungerar om antalet kluster är okänt i förväg, eller om det är nödvändigt att entydigt tilldela varje objekt till ett kluster.
Nästa grupp av algoritmer är algoritmer baserade på grafteori. Kärnan i sådana algoritmer är att ett urval av objekt representeras i form av en graf G = (V, E), vars hörn motsvarar föremål, och kanterna har en vikt lika med "avståndet" mellan föremålen. Fördelarna med grafklustringsalgoritmer är tydlighet, relativ enkel implementering och möjligheten att göra olika förbättringar utifrån geometriska överväganden. De huvudsakliga algoritmerna är algoritmen för att extrahera anslutna komponenter, algoritmen för att konstruera det minsta spännträdet och lager-för-lager-klustringsalgoritmen.
För att välja en parameter R vanligtvis ritas ett histogram av parvisa avståndsfördelningar. I problem med en väl uttalad klusterstruktur av data kommer histogrammet att ha två toppar - en motsvarar avstånd inom kluster, den andra - avstånd mellan kluster. Parameter R väljs från zonen för minimum mellan dessa toppar. Samtidigt är det ganska svårt att kontrollera antalet kluster med hjälp av avståndströskeln.
Algoritmen för minsta överspänningsträd konstruerar först det minsta överspänningsträdet på grafen och tar sedan sekventiellt bort kanterna med den högsta vikten. Lager-för-lager-klustringsalgoritmen är baserad på valet av sammankopplade komponenter i grafen på en viss nivå av avstånd mellan objekt (vertices). Avståndsnivån ställs in av avståndströskeln c... Till exempel, om avståndet mellan objekt, då.
Lager-för-lager-klustringsalgoritmen bildar en sekvens av grafer G som återspeglar hierarkiska relationer mellan kluster:
![]() ,
,
var G t = (V, E t )
- graf på nivån med t, ![]() ,
,
med t är den t:e tröskeln för avståndet, m är antalet hierarkinivåer,
G 0 = (V, o), o är den tomma uppsättningen grafkanter som erhålls för t 0 = 1,
G m = G, det vill säga en graf över objekt utan begränsningar på avståndet (längden på grafens kanter), eftersom t m = 1.
Genom att ändra avståndströskelvärdena ( med 0 , …, med m), där 0 = med 0 < med 1 < …< med m = 1, är det möjligt att styra djupet av hierarkin för de resulterande klustren. Således kan lager-för-lager-klustringsalgoritmen skapa både platt och hierarkisk datapartitionering.
Clustering låter dig uppnå följande mål:
· Förbättrar förståelsen av data genom att identifiera strukturella grupper. Att dela in urvalet i grupper av liknande objekt gör det möjligt att förenkla ytterligare databearbetning och beslutsfattande genom att tillämpa sin egen analysmetod för varje kluster;
· Låter dig lagra data kompakt. För att göra detta, istället för att lagra hela provet, kan du lämna en typisk observation från varje kluster;
· Detektering av nya atypiska objekt som inte ingick i något kluster.
Vanligtvis används klustring som ett hjälpmedel för dataanalys.
2.6 Genetiska algoritmer
Genetiska algoritmer är bland de universella optimeringsmetoderna som tillåter att lösa problem av olika slag (kombinatoriska, allmänna problem med och utan begränsningar) och av varierande grad av komplexitet. Samtidigt kännetecknas genetiska algoritmer av möjligheten till både enstaka kriterier och multikriteriesökning i ett stort utrymme, vars landskap inte är jämnt.
Denna grupp av metoder använder en iterativ process av evolution av sekvensen av generationer av modeller, inklusive operationerna för selektion, mutation och korsning. I början av algoritmen bildas populationen slumpmässigt. För att bedöma kvaliteten på kodade lösningar används fitnessfunktionen, som är nödvändig för att beräkna konditionen för varje individ. Enligt resultaten av bedömningen av individer väljs de mest anpassade av dem ut för korsning. Som ett resultat av korsning av utvalda individer genom att använda den genetiska överkorsningsoperatorn skapas avkommor, vars genetiska information bildas som ett resultat av utbyte av kromosominformation mellan förälderindivider. Den skapade avkomman bildar en ny population, och en del av avkomman muterar, vilket uttrycks i en slumpmässig förändring i deras genotyper. Stadiet som inkluderar sekvensen "Befolkningsuppskattning" - "Utval" - "Korsning" - "Mutation" kallas en generation. Befolkningsutvecklingen består av en sekvens av sådana generationer.
Följande algoritmer för att välja individer för korsning särskiljs:
· Panmixia. Båda individerna som utgör föräldraparet är slumpmässigt utvalda från hela populationen. Varje individ kan bli medlem i flera par. Detta tillvägagångssätt är universellt, men effektiviteten av algoritmen minskar med en ökning av populationsstorleken.
· Urval. Individer med minst genomsnittlig kondition kan bli föräldrar. Detta tillvägagångssätt ger snabbare konvergens av algoritmen.
· Inavel. Metoden bygger på bildandet av ett par utifrån nära relation. Här förstås släktskap som avståndet mellan medlemmarna i befolkningen, både i betydelsen det geometriska avståndet för individer i parameterrummet och Heming-avståndet mellan genotyper. Därför görs en skillnad mellan genotypisk och fenotypisk inavel. Den första medlemmen av paret för korsning väljs slumpmässigt, och den andra, med större sannolikhet, kommer att vara individen så nära honom som möjligt. Inavel kan kännetecknas av egenskapen att söka koncentration i lokala noder, vilket faktiskt leder till uppdelningen av befolkningen i separata lokala grupper runt områden i landskapet som är misstänkta för extremum.
· Utavel. Bildande av ett par baserat på avlägsen relation, för de mest avlägsna individerna. Utavel syftar till att förhindra konvergens av algoritmen till redan hittade lösningar, vilket tvingar algoritmen att leta efter nya, outforskade områden.
Algoritmer för att bilda en ny population:
· Urval med förskjutning. Av alla individer med samma genotyper föredras de vars kondition är högre. Således uppnås två mål: de bäst hittade lösningarna med olika kromosomuppsättningar går inte förlorade, tillräcklig genetisk mångfald upprätthålls ständigt i befolkningen. Förflyttning bildar en ny population av långt liggande individer, istället för att individer grupperar sig kring den nuvarande lösningen. Denna metod används för multiextrema uppgifter.
· Elitval. Elitvalsmetoder säkerställer att de bästa medlemmarna i befolkningen garanterat överlever. Samtidigt går några av de bästa individerna in i nästa generation utan några förändringar. Den snabba konvergens som elitselektion ger kan kompenseras med en lämplig föräldraselektionsmetod. I detta fall används ofta utavel. Det är denna kombination av "utavel - elitval" som är en av de mest effektiva.
· Val av turneringar. Turneringsval implementerar n turneringar för att välja n individer. Varje turnering bygger på ett urval av k element från befolkningen och valet av den bästa individen bland dem. Det vanligaste turneringsvalet med k = 2.
En av de mest populära tillämpningarna av genetiska algoritmer inom området Data Mining är sökandet efter den mest optimala modellen (sök efter en algoritm som matchar specifikationerna för ett visst område). Genetiska algoritmer används främst för att optimera neurala nätverkstopologi och vikter. Men det är också möjligt att använda dem som ett oberoende verktyg.
3. Användningsområden
Data Mining-teknologi har ett riktigt brett utbud av applikationer, och är i själva verket en uppsättning universella verktyg för att analysera data av alla slag.
Marknadsföring
Ett av de tidigaste områdena där datautvinningsteknik användes var marknadsföring. Uppgiften som startade utvecklingen av Data Mining-metoder kallas varukorgsanalys.
Denna uppgift är att identifiera de produkter som köpare vill köpa tillsammans. Kunskap om varukorgen är nödvändig för reklamkampanjer, bildandet av personliga rekommendationer för kunder, utvecklingen av en strategi för att skapa lager av varor och metoder för deras layout i försäljningsområden.
Även inom marknadsföring löses sådana uppgifter som att bestämma målgruppen för en viss produkt för dess mer framgångsrika marknadsföring; en studie av tidsmönster som hjälper företag att fatta lagerbeslut; skapande av prediktiva modeller, som gör det möjligt för företag att känna igen arten av behoven hos olika kategorier av kunder med visst beteende; förutsäga kundlojalitet, vilket gör att du i förväg kan identifiera ögonblicket kunden lämnar när du analyserar hans beteende och eventuellt förhindra förlust av en värdefull kund.
Industri
En av de viktiga inriktningarna inom detta område är övervakning och kvalitetskontroll, där det med hjälp av analysverktyg är möjligt att förutsäga utrustningsfel, uppkomsten av felfunktioner och planera reparationsarbeten. Att förutsäga populariteten för vissa egenskaper och veta vilka egenskaper som vanligtvis beställs tillsammans hjälper till att optimera produktionen och orientera den efter konsumenternas verkliga behov.
Medicin
Inom medicin används dataanalys också ganska framgångsrikt. Ett exempel på uppgifter är analys av undersökningsresultat, diagnostik, jämförelse av effektiviteten av behandlingsmetoder och läkemedel, analys av sjukdomar och deras fördelning, identifiering av biverkningar. Data Mining-teknologier som associationsregler och sekventiella mönster har framgångsrikt använts för att identifiera kopplingar mellan läkemedelsintag och biverkningar.
Molekylär genetik och genteknik
Den kanske mest akuta och samtidigt tydliga uppgiften att upptäcka mönster i experimentella data är inom molekylär genetik och genteknik. Här formuleras det som en definition av markörer, som förstås som genetiska koder som styr vissa fenotypiska egenskaper hos en levande organism. Sådana koder kan innehålla hundratals, tusentals eller fler relaterade element. Resultatet av den analytiska analysen av data är också förhållandet mellan förändringar i DNA-sekvensen hos en person och risken för att utveckla olika sjukdomar, upptäckt av genetiska forskare.
Tillämpad kemi
Data Mining-metoder används också inom området tillämpad kemi. Här uppstår ofta frågan om att belysa egenskaperna hos den kemiska strukturen hos vissa föreningar som bestämmer deras egenskaper. Detta problem är särskilt relevant vid analys av komplexa kemiska föreningar, vars beskrivning inkluderar hundratals och tusentals strukturella element och deras bindningar.
Bekämpa brott
Datautvinningsverktyg har använts relativt nyligen för att säkerställa säkerhet, men praktiska resultat har redan erhållits som bekräftar effektiviteten av datautvinning på detta område. Schweiziska forskare har utvecklat ett system för att analysera protestaktivitet för att förutsäga framtida incidenter och ett system för att spåra nya cyberhot och hackares agerande i världen. Det senare systemet gör det möjligt att förutsäga cyberhot och andra informationssäkerhetsrisker. Datautvinningsmetoder används också framgångsrikt för att upptäcka kreditkortsbedrägerier. Genom att analysera tidigare transaktioner som senare visade sig vara bedrägliga identifierar banken några stereotyper av sådana bedrägerier.
Andra applikationer
· Riskanalys. Till exempel, genom att identifiera kombinationer av faktorer som är förknippade med utbetalda skador, kan försäkringsgivare minska sina ansvarsförluster. Det finns ett känt fall när ett stort försäkringsbolag i USA upptäckte att de belopp som betalades på utlåtanden från personer som är gifta var dubbelt så mycket som betalats på utlåtanden från ensamstående. Företaget har svarat på denna nya kunskap genom att revidera sin allmänna rabattpolicy för familjekunder.
· Meteorologi. Väderprognoser med hjälp av neurala nätverk, i synnerhet självorganiserande Kohonen-kartor används.
· Personalpolicy. Analysverktyg hjälper HR-tjänster att välja ut de mest framgångsrika kandidaterna baserat på analysen av deras CV-data, för att modellera egenskaperna hos idealiska medarbetare för en viss position.
4. Tillverkare av Data Mining Tools
Data Mining-verktyg hör traditionellt till dyra mjukvaruprodukter. Därför, tills nyligen, var de största konsumenterna av denna teknik banker, finans- och försäkringsbolag, stora handelsföretag, och huvuduppgifterna som krävde användningen av Data Mining var bedömningen av kredit- och försäkringsrisker och utvecklingen av marknadsföringspolicy, tariffplaner och andra principer för att arbeta med kunder. Under de senaste åren har situationen genomgått vissa förändringar: relativt billiga Data Mining-verktyg och till och med gratis distributionssystem har dykt upp på mjukvarumarknaden, vilket gjorde denna teknik tillgänglig för små och medelstora företag.
Bland de betalda verktygen och dataanalyssystemen är ledare SAS Institute (SAS Enterprise Miner), SPSS (SPSS, Clementine) och StatSoft (STATISTICA Data Miner). Ganska välkända är lösningar från Angoss (Angoss KnowledgeSTUDIO), IBM (IBM SPSS Modeler), Microsoft (Microsoft Analysis Services) och (Oracle) Oracle Data Mining.
Valet av gratis programvara är också varierat. Det finns både universella analysverktyg, såsom JHepWork, KNIME, Orange, RapidMiner, och specialiserade verktyg, till exempel Carrot2 - ett ramverk för klustring av textdata och sökresultat, Chemicalize.org - en lösning inom området tillämpad kemi, NLTK (Natural Language Toolkit) verktyg för bearbetning av naturligt språk.
5. Kritik mot metoder
Data Mining-resultat beror till stor del på nivån av dataförberedelser och inte på de "mirakulösa förmågorna" hos någon algoritm eller uppsättning algoritmer. Cirka 75 % av arbetet med Data Mining består av insamling av data, vilket görs redan innan analysverktyg används. Analfabet användning av verktyg kommer att leda till ett meningslöst slöseri med företagets potential, och ibland miljontals dollar.
Enligt Herb Edelstein, en världskänd expert inom Data Mining, Data Warehousing och CRM: "En nyligen genomförd studie av Two Crows visade att Data Mining fortfarande är i ett tidigt skede. Många organisationer är intresserade av denna teknik, men endast ett fåtal genomför sådana projekt aktivt. Vi lyckades ta reda på en annan viktig punkt: processen att implementera Data Mining i praktiken visar sig vara mer komplicerad än förväntat.Teamen rycktes med av myten att Data Mining-verktyg är enkla att använda. Det antas att det räcker att köra ett sådant verktyg på en terabyte-databas, och användbar information kommer omedelbart att visas. Faktum är att ett framgångsrikt Data Mining-projekt kräver en förståelse för essensen av aktiviteten, kunskap om data och verktyg, såväl som processen för dataanalys." Innan du använder Data Mining-tekniken är det därför nödvändigt att noggrant analysera de begränsningar som sätts av metoderna och de kritiska problem som är förknippade med den, samt att noggrant bedöma teknikens kapacitet. Kritiska frågor inkluderar följande:
1. Tekniken kan inte ge svar på frågor som inte har ställts. Det kan inte ersätta analytikern, utan ger honom bara ett kraftfullt verktyg för att underlätta och förbättra hans arbete.
2. Komplexiteten i utvecklingen och driften av Data Mining-applikationen.
Eftersom denna teknik är ett tvärvetenskapligt område, för att utveckla en applikation som inkluderar Data Mining, är det nödvändigt att involvera specialister från olika områden, samt att säkerställa deras interaktion av hög kvalitet.
3. Användarkvalifikationer.
Olika verktyg för datautvinning har olika grader av användarvänlighet och kräver vissa användarkvalifikationer. Därför måste programvaran överensstämma med användarens utbildningsnivå. Användningen av Data Mining bör vara oupplösligt kopplad till förbättringen av användarens kvalifikationer. Men det finns för närvarande få Data Mining-specialister som är väl insatta i affärsprocesser.
4. Extrahering av användbar information är omöjlig utan en god förståelse av kärnan i data.
Noggrant modellval och tolkning av de beroenden eller mönster som finns krävs. Att arbeta med sådana verktyg kräver därför ett nära samarbete mellan ämnesexperten och Data Mining-verktygsspecialisten. Stående modeller måste integreras intelligent i affärsprocesser för att kunna utvärdera och uppdatera modeller. Nyligen har Data Mining-system levererats som en del av data warehouse-teknik.
5. Komplexiteten i databeredningen.
Framgångsrik analys kräver dataförbehandling av hög kvalitet. Enligt analytiker och databasanvändare kan förbearbetningsprocessen ta upp till 80 % av hela Data Mining-processen.
För att tekniken ska fungera för sig själv kommer det alltså att ta mycket ansträngning och tid, som läggs på preliminär dataanalys, modellval och dess korrigering.
6. En stor andel falska, opålitliga eller värdelösa resultat.
Med hjälp av Data Mining-teknologier kan du hitta riktigt mycket värdefull information som kan ge en betydande fördel i vidare planering, förvaltning och beslutsfattande. Resultaten som erhålls med Data Mining-metoder innehåller dock ganska ofta falska och meningslösa slutsatser. Många experter hävdar att Data Mining-verktyg kan producera en enorm mängd statistiskt opålitliga resultat. För att minska andelen sådana resultat är det nödvändigt att kontrollera lämpligheten hos de erhållna modellerna på testdata. Det är dock omöjligt att helt undvika falska slutsatser.
7. Hög kostnad.
En kvalitetsprodukt är resultatet av betydande ansträngningar från utvecklarens sida. Därför anses Data Mining-mjukvara traditionellt vara en dyr mjukvaruprodukt.
8. Tillgång till tillräckligt representativa data.
Data Mining-verktyg, till skillnad från statistiska, kräver teoretiskt sett inte en strikt definierad mängd historisk data. Denna funktion kan orsaka upptäckt av felaktiga, falska modeller och, som ett resultat, antagande av felaktiga beslut baserat på dem. Det är nödvändigt att kontrollera den statistiska signifikansen av den upptäckta kunskapen.
neural nätverksalgoritm klustringsdatautvinning
Slutsats
En kort beskrivning av tillämpningsområdena ges och kritik mot Data Mining-tekniken och åsikter från experter på detta område ges.
Listalitteratur
1. Han och Micheline Kamber. Data Mining: Koncept och tekniker. Andra upplagan. - University of Illinois i Urbana-Champaign
Berry, Michael J. A. Data mining-tekniker: för marknadsföring, försäljning och kundrelationshantering - 2nd ed.
Siu Nin Lam. Upptäcka föreningsregler inom datautvinning. - Institutionen för datavetenskap University of Illinois i Urbana-Champaign
Skicka ditt goda arbete i kunskapsbasen är enkelt. Använd formuläret nedan
Studenter, doktorander, unga forskare som använder kunskapsbasen i sina studier och arbete kommer att vara er mycket tacksamma.
Liknande dokument
- analys av kundbanor från att besöka en webbplats till att köpa varor
- utvärdering av tjänsteeffektivitet, analys av fel på grund av brist på varor
- länka varor som är intressanta för besökare
- varukorgsanalys;
- skapa prediktiva modeller och klassificeringsmodeller för köpare och köpta varor;
- skapa kundprofiler;
- CRM, bedömning av kundlojalitet av olika kategorier, planering av lojalitetsprogram;
- tidsserieforskning och tidsberoende, belyser säsongsbetonade faktorer, utvärderar effektiviteten av kampanjer på ett stort antal verkliga data.
- kundklassificering baserad på nyckelegenskaper för samtal (frekvens, varaktighet etc.), SMS-frekvens;
- identifiera kundlojalitet;
- definition av bedrägeri m.m.
- riskanalys... Genom att identifiera kombinationer av faktorer förknippade med utbetalda skador kan försäkringsgivare minska sina ansvarsförluster. Det finns ett känt fall när ett försäkringsbolag fann att de belopp som betalades på anspråken från personer som är gifta var dubbelt så mycket som betalats på anspråken från ensamstående. Företaget har svarat med att revidera sin familjerabattpolicy.
- spårning av bedrägerier... Försäkringsbolag kan minska bedrägerierna genom att leta efter specifika stereotyper i anspråk som kännetecknar förhållandet mellan advokater, läkare och skadelidande.
Klassificering av DataMining-uppgifter. Skapande av rapporter och totaler. Data Miner-funktioner i Statistica. Klassificering, klustring och regressionsproblem. Analysverktyg Statistica Data Miner. Kärnan i problemet är sökandet efter föreningsregler. Analys av överlevnadsprediktorer.
terminsuppsats, tillagd 2011-05-19
Beskrivning av funktionaliteten hos Data Mining-teknologin som en process för att upptäcka okända data. Studie av system för slutledning av associativa regler och mekanismer för neurala nätverksalgoritmer. Beskrivning av klustringsalgoritmer och användningsområden för Data Mining.
test, tillagt 2013-06-14
Grunderna för klustring. Att använda Data Mining som ett sätt att "upptäcka kunskap i databaser". Val av klustringsalgoritmer. Hämta data från fjärrverkstadens databaslagring. Gruppering av elever och uppgifter.
Terminuppsats tillagd 2017-10-07
Data mining, utvecklingshistoria för data mining och kunskapsupptäckt. Tekniska element och metoder för datautvinning. Steg i kunskapsupptäckt. Ändrings- och avvikelsedetektering. Närliggande discipliner, informationssökning och textextraktion.
rapport tillagd 2012-06-16
Analys av de problem som uppstår vid tillämpning av klustringsmetoder och algoritmer. Grundläggande algoritmer för klustring. RapidMiner programvara som en miljö för maskininlärning och dataanalys. Bedömning av kvaliteten på klustring med Data Mining-metoder.
terminsuppsats, tillagd 2012-10-22
Förbättring av teknik för datainspelning och lagring. Specifika moderna krav på informationsdatabehandling. Konceptet med mönster som återspeglar fragment av flerdimensionella relationer i data i hjärtat av modern Data Mining-teknik.
test, tillagt 2010-02-09
Analys av användningen av neurala nätverk för att förutsäga situationen och fatta beslut på aktiemarknaden med hjälp av programvaran Trajan 3.0 för modellering av neurala nätverk. Konvertering av primärdata, tabeller. Ergonomisk programutvärdering.
avhandling, tillagd 2011-06-27
Svårigheter att använda evolutionära algoritmer. Bygga datorsystem baserade på principerna för naturligt urval. Nackdelar med genetiska algoritmer. Exempel på evolutionära algoritmer. Riktningar och avsnitt av evolutionär modellering.
Vi välkomnar dig till Data Mining Portal - en unik portal dedikerad till moderna Data Mining-metoder.
Data Mining-teknik är ett kraftfullt verktyg för modern affärsintelligens och datautvinning för att upptäcka dolda mönster och bygga prediktiva modeller. Data Mining eller kunskapsutvinning bygger inte på spekulativa resonemang, utan på verkliga data.

Ris. 1. Schema för Data Mining-applikation
Problemdefinition - Förklaring av problemet: dataklassificering, segmentering, bygga prediktiva modeller, prognoser.
Datainsamling och förberedelse - Datainsamling och förberedelse, rengöring, verifiering, radering av dubbletter av register.
Modellbyggnad - Modellbyggnad, noggrannhetsbedömning.
Knowledge Deployment - Tillämpning av en modell för att lösa ett givet problem.
Data Mining används för att genomföra storskaliga analytiska projekt inom företag, marknadsföring, internet, telekommunikation, industri, geologi, medicin, läkemedel och andra områden.
Data Mining låter dig starta processen att hitta signifikanta korrelationer och kopplingar som ett resultat av att sålla igenom en enorm mängd data med hjälp av moderna metoder för mönsterigenkänning och användning av unika analytiska teknologier, inklusive beslutsträd och klassificeringar, klustring, neurala nätverksmetoder , och andra.
En användare som först upptäckte tekniken för datautvinning är förvånad över överflöd av metoder och effektiva algoritmer som gör det möjligt att hitta metoder för att lösa svåra problem i samband med analys av stora mängder data.
Generellt sett kan Data Mining karakteriseras som en teknik utformad för att söka i stora mängder data. omöjligt, mål och praktiskt taget användbar mönster.
Data Mining bygger på effektiva metoder och algoritmer utvecklade för analys av ostrukturerad data av stor volym och dimension.
Nyckelpunkten är att högvolym, högdimensionell data verkar sakna struktur och samband. Målet med data mining-teknologi är att identifiera dessa strukturer och hitta mönster där kaos och godtycke vid första anblicken råder.
Här är en aktuell fallstudie av datautvinningstillämpningar inom läkemedels- och läkemedelsindustrin.
Läkemedelsinteraktioner är ett växande problem som modern sjukvård står inför.
Med tiden ökar antalet förskrivna läkemedel (receptfria och alla typer av kosttillskott), vilket gör det mer och mer sannolikt att läkemedelsinteraktioner kan orsaka allvarliga biverkningar som läkare och patienter inte känner till.
Detta område hör till postklinisk forskning, då ett läkemedel redan har lanserats på marknaden och används intensivt.
Kliniska prövningar avser bedömningen av ett läkemedels effektivitet, men tar inte hänsyn till detta läkemedels interaktioner med andra läkemedel på marknaden.
Forskare vid Stanford University i Kalifornien undersökte Food and Drug Administrations (FDA) databas över läkemedelsbiverkningar och fann att två vanligt använda läkemedel - antidepressiva läkemedlet paroxetin och pravastatin, som används för att sänka kolesterolnivåerna - ökar risken för att utveckla diabetes om de används tillsammans.
En studie som genomförde en liknande analys baserad på FDA-data identifierade 47 tidigare okända negativa interaktioner.
Detta är anmärkningsvärt, med förbehållet att många av de negativa effekterna som rapporterats av patienter inte upptäcks. Det är här onlinesökning kan göra sitt bästa.
Kommande Data Mining-kurser på StatSoft Data Analysis Academy 2020
Vi börjar vår bekantskap med Data Mining med hjälp av de underbara videorna från Academy of Data Analysis.
Se till att titta på våra videor så kommer du att förstå vad Data Mining är!
Video 1. Vad är Data Mining?
Video 2. Översikt över datautvinningsmetoder: beslutsträd, generaliserade prediktiva modeller, klustring och mycket mer
JavaScript är inaktiverat i din webbläsare
Innan vi startar ett forskningsprojekt måste vi organisera processen att hämta data från externa källor, nu ska vi visa hur detta går till.
Videon kommer att introducera dig till den unika tekniken STATISTIK Databasbearbetning och datautvinning på plats med verklig data.
Video 3. Ordningen för interaktion med databaser: grafiskt gränssnitt för att bygga SQL-frågor In-place databasbehandlingsteknologi
JavaScript är inaktiverat i din webbläsare
Vi tittar nu på interaktiva borrtekniker som är effektiva vid analys av prospekteringsdata. Begreppet borrning i sig speglar sambandet mellan Data Mining-teknik och geologisk prospektering.
Video 4. Interactive Drilling: Exploration and Graphical Techniques for Interactive Data Exploration
JavaScript är inaktiverat i din webbläsare
Nu kommer vi att bekanta oss med analysen av föreningar (associationsregler), dessa algoritmer låter dig hitta relationer som finns i verklig data. Nyckelpunkten är effektiviteten av algoritmer på stora mängder data.
Resultatet av länkanalysalgoritmer, till exempel Apriori-algoritmen, är att hitta länkregler för de objekt som studeras med en given tillförlitlighet, till exempel 80 %.
Inom geologi kan dessa algoritmer användas i explorativ analys av mineraler, till exempel hur egenskap A är associerad med egenskaper B och C.
Du kan hitta specifika exempel på sådana lösningar genom att följa våra länkar:
I detaljhandeln låter Apriori-algoritmen eller deras modifieringar dig undersöka förhållandet mellan olika produkter, till exempel när du säljer parfymer (parfym - lack - mascara, etc.) eller produkter av olika märken.
Analysen av de mest intressanta avsnitten på webbplatsen kan också effektivt utföras med hjälp av föreningarnas regler.
Så kolla in vår nästa video.
Video 5. Föreningens regler
JavaScript är inaktiverat i din webbläsare
Låt oss ge exempel på Data Mining-applikationer inom specifika områden.
Online handel:
Detaljhandel: Analysera kundinformation baserat på kreditkort, rabattkort och mer.
Typiska detaljhandelsuppgifter lösta med Data Mining-verktyg:
Telekommunikationssektorn öppnar för obegränsade möjligheter för tillämpningen av datautvinningsmetoder, såväl som modern big data-teknik:
Försäkring:
Den praktiska tillämpningen av datautvinning och att lösa specifika problem presenteras i vår nästa video.
Webbseminarium 1. Webbseminarium "Praktiska uppgifter för datautvinning: problem och lösningar"
JavaScript är inaktiverat i din webbläsareWebbseminarium 2. Webbseminarium "Data Mining och Text Mining: Exempel på att lösa verkliga problem"
JavaScript är inaktiverat i din webbläsare
Du kan få en djupare kunskap om datautvinningens metodik och teknik på StatSoft-kurser.