1) Pojam indeksa
Indeks Je alat koji omogućuje brz pristup redovima tablice na temelju vrijednosti jednog ili više stupaca.
Postoji puno raznolikosti u ovom operatoru, jer nije standardiziran, jer se standardi ne bave problemima performansi.
2) Izrada indeksa
USTVARITE INDEX
ON ()
3) Izmjena i brisanje indeksa
Sljedeći operator koristi se za kontrolu aktivnosti indeksa:
ALTER INDEX
Za brisanje indeksa koristite operatora:
DROP INDEX
a) Pravila za izbor tablice
1. Preporučljivo je indeksirati tablice u kojima nije odabrano više od 5% redaka.
2. Indeksne tablice koje nemaju duplikate u WHERE klauzuli SELECT izraza.
3. Nepraktično je indeksirati često ažurirane tablice.
4. Nepraktično je indeksirati tablice koje zauzimaju ne više od dvije stranice (za Oracle je manje od 300 redaka), jer njegovo potpuno skeniranje ne traje duže.
b) Pravila za izbor stupaca
1. Primarni i strani ključevi često se koriste za spajanje tablica, dohvaćanje podataka i pretraživanje. To su uvijek jedinstveni indeksi s maksimalnom korisnošću
2. Kada koristite referentne opcije integriteta, uvijek je potreban indeks FK.
3. Stupci po kojima se često vrši sortiranje i / ili grupiranje podataka.
4. Stupci za kojima se često pretražuje u WHERE klauzuli SELECT izjave.
5. Ne stvarajte indekse na dugim opisnim stupcima.
c) Načela za stvaranje složenih indeksa
1. Sastavljeni indeksi su dobri kada pojedini stupci imaju malo jedinstvenih vrijednosti, a složeni indeks daje više jedinstvenosti.
2. Ako sve vrijednosti odabrane izrazom SELECT pripadaju složenom indeksu, tada se vrijednosti uzimaju iz indeksa.
3. Napravite složeni indeks ako rečenica WHERE koristi dvije ili više vrijednosti u kombinaciji s operatorom AND.
d) Ne preporučuje se kreiranje
Ne preporučuje se kreiranje indeksa na stupcima, uključujući složene, koji:
1. Rijetko se koristi za pretraživanje, kombiniranje i sortiranje rezultata upita.
2. Sadrže često mijenjajuće vrijednosti, što zahtijeva često ažuriranje indeksa što usporava rad baze podataka.
3. Sadrže mali broj jedinstvenih vrijednosti (manji od 10% m / f) ili pretežni broj linija s jednom ili dvije vrijednosti (grad prebivališta dobavljača je Moskva).
4. Funkcija ili izraz primjenjuju se na njih u rečenici WHERE, a indeks ne radi.
e) Ne zaboravite
Trebali biste težiti smanjenju broja indeksa, jer velik broj njih usporava brzinu ažuriranja podataka. Tako MS SQL Server preporučuje kreiranje ne više od 16 indeksa po tablici.
Indeksi se obično stvaraju za upite i referentni integritet.
Ako se indeks ne koristi za upite, treba ga spustiti i referencijalni integritet treba nametnuti pomoću okidača.
Indeksi se koriste za brzi pristup redovima Oracle DBMS tablice. Indeksi omogućuju brzi pristup podacima tijekom operacija kada je odabran relativno mali broj redaka tablica.
Iako Oracle dopušta neograničeni broj indeksa na tablici, indeksi su korisni samo kada se koriste za ubrzanje upita. U suprotnom, oni zauzimaju prostor i usporavaju rad servera prilikom ažuriranja indeksiranih stupaca. Trebali biste upotrijebiti značajku PLAN OBRAZOVANJA (plan izvršenja i statistiku) da biste odredili kako se indeksi koriste u vašim upitima. Ponekad, ako se indeks ne koristi prema zadanom, možete upotrijebiti savjete za upotrebu indeksa.
Stvorite indekse nakon umetanja podataka tabele
Tipično umetate ili učitavate podatke u tablicu prije stvaranja indeksa. U suprotnom, režijski indeksi ažuriranja će usporiti operacije umetanja ili učitavanja. Jedini izuzetak od ovog pravila je indeks klasteriranog ključa. Može se stvoriti samo za prazan skup.
Prebacite se na privremene tablice kako biste izbjegli probleme sa slobodnim prostorom prilikom stvaranja indeksa
Prilikom izrade indeksa na tablici koja već sadrži podatke, Oracle zahtijeva dodatni prostor za pohranu za razvrstavanje. Ovo koristi područje memorije sortiranja dodijeljeno tvorcu indeksa (iznos dodijeljen svakom korisniku postavlja parametar inicijalizacije SORT_AREA_SIZE), osim toga, Oracle poslužitelj mora isprati i zamijeniti podatke iz privremenih segmenata dodijeljenih tijekom stvaranja indeksa. Ako je indeks vrlo velik, preporučuje se učiniti sljedeće:
- Stvorite novi privremeni prostor tablica pomoću izraza CREATE TABLESPACE.
- Navedite ovaj novi privremeni prostor u parametru TEMPORARY TABLESPACE u izjavi ALTER USER.
- Kreirajte indeks izjavom CREATE INDEX.
- Uništite ovaj prostor tablice naredbom DROP TABLESPACE. Zatim koristite izraz ALTER USER da biste vratili izvorni prostor tablice kao privremen.
Odaberite prave tablice i stupce za indeksiranje
Pomoću sljedećih smjernica odredite kada kreirati indeks.
- Napravite indeks ako često odaberete relativno mali (manje od 15%) broja redaka u velikoj tablici. Ovaj postotak uvelike ovisi o relativnoj brzini pretraživanja tablice i o tome kako su podaci o redovima grupirani u indeksnom ključu. Što je veća brzina pregledavanja, to je niži postotak, što je više podataka u nizu u nizu, to je veći postotak.
- Indeksni stupci koji se koriste u pridruživanjima za poboljšanje performansi spajanja više tablica.
- Indeksi se automatski kreiraju na osnovu primarnog i jedinstvenog ključa.
- Male tablice nije potrebno indeksirati. Ako primijetite da se vrijeme izvršenja upita značajno povećalo, onda je, najvjerovatnije, postalo veliko.
- vrijednosti u stupcu su relativno jedinstvene;
- veliki raspon vrijednosti (pogodno za uobičajene indekse);
- mali raspon vrijednosti (pogodno za bitove indekse);
- vrlo rijetki stupci (mnogi nedefinirani, "prazni" vrijednosti), ali upiti se uglavnom odnose na smislene redove. U ovom slučaju preferira se usporedba koja odgovara svim nulanim vrijednostima:
GDJE COL_X\u003e -9,99 * snaga (10, 125), a ne
GDJE COL_X NIJE NULL To je zato što prvi koristi indeks COL_X (pod pretpostavkom da je COL_X numerički stupac).
Ograničite broj indeksa za svaku tablicu
Što je više indeksa, to je veća pretplata kod promjene tablice. Kad se redovi dodaju ili izbrišu, ažuriraju se svi indeksi u tablici. Kada se stupac ažurira, moraju se ažurirati i svi indeksi u kojima ona sudjeluje.
U slučaju indeksa, morate uravnotežiti povećanje performansi upita u odnosu na degradaciju performansi tijekom ažuriranja. Na primjer, ako je tablica prije svega čitljiva, indeksi se mogu široko koristiti; međutim, ako se tablica često ažurira, korištenje indeksa trebalo bi svesti na najmanju moguću mjeru.
Odaberite Redoslijed kolona u kompozitnim indeksima
Iako se stupci mogu odrediti bilo kojim redoslijedom u izrazu CREATE INDEX, redoslijed stupaca u izrazu CREATE INDEX može utjecati na izvedbu upita. Općenito, stupci koji će se najčešće koristiti prvi su navedeni u indeksu. Možete stvoriti složeni indeks (koristeći više stupaca), takav indeks može se koristiti za upite u svim stupcima u ovom indeksu ili samo na nekim.
Prikupite statistiku za pravilnu upotrebu indeksa
Indeksi se mogu učinkovitije koristiti ako baza podataka prikuplja i održava statistiku o tablicama koje se koriste u upitima. Možete prikupiti statistiku tijekom kreiranja indeksa specificiranjem ključne riječi COMPUTE STATISTICS na izrazu CREATE INDEX. Budući da se podaci stalno ažuriraju i distribucija vrijednosti se također mijenja, statistiku bi trebalo povremeno ažurirati pomoću postupaka DBMS_STATS.GATHER_TABLE_STATISTICS i DBMS_STATS.GATHER_SCHEMA_STATISTICS.
Uništite nepotrebne indekse
Indeks se briše u sljedećim slučajevima:
- ako upotreba indeksa ne poboljšava performanse upita. Do ove situacije dolazi ako je tablica premala ili ako je u tablici mnogo redaka, ali među njima je samo nekoliko elemenata indeksa;
- ako se indeks ne koristi u vašim zahtjevima za prijedloge;
- ako padne i indeks prije ponovne izgradnje.
Indeksi se stvaraju na stupcima u tablicama i prikazima. Indeksi pružaju način brzog pronalaženja podataka na temelju vrijednosti u ovim stupcima. Na primjer, ako kreirate indeks na primarnom ključu, a zatim pretražite red podataka koristeći vrijednosti primarnog ključa, tada SQL Server prvo pronalazi vrijednost indeksa, a zatim koristi indeks za brzo pronalaženje čitavog retka podataka. Bez indeksa izvršit će se potpuno skeniranje (skeniranje) svih redaka u tablici, što može imati značajan utjecaj na performanse.
Možete stvoriti indeks na većini stupaca tablice ili prikaza. Izuzetak su uglavnom stupci s vrstama podataka za pohranu velikih objekata ( LOB), kao što su image, tekstili varchar (max)... Možete stvoriti i indekse na stupcima dizajniranim za pohranjivanje podataka u format XML, ali su ovi indeksi raspoređeni malo drugačije od standardnih i njihovo razmatranje je izvan okvira ovog članka. Takođe se članak ne bavi kolonarnicaindeksi. Umjesto toga, fokusiram se na indekse koji se najčešće koriste u bazama podataka. SQL Server.
Indeks se sastoji od skupa stranica, čvorova indeksa koji su organizirani u drvenoj strukturi - uravnoteženo drvo... Ova je struktura hijerarhijske prirode i započinje korijenskim čvorom na vrhu hijerarhije i čvorovima listova na dnu, kao što je prikazano na slici: 
Kada upitate indeksirani stupac, alat za pokretanje pokreće se s vrha korijenskog čvora i postepeno se pomiče kroz međupredmetne čvorove, pri čemu svaki srednji sloj sadrži detaljnije informacije o podacima. Alat za upite nastavlja se kretati kroz indeksne čvorove dok ne dosegne najnižu razinu s indeksnim listovima. Na primjer, ako tražite vrijednost 123 u indeksiranom stupcu, mehanizam za upite prvo će odrediti stranicu na prvoj srednjoj razini na razini korijena. U ovom slučaju, prva stranica upućuje na vrijednost od 1 do 100, a druga od 101 do 200, pa će se uređaj za upite odnositi na drugu stranicu ovog srednjeg nivoa. Nadalje, bit će razjašnjeno da biste trebali uputiti na treću stranicu sljedeće intermedijarne razine. Odavde će mehanizam za upite čitati vrijednost samog indeksa na nižoj razini. Listovi indeksa mogu sadržavati i same podatke tablice ili jednostavno pokazivač na redove s podacima u tablici, ovisno o vrsti indeksa: klasterirani indeks ili neklastični indeks.
Indeks klastera
Klasterirani indeks pohranjuje stvarne redove podataka u listove indeksa. Vraćajući se prethodnom primjeru, to znači da će red podataka koji je povezan s ključnom vrijednošću 123 biti pohranjen u samom indeksu. Važna karakteristika klasteriranog indeksa je da su sve vrijednosti razvrstane u određenom redoslijedu, bilo uzlazno ili silazno. Dakle, tablica ili prikaz može imati samo jedan klasterirani indeks. Pored toga, treba napomenuti da se podaci u tablici pohranjuju u razvrstanom obliku samo ako je na ovoj tablici stvoren klasterirani indeks.Tabela koja nema klasterirani indeks naziva se hrpa.
Indeks bez klastera
Za razliku od klasteriranog indeksa, listovi neklasteriziranog indeksa sadrže samo one stupce ( ključ), kojim se određuje ovaj indeks, a takođe sadrži pokazivač na redove sa stvarnim podacima u tablici. To znači da sustavu upita mora biti dodatna operacija da bi pronašla i preuzela potrebne podatke. Sadržaj pokazivača na podatke ovisi o tome jesu li podaci pohranjeni u klasteriranoj tablici ili na hrpi. Ako se pokazivač odnosi na klasteriranu tablicu, onda vodi do klasteriranog indeksa koji se može koristiti za pronalaženje stvarnih podataka. Ako se pokazivač odnosi na hrpu, tada vodi do određenog identifikatora podatkovnog retka. Neklastični indeksi se ne mogu sortirati, za razliku od klasteriranih, ali možete stvoriti više neklastičnih indeksa na tablici ili prikazu, do 999. To ne znači da biste trebali stvoriti što više indeksa. Indeksi mogu i poboljšati i pogoršati performanse sistema. Osim što možete stvoriti više indeksa koji nisu u klasteru, možete uključiti i dodatne stupce ( uključena kolona) na svoj indeks: listovi indeksa pohranjuju ne samo vrijednost samih indeksiranih stupaca, već i vrijednosti tih neindeksiranih dodatnih stupaca. Taj će vam pristup omogućiti da otklonite neka od ograničenja indeksa. Na primjer, možete uključiti stupac koji ne može indeksirati ili zaobići granicu duljine indeksa (u većini slučajeva 900 bajtova).Vrste indeksa
Pored toga što je indeks ili klasteriran ili ne cluster, moguće ga je opcionalno konfigurirati kao složeni indeks, jedinstveni indeks ili pokrivajući indeks.Kompozitni indeks
Takav indeks može sadržavati više stupaca. U indeks možete uključiti do 16 stupaca, ali njihova je ukupna dužina ograničena na 900 bajtova. I indeksi i klase i indeksi mogu biti složeni.Jedinstveni indeks
Ovaj indeks osigurava da je svaka vrijednost u indeksiranom stupcu jedinstvena. Ako je indeks sastavljen, tada jedinstvenost vrijedi za sve stupce u indeksu, ali ne i za svaki stupac. Na primjer, ako stvorite jedinstveni indeks na stupovima IMEi PREZIME, puno ime mora biti jedinstveno, ali duplikati imena i prezimena mogući su odvojeno.Jedinstveni indeks automatski se stvara kada definirate ograničenja stupca: primarni ključ ili ograničenje jedinstvenosti na vrijednosti:
- Primarni ključ
Kad tada definirate ograničenje primarnog ključa u jednom ili više stupaca SQL Server automatski stvara jedinstveni klasterirani indeks ako klasterirani indeks nije stvoren ranije (u ovom slučaju se na primarnom ključu stvara jedinstveni indeks bez klastera) - Jedinstvenost vrijednosti
Kad definirate ograničenje jedinstvenosti vrijednosti, tada SQL Server automatski stvara jedinstveni indeks bez klastera. Možete odrediti da se jedinstveni klasterirani indeks stvara ako u tablici nije stvoren nijedan klasterirani indeks
Pokrivajući indeks
Takav indeks omogućava određenom upitu da odmah dobije sve potrebne podatke iz listova indeksa bez dodatnih poziva u zapise same tablice.Dizajn indeksa
Koliko god indeksi mogli biti korisni, trebali bi ih pažljivo osmisliti. Budući da indeksi mogu zauzeti značajan prostor na disku, ne želite stvoriti više indeksa nego što je potrebno. Osim toga, indeksi se automatski ažuriraju kada se ažurira sam podatkovni redak, što može dovesti do dodatnih režijskih resursa i degradacije performansi. Postoji nekoliko baza podataka i upita za razmatranje prilikom dizajniranja indeksa.Baza podataka
Kao što je ranije napomenuto, indeksi mogu poboljšati performanse sistema jer pružaju pretraživaču brzi put za pronalaženje podataka. Međutim, trebali biste razmotriti i koliko često ćete umetati, ažurirati ili brisati podatke. Kada promijenite podatke, indeksi se moraju promijeniti i tako da odražavaju odgovarajuće radnje na podacima, koje mogu značajno pogoršati performanse sistema. Uzmite u obzir sledeće smernice prilikom planiranja strategije indeksiranja:- Upotrijebite što manje indeksa za tablice koje se često ažuriraju.
- Ako tablica sadrži veliku količinu podataka, ali njihove su promjene manje, tada upotrijebite onoliko indeksa koliko je potrebno za poboljšanje performansi vaših upita. Međutim, dobro razmislite prije upotrebe indeksa na malim tablicama. možda bi traženje indeksa moglo potrajati duže od jednostavnog skeniranja svih redaka.
- Za klasterirane indekse pokušajte koristiti što kraća polja. Najbolje je koristiti klasterirani indeks na stupovima s jedinstvenim vrijednostima i ne dopustiti NULLs. Zbog toga se primarni ključ često koristi kao indeks klastera.
- Jedinstvenost vrijednosti u stupcu utječe na performanse indeksa. Općenito, što više duplikata imate u stupcu, indeks će biti lošiji. S druge strane, što više jedinstvenih vrijednosti ima, zdravlje indeksa je bolje. Koristite jedinstveni indeks kad god je to moguće.
- Za složeni indeks uzmite u obzir redoslijed stupaca u indeksu. Stupci koji se koriste u izrazima GDJE(npr. WHERE FirstName \u003d "Čarli") mora biti prvi u indeksu. Naknadni stupci trebali bi biti navedeni na temelju njihove jedinstvenosti (prvi stupaci s najvećim brojem jedinstvenih vrijednosti).
- Možete odrediti i indeks u izračunatim stupcima ako ispunjavaju neke zahtjeve. Na primjer, izraz upotrijebljen za dobivanje vrijednosti stupca mora biti deterministički (uvijek vratiti isti rezultat za zadani skup ulaznih parametara).
Upiti u bazu podataka
Drugo razmatranje koje treba imati na umu pri dizajniranju indeksa je koji se upiti postavljaju u bazu podataka. Kao što je ranije rečeno, trebalo bi razmotriti koliko često se podaci mijenjaju. Uz to, treba koristiti sljedeće principe:- Pokušajte umetnuti ili izmijeniti što više redaka u jednom upitu što je više moguće, umjesto da to radite u nekoliko pojedinačnih upita.
- Stvorite indeks bez klastera na stupovima koji se često koriste u vašim upitima kao pojmovima za pretraživanje u GDJEi veze u PRIDRUŽITE se.
- Razmislite o stupcima indeksiranja koji se koriste u upitima pretraživanja niza za točne vrijednosti podudaranja.
A sada, zapravo:
14 pitanja koja ste previše sramežljivo postavljali o indeksima u SQL Serveru
Zašto tablica ne može imati dva grupirana indeksa?
Želite kratak odgovor? Klasterirani indeks je tabela. Kada stvorite klasterirani indeks na tablici, podsustav za pohranu sortira sve redove u tablici u uzlaznom ili silaznom redoslijedu u skladu s definicijom indeksa. Klasterirani indeks nije zasebna cjelina kao ostali indeksi, već je mehanizam za sortiranje podataka u tablici i olakšavanje brzog pristupa redima podataka.Recimo da imate tablicu koja sadrži povijest prodajnih transakcija. Tabela prodaje sadrži podatke kao što su ID narudžbe, pozicija artikla u narudžbi, broj artikla, količina artikla, broj narudžbe i datum itd. Na stupcima stvarate klasterirani indeks OrderIDi LineIDporedani po uzlaznom redosledu kao što je prikazano na sledećem T-SQL kod:
USTVARITE JEDINSTVENI KLASIRANI INDEKS ix_oriderid_lineid ON dbo.Sales (OrderID, LineID);
Kada pokrenete ovu skriptu, svi će se redovi u tablici fizički poredati prvo po stupcu OrderID, a zatim po LineID-u, ali sami podaci ostat će u jednom logičkom bloku, u tablici. Iz tog razloga ne možete stvoriti dva klasterirana indeksa. Može postojati samo jedna tablica s jednim podacima, a ova se tablica može sortirati samo jednom određenim redoslijedom.
Ako grupirana tablica nudi mnoge prednosti, zašto koristiti hrpu?
Upravu si. Klasterirane tablice su sjajne i većina vaših upita će bolje raditi na tablicama sa sjedinjenim indeksom. Ali u nekim ćete slučajevima možda htjeti ostaviti tablice u njihovom prirodnom, netaknutom stanju, tj. kao gomilu i stvarajte samo neklasirane indekse kako biste održali svoje upite zdravim.Kopa, kao što se sjećate, podatke pohranjuje nasumičnim redoslijedom. Tipično, podsustav za pohranu dodaje podatke u tablicu redoslijedom kojim su umetnuti, ali podsistem također voli pomicati redove za učinkovitiju pohranu. Kao rezultat toga, nemate šansu predvidjeti kojim redoslijedom će se podaci pohraniti.
Ako mehanizam za upite mora pronaći podatke bez prednosti indeksa koji nije klasteriran, izvršit će skeniranje cijele tablice kako bi pronašao redove koji su mu potrebni. Na vrlo malim stolovima to obično nije problem, ali kako hrpa raste u veličini, performanse brzo padaju. Naravno, neklasterizirani indeks može pomoći pomoću pokazivača na datoteku, stranicu i niz u kojem su podaci pohranjeni - obično je puno bolja alternativa skeniranju tablica. Uprkos tome, teško je uporediti prednosti klasteriranog indeksa kada se gleda uspješnost upita.
Međutim, gomila može pomoći poboljšanju performansi u određenim situacijama. Razmislite o tablici s puno umetaka, ali s rijetkim ažuriranjima ili brisanjima podataka. Na primjer, tablica koja pohranjuje dnevnik koristi se prvenstveno za umetanje vrijednosti dok se ne arhiviraju. Na hrpi nećete vidjeti straničenje i fragmentaciju podataka kao što je to slučaj sa klasteriranim indeksom, jer se redovi jednostavno dodaju na kraju hrpe. Preveliko razdvajanje stranica može imati značajan uticaj na performanse i to na ne baš dobar način. Općenito, gomila vam omogućava da umetnete podatke relativno bezbolno, i ne morate se boriti sa režijom podataka za pohranu i održavanje kao što bi to činilo s klasteriranim indeksom.
Ali nedostatak ažuriranja i brisanja podataka ne treba smatrati jedinim razlogom. Način uzorkovanja podataka je također važan faktor. Na primjer, ne biste trebali koristiti heap ako često postavljate podatke o rasponima podataka ili ako se traženi podaci često trebaju sortirati ili grupirati.
Sve to znači da biste trebali razmotriti korištenje heap-a samo kad radite s vrlo malim tablicama ili je sva vaša interakcija s tablicom ograničena na umetanje podataka, a upiti su krajnje jednostavni (a ionako koristite neklasirane indekse). Inače, držite se dobro dizajniranog klasteriranog indeksa, na primjer definiranog na jednostavnom uzlaznom ključnom polju, poput najčešće korištenog stupca s IDENTITET.
Kako mogu promijeniti zadani faktor ispunjavanja indeksa?
Promjena zadanog faktora ispunjavanja indeksa je jedna stvar. Razumijevanje kako funkcioniše zadani omjer je različito. Ali prvo, par koraka unazad. Faktor ispunjavanja indeksa određuje količinu prostora na stranici za spremanje indeksa na donjoj razini (nivo lista) prije nego što započnete s popunjavanjem nove stranice. Na primjer, ako je koeficijent postavljen na 90, tada će s rastom indeks uzeti 90% na stranici, a zatim će prijeći na sljedeću stranicu.Prema zadanim postavkama, vrijednost faktora ispunjavanja indeksa u SQL Serverjednaka je 0, što je jednako 100. Kao rezultat toga, svi novi indeksi automatski nasljeđuju ovu postavku, osim ako u kôdu izričito ne odredite vrijednost različitu od standardne vrijednosti za sustav ili ne promijenite zadano ponašanje. Možeš koristiti SQL Server Management Studio ispraviti zadanu vrijednost ili pokrenuti sistem pohranjen postupak sp_configure... Na primjer, sljedeći skup T-SQL naredbe postavlja vrijednost koeficijenta na 90 (prvo morate prijeći na napredni način podešavanja):
EXEC sp_configure "prikaži napredne opcije", 1; GO RECONFIGURE; GO EXEC sp_configure "faktor ispunjavanja", 90; GO RECONFIGURE; GO
Nakon što promijenite vrijednost faktora ispunjavanja indeksa, trebate ponovo pokrenuti uslugu SQL Server... Sada možete provjeriti postavljenu vrijednost izvođenjem sp_configure bez navedenog drugog argumenta:
EXEC sp_configure "faktor ispunjavanja" GO
Ova naredba treba vratiti vrijednost od 90. Kao rezultat toga, svi novo kreirani indeksi upotrijebit će ovu vrijednost. To možete provjeriti kreiranjem indeksa i traženjem vrijednosti faktora ispunjavanja:
USE AdventureWorks2012; - vaša baza podataka GO CREATE NONCLUSTERED INDEX ix_people_lastname ON Person.Person (LastName); GO SELECT fill_factor OD sys.indexes WHERE object_id \u003d object_id ("Person.Person") AND name \u003d "ix_people_lastname";
U ovom primjeru stvorili smo indeks bez klastera na tablici Osobau bazi podataka AdventureWorks2012. Nakon kreiranja indeksa, možemo dobiti vrijednost faktora ispunjavanja iz sistemskih tablica sys.indexes. Zahtjev treba vratiti 90.
No, recimo da smo izbrisali indeks i ponovo ga stvorili, ali sad smo odredili određenu vrijednost faktora ispunjavanja:
USTVARITE NEKLUSTIRANI INDEKS ix_people_lastname ON Osoba.Person (LastName) WITH (fillfactor \u003d 80); GO SELECT fill_factor OD sys.indexes WHERE object_id \u003d object_id ("Person.Person") AND name \u003d "ix_people_lastname";
Ovaj put smo dodali uputstvo SAi opcija fillfactorza naš rad indeksa USTVARITE INDEX i označio vrijednost 80. Operator ODABIRsada vraća odgovarajuću vrijednost.
Do sada je sve bilo prilično direktno. Gdje se zaista možete zaglaviti u cijelom ovom procesu je kada kreirate indeks koristeći zadanu vrijednost koeficijenta, pod pretpostavkom da znate tu vrijednost. Na primjer, netko nespretno kuka s postavkama poslužitelja i toliko je uznemiren da postavlja vrijednost faktora ispunjavanja indeksa jednaku 20. U međuvremenu, nastavljate s izradom indeksa, pretpostavljajući zadanu vrijednost 0. Nažalost, prije toga ne možete saznati vrijednost koeficijenta sve dok ne kreirate indeks, a zatim provjerite vrijednost kao što smo to radili u našim primjerima. U suprotnom, morat ćete pričekati trenutak kada učinak upita toliko padne da počnete nešto sumnjati.
Još jedan problem koji treba imati na umu je obnova indeksa. Kao i kod stvaranja indeksa, možete odrediti faktor ispunjavanja indeksa kada ga ponovo gradite. Međutim, za razliku od naredbe create index, obnova ne koristi zadane postavke poslužitelja, uprkos onome što bi se moglo činiti. Čak štoviše, ako posebno ne odredite vrijednost faktora ispunjavanja indeksa, tada SQL Server koristit će vrijednost koeficijenta s kojim je ovaj indeks postojao prije njegovog restrukturiranja. Na primjer, sljedeća operacija ALTER INDEX obnavlja indeks koji smo upravo stvorili:
ALTER INDEX ix_people_lastname ON Osoba.Person REBUILD; GO SELECT fill_factor OD sys.indexes WHERE object_id \u003d object_id ("Person.Person") AND name \u003d "ix_people_lastname";
Kada provjerimo vrijednost faktora ispunjavanja, dobivamo vrijednost 80, jer je to ono što smo naveli kada smo zadnji put kreirali indeks. Zadana vrednost se zanemaruje.
Kao što vidite, promjena indeksa vrijednosti ispunjavanja indeksa nije tako teška. Mnogo je teže znati trenutnu vrijednost i razumjeti kad se primjenjuje. Ako uvijek određujete omjer konkretno pri kreiranju i ponovnoj izgradnji indeksa, uvijek znate određeni rezultat. Osim ako se ne morate pobrinuti da neko drugi ne pokvari postavke vašeg servera, uzrokujući da se svi indeksi obnove sa smiješno niskim faktorima popunjavanja indeksa.
Mogu li stvoriti klasterirani indeks na stupcu koji sadrži duplikate?
Da i ne. Da, možete stvoriti klasterirani indeks na stupcu s ključevima koji sadrži duplikate vrijednosti. Ne, vrijednost stupca ključeva ne može se ostaviti u jedinstvenom stanju. Dopusti mi da objasnim. Ako stvorite nejedinstveni indeks klastera u stupcu, uređaj za pohranu dodaje cjelobrojnu vrijednost (uniquefifier) \u200b\u200bdvostrukoj vrijednosti kako bi se osigurala jedinstvenost i na taj način osiguralo da se svaki redak u klasteriranoj tablici može prepoznati.Na primjer, možda ćete odlučiti da stvorite klasterirani indeks na stupcu u tablici podataka o klijentima Prezimekoja drži prezime. Stupac sadrži vrijednosti kao što su Franklin, Hancock, Washington i Smith. Zatim umetnete vrijednosti za Adams, Hancock, Smith i ponovno Smith. Ali vrijednost stupaca ključeva mora biti jedinstvena, pa će podsustav za pohranu promijeniti vrijednost duplikata tako da izgledaju ovako: Adams, Franklin, Hancock, Hancock1234, Washington, Smith, Smith4567 i Smith5678.
Na prvi se pogled ovaj pristup čini normalnim, ali cjelobrojna vrijednost povećava veličinu ključa, što može predstavljati problem s velikim brojem duplikata, a te će vrijednosti postati osnova neklastiranog indeksa ili reference stranog ključa. Iz tih razloga, uvijek biste trebali pokušati stvoriti jedinstvene klasterirane indekse kad god je to moguće. Ako to nije moguće, pokušajte upotrijebiti stupce s vrlo visokim sadržajem jedinstvenih vrijednosti.
Kako se tabela pohranjuje ako nije kreiran klasterirani indeks?
SQL Server podržava dvije vrste tablica: klasterirane tablice s klasteriranim indeksom i hrpom tablica ili samo gomile. Za razliku od klasteriranih tablica, podaci na hrpi nisu sortirani ni na koji način. Zapravo, ovo je gomila podataka. Ako takvoj tablici dodate red, podsustav za pohranu jednostavno će je dodati na kraj stranice. Kada se stranica ispuni podacima, ona će biti dodana novoj stranici. U većini ćete slučajeva htjeti stvoriti klasterirani indeks na tablici kako biste iskoristili mogućnost sortiranja i ubrzali upite (pokušajte zamisliti da pronađete telefonski broj u adresaru koji nije sortiran ni po kojem principu). Međutim, ako odlučite da ne kreirate klasterirani indeks, ipak možete stvoriti neklasterirani indeks na hrpi. U ovom slučaju, svaki red indeksa imat će pokazivač na heap red. Pokazivač sadrži ID datoteke, broj stranice i broj podatkovne linije.Kakav je odnos ograničenja jedinstvenosti vrijednosti i primarnog ključa sa indeksima tablice?
Primarni ključ i i jedinstveno ograničenje osiguravaju da su vrijednosti u stupcu jedinstvene. Možete stvoriti samo jedan primarni ključ za tablicu i on ne može sadržavati vrijednosti NULL. Možete stvoriti nekoliko ograničenja jedinstvenosti vrijednosti za tablicu, a svaka od njih može imati jedan zapis sa NULL.Kada stvorite primarni ključ, podsustav za pohranu također će stvoriti jedinstveni klasterirani indeks ako nije stvoren već klasterirani indeks. Međutim, možete nadjačati zadano ponašanje i tada će se stvoriti neklasterirani indeks. Ako klasterirani indeks postoji kada stvorite primarni ključ, stvorit će se jedinstveni ne-grupisani indeks.
Kada stvorite ograničenje jedinstvenosti, podsustav za pohranu stvara jedinstveni indeks bez klastera. Međutim, možete odrediti stvaranje jedinstvenog indeksa klastera ako on nije prethodno kreiran.
Općenito, ograničenje jedinstvenosti vrijednosti i jedinstveni indeks su ista stvar.
Zašto se klasterirani i neklasterizirani indeksi nazivaju B-stablo u SQL Serveru?
Osnovni indeksi u SQL Serveru, bilo klasterirani ili neklasterizirani, distribuiraju se preko skupova stranica koji su indeksni čvorovi. Ove su stranice organizirane u određenoj hijerarhiji sa strukturom stabala koja se naziva uravnoteženo stablo. Na gornjoj razini je korijenski čvor, na dnu krajnji čvorovi listova, s međurednim čvorovima između gornje i donje razine, kao što je prikazano na slici:Korijenski čvor pruža glavnu ulaznu točku za upite koji pokušavaju dobiti podatke putem indeksa. Polazeći od ovog čvora, alat za pokretanje upita pokreće hijerarhijsku navigaciju dolje na odgovarajući krajnji čvor koji sadrži podatke.
Na primjer, pretpostavimo da je primljen zahtjev za dohvaćanje redaka koji sadrže ključnu vrijednost 82. Mehanizam upita pokreće korijenski čvor, koji se odnosi na odgovarajući srednji čvor, u našem slučaju 1-100. Iz međupredmetnog čvora 1-100 prijelaz se nastavlja na čvor 51-100, a odatle do krajnjeg čvora 76-100. Ako je to klasterirani indeks, tada list čvora sadrži podatke o retcima povezanim s ključem 82. Ako je to indeks bez klastera, onda indeksni list sadrži pokazivač na sjedinjenu tablicu ili određeni redak na hrpi.
Kako indeks općenito može poboljšati performanse upita ako morate preći sve ove čvorove indeksa?
Prvo, indeksi ne poboljšavaju uvek performanse. Previše nepravilno kreiranih indeksa čini sistem zakržljalim i usporava rad upita. Bilo bi preciznije reći da ako se indeksi pažljivo primjenjuju, oni mogu pružiti značajne rezultate.Razmislite o ogromnoj knjizi o podešavanju performansi SQL Server (papirna, a ne elektronska verzija). Zamislite da želite pronaći informacije o konfiguriranju Upravitelja resursa. Možete prevući prst po cijeloj stranici knjige po stranici ili otvoriti tablicu sadržaja i saznati točan broj stranice s informacijama koje tražite (pod uvjetom da je knjiga ispravno indeksirana i da su indeksi tačni u sadržaju). Naravno, ovo će vam uštedjeti puno vremena, iako morate prvo prijeći na potpuno drugu strukturu (indeks) da biste dobili informacije koje su vam potrebne iz primarne strukture (knjige).
Poput indeksa knjiga, indeksa u SQL Server omogućava vam izvršavanje preciznih upita na željenim podacima, umjesto potpunog skeniranja svih podataka sadržanih u tablici. Za male tablice potpuno skeniranje obično nije problem, ali velike tablice zauzimaju više stranica podataka, što može rezultirati dugotrajnim upitom ako ne postoji indeks koji će omogućiti da alat za upit odmah dobije ispravnu lokaciju podataka. Zamislite da se izgubite na cestovnom raskrižju na više nivoa ispred velike metropole bez mape i dobit ćete ideju.
Ako su indeksi tako veliki, zašto jednostavno ne stvoriti jedan na svakom stupcu?
Nijedno dobro djelo ne smije proći nekažnjeno. Barem je tako slučaj sa indeksima. Naravno, indeksi djeluju dobro sve dok izvršavate upite o dohvaćanju podataka s operatorom ODABIR, ali čim započnu česti pozivi operatera ULAZITE, Ažuriranjei DELETEpa se krajolik mijenja vrlo brzo.Kad pokrenete zahtjev za podacima od strane operatera ODABIR, aparat za upite pronalazi indeks, prelazi njegovu strukturu stabla i pronalazi podatke koje traži. Šta bi moglo biti lakše? Ali sve se mijenja ako pokrenete izjavu o promjeni kao što je Ažuriranje. Da, za prvi dio izjave alat za ispitivanje može ponovo upotrijebiti indeks da pronađe red koji se mijenja - to je dobra vijest. A ako je jednostavna promjena podataka u nizu koja ne utječe na promjenu stupaca ključeva, tada će postupak promjene biti potpuno bezbolan. Ali što ako promjena uzrokuje razdvajanje stranica koje sadrže podatke ili vrijednost ključnog stupca promijeni, što uzrokuje premještanje na drugačiji inode - to bi uzrokovalo da indeks zahtijeva reorganizaciju koja utječe na sve pridružene indekse i operacije, što rezultira u rasprostranjen pad produktivnosti.
Slični procesi se dešavaju kada se zove operator DELETE... Indeks može pomoći u pronalaženju lokacije izbrisanih podataka, ali samo brisanje podataka može dovesti do preuređenja stranica. Operator ULAZITE, glavni neprijatelj svih indeksa: počnete dodavati velike količine podataka, što dovodi do promjena indeksa i reorganizacije, i svi trpe.
Stoga razmislite o tipovima upita prema vašoj bazi podataka kada razmišljate o tome koji tip indeksa i koliko treba kreirati. Veće nije bolje. Prije dodavanja novog indeksa u tablicu, uzmite u obzir troškove ne samo osnovnih upita, već i količinu iskorištenog prostora na disku, troškove održavanja operabilnosti i indeksa, što može dovesti do domino učinka za druge operacije. Vaša strategija dizajniranja indeksa jedan je od najvažnijih aspekata implementacije i trebala bi sadržavati mnoga razmatranja, od veličine indeksa, broja jedinstvenih vrijednosti, do vrste upita koje indeks podržava.
Je li obavezno stvoriti klasterirani indeks na stupcu primarnog ključa?
Možete stvoriti klasterirani indeks u bilo kojem stupcu koji ispunjava tražene uvjete. Tačno je da su klasterirani indeks i ograničenje primarnog ključa stvoreni jedno za drugo i da su na nebu vjenčani, pa imajte na umu da kada stvorite primarni ključ, tada će se klasterirani indeks automatski stvoriti ako nije stvoren ranije. Međutim, možete odlučiti da će klasterirani indeks bolje raditi drugdje, a često se vaša odluka itekako isplati.Glavna svrha klasteriranog indeksa je sortiranje svih redaka u vašu tablicu na temelju stupca ključa navedenog kada je indeks definiran. To omogućava brzo pretraživanje i jednostavan pristup podacima tablice.
Primarni ključ tablice može biti dobar izbor jer jedinstveno identificira svaki red u tablicama bez potrebe za dodavanjem dodatnih podataka. U nekim je slučajevima najbolji izbor surogat primarnog ključa koji nije samo jedinstven, već je i mali i postupno uvećani, čineći neklasterizirane indekse temeljene na toj vrijednosti efikasnijima. Alat za optimizaciju upita također voli ovu kombinaciju klasteriranog indeksa i primarnog ključa jer je spajanje tablica brže od spajanja na drugi način koji ne koristi primarni ključ i pridruženi indeks klastera. Kao što rekoh, ovo je brak sklopljen na nebu.
Na kraju, međutim, vrijedi napomenuti da prilikom stvaranja klasteriranog indeksa treba uzeti u obzir nekoliko aspekata: koliko će se neklasterskih indeksa oslanjati na njega, koliko često će se vrijednost stupaca ključa indeksa mijenjati i koliko veća. Kada se vrijednosti u klasteriranim stupovima indeksa promijene ili indeks ne izvede kako se očekuje, tada mogu utjecati na sve ostale indekse u tablici. Klasterirani indeks mora se temeljiti na najstabilnijem stupcu, čije se vrijednosti povećavaju u određenom redoslijedu, ali ne i nasumično. Indeks mora podržavati upite u podacima tablice s najviše pristupa, tako da upiti u potpunosti koriste podatke koji su sortirani i dostupni u korijenskim čvorovima, listovima indeksa. Ako se primarni ključ uklapa u ovaj scenarij, onda ga upotrijebite. Ako ne, odaberite drugi skup stupaca.
Šta ako indeksirate pogled, da li je to još uvijek pogled?
Pogled je virtualna tablica koja generira podatke iz jedne ili više tablica. U osnovi, to je imenovani upit koji dohvaća podatke iz donjih tablica kada na taj prikaz pozovete upit. Učinkovitost upita možete poboljšati stvaranjem klasteriranog indeksa i neklasteriziranih indeksa na ovom prikazu, slično onome kako kreirate indekse na tablici, ali glavna je upozorenje da se u početku stvara klasterirani indeks, a zatim možete stvoriti jedan ne cluster indeks.Kad se stvori indeksirani prikaz (materijalizirani prikaz), sama definicija pogleda ostaje zasebna cjelina. Ovo je, na kraju krajeva, samo tvrdi kod operatora ODABIRpohranjeni u bazi podataka. Ali indeks je sasvim drugačija priča. Kada stvorite klasterirani ili neklasterirani indeks na prikazu, podaci se fizički spremaju na disk, baš kao i uobičajeni indeks. Pored toga, kada se podaci u donjim tablicama mijenjaju, indeks prikaza automatski se mijenja (to znači da možda želite izbjeći indeksiranje pogleda onih tablica koje su podložne čestim promjenama). U svakom slučaju, pogled ostaje pogled - pogled na tablice, ali točno izvršene u ovom trenutku, s tim da mu odgovaraju indeksi.
Prije nego što možete stvoriti indeks za prikaz, on mora ispunjavati nekoliko ograničenja. Na primjer, pogled može referencirati samo osnovne tablice, a ne druge poglede, i te tablice moraju biti u istoj bazi podataka. Zapravo, postoje i mnoga druga ograničenja, stoga svakako provjerite dokumentaciju SQL Serveriza svih prljavih detalja.
Zašto koristiti indeks pokrivanja umjesto sastavljenog indeksa?
Prvo ćemo biti sigurni da razumijemo razliku između to dvoje. Sastavljeni indeks je samo običan indeks koji sadrži više stupaca. Stupci s više ključeva mogu se koristiti kako bi se osiguralo da je svaki red u tablici jedinstven, moguće je i kada primarni ključ ima više stupaca kako bi se osiguralo da je jedinstven ili pokušavate optimizirati izvršavanje često pozivanih upita na više stupaca. Općenito, međutim, što više ključnih stupaca sadrži indeks, indeks je manje efikasan i zato bi se složeni indeksi trebali mudro koristiti.Kao što je spomenuto, upit može imati ogromnu korist ako se svi potrebni podaci odmah nalaze na listovima indeksa, poput samog indeksa. Ovo nije problem klasteriranog indeksa jer svi podaci su već tamo (zbog čega je tako važno dobro razmisliti kada stvorite klasterirani indeks). Ali nerazvrstani indeks na lišću sadrži samo ključne stupce. Potrebni su dodatni koraci da bi alat za optimizaciju upita mogao pristupiti svim ostalim podacima što može dovesti do značajnih dodatnih troškova za dovršavanje vaših upita.
Ovo mi je korisni indeks pokrivanja. Kada definirate indeks bez klastera, možete dodati dodatne stupce u ključne stupce. Na primjer, pretpostavimo da vaša aplikacija često zahtijeva podatke stupaca OrderIDi OrderDateu tabeli Prodaja:
SELECT OrderID, OrderDate OD prodaje GDJE OrderID \u003d 12345;
Možete stvoriti složeni indeks bez klastera u oba stupca, ali stupac OrderDate samo će dodati nadzemne troškove održavanja indeksa i nikada neće biti posebno koristan ključ stupac. Najbolje rješenje bi bilo kreirati indeks pokrivanja s ključnim stupcem OrderIDi dodatno uključenu kolonu OrderDate:
USTVARITE NEKLUSTIRANI INDEKS ix_orderid ON dbo.Sales (OrderID) INCLUDE (OrderDate);
Pri tome izbjegavate nedostatke indeksiranja suvišnih stupaca uz zadržavanje prednosti pohranjivanja podataka na listove prilikom pokretanja upita. Uključeni stupac nije dio ključa, ali podaci su pohranjeni u završnom čvoru, indeksnom listu. Ovo može poboljšati performanse upita bez dodatnih troškova. Pored toga, stupci uključeni u indeks pokrivanja imaju manje ograničenja od ključnih stupaca indeksa.
Znači li broj duplikata u ključnom stupcu?
Kada kreirate indeks, morate pokušati smanjiti broj duplikata u vašim ključnim stupcima. Ili tačnije: pokušajte da ponovite omjer što je moguće niži.Ako radite sa složenim indeksom, umnožavanje se odnosi na sve ključne stupce u cjelini. Jedan stupac može sadržavati mnogo duplikata vrijednosti, ali treba postojati minimalno dupliranje među svim stupcima u indeksu. Na primjer, stvarate složeni indeks bez klastera u stupcima Imei Prezime, možete imati mnoge John Doe vrijednosti i mnoge Doe vrijednosti, ali želite što manje John Doe vrijednosti, ili još bolje samo jednu John Doe vrijednost.
Faktor jedinstvenosti za vrijednosti ključnog stupca naziva se selektivnost indeksa. Što su više jedinstvene vrijednosti, to je veća selektivnost: jedinstveni indeks ima najveću moguću selektivnost. Mehanizam upita vrlo voli stupce sa velikom selektivnošću, pogotovo ako ti stupci sudjeluju u WHERE klauzulama vaših najčešće izvršenih upita. Što je veća selektivnost indeksa, brži uređaj za upite može smanjiti veličinu dobivenog skupa podataka. Loša strana je, naravno, što su stupci s relativno malo jedinstvenih vrijednosti rijetko dobri kandidati za indeksiranje.
Je li moguće stvoriti neklasterirani indeks samo na određenom podskupu podataka s ključnim stupcima?
Prema zadanom, indeks bez klastera sadrži po jedan red za svaki red u tabeli. Naravno, možete reći isto za klasterirani indeks, pod pretpostavkom da je indeks zapravo tablica. Ali što se tiče indeksa bez klastera, odnos jedan na jedan važan je koncept, jer počevši od verzije SQL Server 2008, imate mogućnost stvaranja filtrabilnog indeksa koji ograničava redove uključene u njemu. Indeks koji filtrira može poboljšati performanse upita jer manji je i sadrži filtriranu, tačniju statistiku od svih tabelarnih statistika - to vodi boljim planovima izvršenja. Indeks koji filtrira također zahtijeva manje prostora za pohranu i niže troškove održavanja. Indeks se ažurira samo kada se promijene podaci koji odgovaraju filtru.Pored toga, lako je stvoriti filtrirajući indeks. U operatora USTVARITE INDEX samo treba biti navedeno u GDJEstanje filtriranja. Na primjer, možete filtrirati sve NULL retke iz indeksa, kao što je prikazano u kodu:
STVARITE NEKLUSTIRANI INDEX ix_trackingnumber O prodaji.SalesOrderDetail (CarrierTrackingNumber) GDJE CarrierTrackingNumber NIJE NULL;
U stvari, možemo filtrirati sve podatke koji nisu važni u kritičnim upitima. Ali budite oprezni, jer SQL Server nameće nekoliko ograničenja filtribilnim indeksima, poput nemogućnosti stvaranja filtrabilnog indeksa na prikazu, pa pročitajte dokumentaciju pažljivo.
Takođe se može dogoditi da slične rezultate postignete i stvaranjem indeksiranog prikaza. Međutim, filtrirani indeks ima nekoliko prednosti, poput mogućnosti smanjenja troškova održavanja i poboljšanja kvalitete vaših planova izvršenja. Filtrirani indeksi se mogu obnoviti i na mreži. Pokušajte s indeksiranim prikazom.
I opet malo od prevodioca
Svrha pojavljivanja ovog prijevoda na Habrahabr stranicama bila je reći ili podsjetiti na blog SimpleTalk sa RedGate.
Sadrži mnogo zabavnih i zanimljivih unosa.
Nisam povezan s bilo kojim proizvodom kompanije RedGateniti sa njihovom prodajom.
Kao što je obećano, knjige su za one koji žele znati više
Ja ću preporučiti tri vrlo dobre knjige od sebe (linkovi vode do zapalitiverzije u trgovini Amazon):
 |
Microsoft SQL Server 2012 T-SQL Osnove (referenca za programere) Autor Itzik Ben-Gan Datum objave: 15. jula 2012 Autor, majstor svog zanata, daje osnovna znanja o radu s bazama podataka. Ako ste sve zaboravili ili nikad niste znali, onda ga definitivno vrijedi pročitati. | U osnovi, možete otvoriti jednostavne indekse Dodavanje oznaka
Ako u tablici postoji mnogo zapisa, tada može biti vrlo teško pronaći potreban zapis. Pretraživanje podataka vrši se metodom nabrajanja, odnosno skeniraju se svi tablični zapisi od prvog do posljednjeg zapisa što dovodi do velikog gubitka vremena. Indeksi se koriste za lakše pronalaženje podataka u tablici. Indeks, koji se ponekad naziva i pokazivač, je redni broj unosa u tabeli. Indeks se gradi na vrijednostima jednog polja ili na vrijednostima nekoliko polja. Indeks zasnovan na vrijednostima jednog polja naziva se jednostavnim, a na temelju vrijednosti dvaju ili više polja naziva se složenim. Tijekom izrade indeksa zapisi u tablici razvrstavaju se po vrijednostima polja (ili polja) budućeg indeksa. Tada se prvom redu tablice dodjeljuje indeks broj jedan, drugom redu dodjeljuje se indeks broj dva, i tako dalje, do kraja tablice.
I jednostavni i složeni indeksi imaju vlastiti tip (Type). Primarni indeks (ključ) je polje ili grupa polja koja jedinstveno identificira zapis, to jest vrijednosti primarnog indeksa su jedinstvene (nisu ponovljene). U relacijskoj bazi podataka svaka tablica može imati samo jedan primarni ključ. Stol može imati mnogo stranih ključeva i oni će imati jednu od vrsta:
Kandidat - Kandidat za primarni ili alternativni ključ. Ima sva svojstva primarnog ključa.
Jedinstvena - omogućava duplicirane vrijednosti u polju na kojem je izgrađen, ali bit će prikazan samo jedan prvi zapis iz grupe zapisa s istom vrijednošću polja indeksa.
Uobičajeno - ne nameće nikakva ograničenja na vrijednosti indeksnog polja i na izlaz zapisa u ekran. Indeks kontrolira samo redoslijed u kojem su prikazani unosi. Ovo je najpopularnija vrsta indeksa.
Odnos između tablica temelji se na indeksima, koji se nazivaju ključevima.
Izgrađeni indeks pohranjuje se u posebnu indeksnu datoteku. Ako indeksna datoteka sadrži samo jedan indeks, onda se naziva jednim indeksom i ima .idx ekstenziju. Datoteke indeksa koje pohranjuju više indeksa nazivaju se više indeksnim datotekama i imaju .cdx ekstenziju. Svaki indeks koji je pohranjen u datoteci s više indeksa naziva se oznakom. Svaka oznaka ima svoje jedinstveno ime.
Postoje dvije vrste multi-indeks datoteka: jednostavne datoteke sa više indeksa (gore opisane) i strukturirane datoteke sa više indeksa. Strukturna datoteka sa više indeksa ima isti naziv kao i tablica kojoj pripada (jedina razlika je u ekstenziji datoteke) i ima sljedeća svojstva:
Automatski se otvara s vlastitom tablicom;
Ne može se zatvoriti, ali može se učiniti ne glavnim.
Jedna tablica može imati mnogo indeksnih datoteka, i jedno-indeksnih i multi-indeksnih. Starije verzije FoxPro-a koriste datoteke s više indeksa.
Izrada indeksa
Postoje dva načina kreiranja indeksa.
i.Sa naredbom:
INDEX ON<индексное выражение> TO< idx-datoteka\u003e | TAG<имя тега>
Dodjela opcija:
<indeksni izraz\u003e- naziv polja (ili polja), na temelju kojih bi se indeks trebao graditi. Prilikom izrade složenog indeksa nazivi polja navedeni su odvojeni znakom + (plus). Ako je složeni indeks izgrađen od:
Za brojčana polja indeks se temelji na zbroju vrijednosti polja;
Simbolička polja, tada se indeks gradi najprije prema vrijednosti prvog polja, a s ponovljenim vrijednostima prvog polja - po vrijednostima drugog polja; s ponovljenim vrijednostima prvog i drugog polja - prema vrijednostima trećeg polja itd .;
Za polja različitih tipova tada se najprije vrijednosti polja pretvaraju u jedan tip, obično simbolički, a zatim se izrađuje indeks.
Izraz indeksa ne smije biti veći od 254 znaka.
TO< idx-datoteka\u003e- naznačeno je ime datoteke sa jednim indeksom.
TAG<имя тега> - ime oznake naznačeno je u datoteci s više indeksa. Ako se koristi opcija, kreirana oznaka se postavlja u navedenu datoteku s više indeksa, a ako potrebna datoteka s više indeksa nedostaje, tada će se izgraditi strukturna datoteka s više indeksa. Ako je opcija izostavljena, stvorena oznaka bit će smještena u trenutnu datoteku s više indeksa.
ZA<условие> - postavlja način odabira na indeks onih zapisa tablice koji zadovoljavaju<условию>.
KOMPAKT- upravlja stvaranjem kompaktne datoteke s jednim indeksom. Ne koristi se u starijim verzijama FoxPro-a.
DESCENDING- gradi indeks u silaznom redoslijedu. Podrazumevano je graditi indeks uzlaznim redosledom (ASCENDING). Za datoteke sa jednim indeksom možete graditi samo uzlazni indeks. Ako izdate naredbu SET COLLATE prije upotrebe naredbe INDEX ON ..., možete sastaviti datoteku "jedan u dex" u silaznom redoslijedu.
JEDINSTVENO- gradi jedinstveni indeks. Ako polja (indeksi) indeksa sadrže duplicirane vrijednosti, tada samo jedan prvi zapis ulazi u indeks, a ostatak zapisa neće biti dostupan.
DODATNO- novo kreirana datoteka indeksa ne zatvara datoteke indeksa koje su do sad već otvorene. Ako je opcija izostavljena, novostvorena indeksna datoteka zatvara sve prethodno otvorene datoteke indeksa.
b.Upotreba glavnog menija:
U ovom se slučaju indeks kreira ili kada se kreira tablica ili kad se promijeni struktura tablice. Da biste to učinili, odaberite karticu Indeks u dijaloškom okviru tablice Dizajner tablica (Sl. 3.1).
Svaki indeks opisan je jednim retkom u dijaloškom okviru Table Designer.
Stupac Name sadrži naziv oznake datoteke s više indeksa. Ako je jedna od multi-indeks datoteka otvorena ranije, tada se novoizgrađeni indeks stavlja u otvorenu datoteku s više indeksa. Ako se indeks gradi istovremeno s kreiranjem datoteke tablice ili datoteka tablice nema datoteke s više indeksa, tada se novoizgrađeni indeks smješta u automatski kreiranu strukturnu datoteku s više indeksa.

Stupac Type s padajućeg popisa ukazuje na jednu od dozvoljenih vrsta indeksa. Ako se indeks gradi na tablici koja je dio baze podataka, tada su moguće četiri vrijednosti: Primarna, Kandidatna, Jedinstvena i Regularna. Ako se indeks gradi za besplatnu tablicu, tada primarna vrijednost nedostaje s padajućeg popisa.
Stupac Expression navodi imena polja u skladu s vrijednostima kojih treba graditi indeks. Ako gradite složeni indeks, tada je prikladnije koristiti Expression Builder koji se pokreće klikom na gumb smješten desno od polja za unos.
U stupcu Filter možete postaviti logički uvjet i izgraditi indeks ne za sve zapise u tablici, već samo za zapise koji zadovoljavaju stanje filtra. Ovaj je graf također opremljen programom za izradu izraza. Sadržaj i izgled oba graditelja su isti (slika 3.2).
U fig. 3.2 prikazuje konstrukciju složenog indeksa koristeći dva znakovna polja ush_step i uch_zvan (ime uch oznake dodijeljeno je prije nego što se alat za izradu izraza pozvao na ekran). Znak "+" koji označava izgradnju složenog indeksa preuzet je s padajućeg popisa String,
Na padajućem izborniku String nalaze se validne string funkcije. Isto tako, padajuće liste Math, Logical i Date prikazuju važeće matematičke, logičke i datumske funkcije. Željena funkcija je odabrana s ovih padajućih popisa klikom lijeve tipke miša. Imena polja (lista polja) i imena varijabli (lista varijabli) biraju se dvostrukim klikom lijeve tipke miša. Rezultirajući izraz se postavlja u prozor Expression.
Na padajućem popisu Iz tablice navedeno je ime tablice iz koje su uzeta polja za izradu indeksa. Ako želite, možete naručiti bilo koju tablicu iz trenutne baze podataka i uzeti bilo koje polje za izgradnju indeksa.
U ovom će se materijalu razmatrati takvi objekti baze podataka Microsoft SQL Server kao indeksiNaučit ćete što su indeksi, koje su vrste indeksa, kako ih kreirati, optimizirati i izbrisati.
Šta su indeksi u bazi podataka?
Indeks Je li objekt baze podataka struktura podataka koja se sastoji od ključeva na temelju jednog ili više stupaca tablice ili prikaza i pokazivača koji preslikavaju mjesto pohrane podataka. Indeksi su dizajnirani kako bi brže izvadili redove iz tablice, drugim riječima, indeksi omogućavaju brzo pretraživanje podataka u tablici, što uvelike poboljšava upite i performanse aplikacija. Indeksi se mogu koristiti i za osiguravanje jedinstvenosti redaka tablica, osiguravajući tako cjelovitost podataka.
Vrste indeksa u Microsoft SQL Serveru
Sljedeće vrste indeksa postoje u Microsoft SQL Serveru:
- Klasterirana (Klasterirana) Je indeks koji pohranjuje tablične podatke sortirane prema vrijednosti indeksnog ključa. Tabela može imati samo jedan klasterirani indeks, jer se podaci mogu sortirati samo u jednom redoslijedu. Kad god je to moguće, svaka tablica treba imati klasterirani indeks, ako tablica nema indeks klastera, takva se tablica naziva " hrpa". Klasterirani indeks kreira se automatski kada PRIMARNI KLJUČ ( primarni ključ) i JEDINSTVENO ako klasterirani indeks još nije definiran na tablici. Prilikom stvaranja klasteriranog indeksa na tablici ( hrpe) koji ima neklasterisane indekse, onda ih svi moraju biti obnovljeni nakon stvaranja.
- Neskupljeno (Neklasificirano) Je indeks koji sadrži ključnu vrijednost i pokazivač na podatkovni niz koji sadrži vrijednost tog ključa. Tabela može imati više indeksa koji nisu u klasteru. Neklastični indeksi mogu se kreirati na tablicama sa ili bez klasteriranog indeksa. Upravo se ova vrsta indeksa koristi za poboljšanje performansi često korištenih upita, jer neklasterizirani indeksi omogućavaju brzo pretraživanje i pristup podacima ključnim vrijednostima;
- Filterable (Filtrirano) Je optimizirani neklasterirani indeks koji koristi predikat filtra za indeksiranje podskupina redaka u tablici. Ako je dobro dizajniran, ova vrsta indeksa može poboljšati performanse upita i također smanjiti troškove održavanja i skladištenja indeksa u odnosu na indekse pune tablice;
- Jedinstven (Jedinstven) Je indeks koji osigurava da nema duplikata ( isto) vrijednosti indeksnog ključa, čime se jamči jedinstvenost redaka za ovaj ključ. I klasterirani i neklasterizirani indeksi mogu biti jedinstveni. Ako stvorite jedinstveni indeks na više stupaca, indeks osigurava da je svaka kombinacija vrijednosti u ključu jedinstvena. Kada stvorite PRIMARY KEY ili UNIQUE ograničenja, SQL poslužitelj automatski stvara jedinstveni indeks na ključnim stupcima. Jedinstveni indeks može se stvoriti samo ako tablica trenutno nema dvostruke vrijednosti za ključne stupce;
- Columnar (Columnstore) Je indeks zasnovan na tehnologiji čuvanja u obliku stupaca. Ova vrsta indeksa je djelotvorna za velika skladišta podataka, jer može povećati performanse upita do spremišta do 10 puta i također smanjiti veličinu podataka do 10 puta, jer se podaci u Columnstore indeksu komprimiraju. Postoje i klasterirani indeksi stupaca i oni koji nisu klasterirani;
- Ceo tekst (Ceo tekst) Posebna je vrsta indeksa koji pruža efikasnu podršku za složeno pretraživanje riječi u znakovnim nizovima podataka. Proces stvaranja i održavanja indeksa u punom tekstu naziva se " punjenje". Postoje vrste ispunjavanja kao što su potpuno ispunjavanje i promjena praćenja. Po zadanom, SQL poslužitelj u potpunosti pušta novi indeks cjelovitog teksta odmah nakon kreiranja, ali to može zahtijevati značajnu količinu resursa, ovisno o veličini tablice, pa je moguće odgoditi cjelovito sijanje. Ploča za praćenje promjena koristi se za održavanje indeksa u punom tekstu nakon što je prvotno pun;
- Prostorni (Prostorni) Je indeks koji vam omogućuje efikasnije korištenje određenih operacija na značajkama na stupovima s podacima o geometriji ili zemljopisu. Ova vrsta indeksa može se stvoriti samo za prostorni stupac, a tablica za koju je definiran prostorni indeks mora sadržavati primarni ključ ( PRIMARNI KLJUČ);
- XML Je još jedan poseban tip indeksa koji je dizajniran za stupce s XML tipom podataka. XML indeks poboljšava efikasnost obrade upita na XML stupcima. Postoje dvije vrste XML indeksa: primarni i sekundarni. Primarni XML indeks indeksira sve oznake, vrijednosti i staze pohranjene u XML stupcu. Može se kreirati samo ako tablica ima klasterirani indeks na primarnom ključu. Sekundarni XML indeks može se stvoriti samo ako tablica ima primarni XML indeks i koristi se za poboljšanje performansi upita o određenoj vrsti pristupa XML stupcu, stoga postoji nekoliko vrsta sekundarnih indeksa: PATH, VALUE i PROPERTY;
- Postoje i posebni indeksi za tablice optimizirane za memoriju ( OLTP u memoriji) kao što su: Hash ( Hash) indekse i neklasterizirane indekse optimizirane u memoriji koji su stvoreni za skeniranje raspona i naručenih skeniranja.
Stvaranje i ispuštanje indeksa u Microsoft SQL Serveru
Prije nego što krenete u kreiranju indeksa, on mora biti dobro osmišljen kako bi mogao učinkovito koristiti indeks, jer loše dizajnirani indeksi možda ne povećavaju rad, već ga smanjuju. Na primjer, veliki broj indeksa na tablici degradira performanse izraza INSERT, UPDATE, DELETE i MERGE jer kad se podaci u tablici promijene, svi indeksi se moraju u skladu s tim promijeniti. Mi ćemo razmotriti opće smjernice za dizajn indeksa u zasebnom članku, ali sada idemo izravno na postupak stvaranja i ispadanja indeksa.
Bilješka! Moj SQL server je Microsoft SQL Server 2016 Express.
Izrada indeksa
Postoje dva načina kreiranja indeksa u Microsoft SQL Serveru: prvi je pomoću grafičkog sučelja SQL Server Management Studio (SSMS), a drugi pomoću Transact-SQL, provest ćemo vas kroz obje metode.
Početni podaci za primjere
Zamislimo da imamo tablicu proizvoda pod nazivom TestTable koja ima tri stupca:
- ProductId - identifikator proizvoda;
- Ime proizvoda - naziv proizvoda;
- CategoryID - kategorija proizvoda.
Primjer stvaranja klasteriranog indeksa
Kao što rekoh, klasterirani indeks stvara se automatski ako, primjerice, prilikom izrade tablice navedemo određeni stupac kao primarni ključ ( PRIMARNI KLJUČ), ali budući da nismo, pogledajmo primjer stvaranja samog klasteriranog indeksa.
Da bismo stvorili klasterirani indeks, možemo na tablici odrediti primarni ključ i na taj način će se klasterirani indeks stvoriti automatski, ili možemo kreirati klasterirani indeks odvojeno.
Na primjer, napravimo samo klasterirani indeks bez stvaranja primarnog ključa. Prvo, napravimo to koristeći Management Studio.
Otvorite SSMS i u istraživaču objekata pronađite potrebnu tablicu i desnom tipkom miša kliknite stavku " Indeksi", Odaberite" Kreirajte indeks"I tip indeksa, u našem slučaju" Klasterirana».

Obrazac " Novi indeks", Gdje trebamo navesti ime novog indeksa ( mora biti jedinstven unutar tablice), također naznačujemo da li će ovaj indeks biti jedinstven, ako u tablici proizvoda govorimo o identifikatoru proizvoda, onda, naravno, mora biti jedinstven. Zatim odaberite stupac ( indeks ključ), na osnovu kojeg ćemo stvoriti klasterirani indeks, tj. redovi podataka u tablici bit će sortirani pomoću gumba " Dodaj».

Nakon unosa svih potrebnih parametara, kliknite " uredu", Kao rezultat će se stvoriti klasterirani indeks.

Isto tako, mogao bi se stvoriti klasterirani indeks koristeći T-SQL izraz CREATRE INDEXna primjer ovako
USTVARITE JEDINSTVENI KLASIRANI INDEKS IX_Clustered ON TestTable (ProductId ASC) GO
Ili, kao što smo rekli, možete koristiti i upute za kreiranje primarnog ključa, na primjer
ALTER TABLE TestTable ADD CONSTRAINT PK_TestTable PRIMARY KEY CLUSTERED (ProductId ASC) GO
Primjer stvaranja indeksa bez klastera sa uključenim stupcima
Sada pogledajmo primjer stvaranja neklasteriziranog indeksa, dok ćemo označiti stupce koji neće biti ključni, ali će biti uključeni u indeks. Ovo je korisno u slučajevima kada na primjer kreirate indeks za određenu upit, tako da indeks u potpunosti pokriva upit, tj. sadržavao sve stupce ( ovo se zove "Zatraži pokriće"). Pokrivanje upita poboljšava performanse jer alat za optimizaciju upita može pronaći sve vrijednosti stupca u indeksu bez pristupa podacima tablice, što rezultira manjim brojem I / O operacija na disku. Ali imajte na umu da uključivanje neslonskih stupaca u indeks povećava veličinu indeksa; potrebno je više prostora na disku za pohranjivanje indeksa, a performanse INSERT, UPDATE, DELETE i MERGE operacija na donjoj tablici također mogu degradirati.
Da bismo stvorili neklasterirani indeks pomoću GUI Management Studio, također pronalazimo željenu tablicu i stavku indeksa, samo u ovom slučaju odabiremo „ Stvori -\u003e Indeks bez klastera».

Nakon otvaranja obrasca " Novi indeks"Ukazujemo na naziv indeksa, dodamo ključ stupaca ili stupaca pomoću gumba" Dodaj", Na primjer, za naš testni slučaj, navedimo CategoryID.

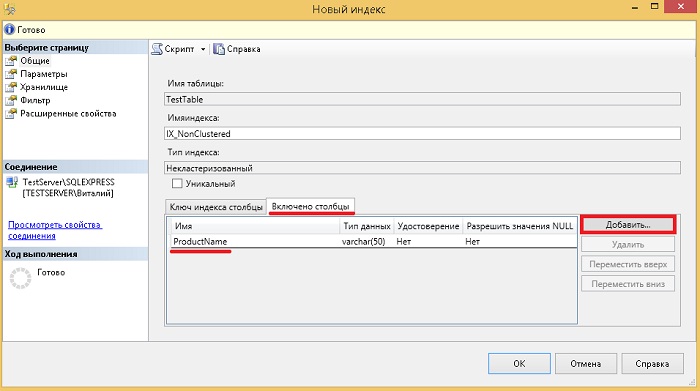
U Transact-SQL-u izgleda ovako.
IZRADITE NEKLUSTIRANI INDEKS IX_NonClustered ON TestTable (CategoryID ASC) UKLJUČUJE (Ime proizvoda) GO
Primjer pada indeksa u Microsoft SQL Serveru
Da biste izbrisali indeks, desnom tipkom miša kliknite željeni indeks i kliknite " Izbriši", A zatim potvrdite svoju radnju klikom na" uredu».

ili možete takođe koristiti uputstva DROP INDEXnpr
DROP INDEX IX_NonClustered ON TestTable
Imajte na umu da se izjava DROP INDEX ne odnosi na indekse koji su stvoreni stvaranjem PRIMARY KEY i UNIQUE ograničenja. U ovom slučaju za ispuštanje indeksa morate koristiti izraz ALTER TABLE s klauzulom DROP CONSTRAINT.
Optimizacija indeksa u Microsoft SQL Serveru
Kao rezultat obavljanja operacija ažuriranja, dodavanja ili brisanja podataka u SQL tablicama, poslužitelj automatski vrši odgovarajuće promjene indeksa, ali s vremenom, sve ove promjene mogu prouzrokovati fragmentaciju podataka u indeksu, tj. bit će raštrkane po cijeloj bazi podataka. Fragmentacija indeksa povlači za sobom smanjenje performansi upita, pa je povremeno potrebno izvoditi operacije održavanja indeksa, naime defragmentaciju, poput operacija reorganizacije indeksa i ponovne izgradnje.
Kada koristiti reorganizaciju indeksa i kada obnoviti?
Da biste odgovorili na ovo pitanje, prvo morate odrediti stepen fragmentacije indeksa, jer ovisno o fragmentaciji indeksa, jedna ili druga metoda defragmentacije bit će poželjna i efikasna. Možete koristiti funkciju sistemske tablice za određivanje stupnja fragmentacije indeksa sys.dm_db_index_physical_statskoji vraća detaljne podatke o veličini i fragmentaciji indeksa. Na primjer, pomoću sljedećeg upita možete saznati stupanj fragmentacije indeksa za sve tablice u trenutnoj bazi podataka.
SELECT OBJECT_NAME (T1.object_id) AS NameTable, T1.index_id AS IndexId, T2.name AS IndexName, T1.avg_fragmentation_in_percent AS Fragmentacija OD sys.dm_db_index_physical_stats (DB_ID (), NULL, NULL), NULL, NULL) indekse AS T2 ON T1.object_id \u003d T2.object_id AND T1.index_id \u003d T2.index_id
U ovom slučaju nas zanima kolona avg_fragmentation_in_percenttj. postotak logičke fragmentacije.
- Ako je stopa fragmentacije manja od 5%, tada se reorganizacija ili ponovna izgradnja indeksa uopće ne bi smjela provoditi;
- Ako je stupanj fragmentacije od 5 do 30%, ima smisla započeti reorganizaciju indeksa, jer ova operacija koristi minimalne resurse sustava i ne zahtijeva dugotrajno zaključavanje;
- Ako je stupanj fragmentacije veći od 30%, tada je potrebno obnoviti indeks, jer ova operacija, uz značajnu fragmentaciju, ima veći učinak od operacije reorganizacije indeksa.
Osobno mogu dodati sljedeće ako imate malu tvrtku i baza podataka ne zahtijeva maksimalnu efikasnost 24 sata dnevno, tj. Budući da nije super aktivna baza podataka, sigurno možete povremeno izvoditi operaciju ponovne izrade indeksa, čak i ne utvrdivši stupanj fragmentacije.
Reorganizacija indeksa
Reorganizacija indeksa Je li postupak defragmentacije indeksa koji defragmentira razinu lista klasteriranih i neklasteriziranih indeksa po tablicama i prikazima, fizički raspoređujući stranice na razini lista u skladu s logičkim redoslijedom ( s lijeva na desno) krajnji čvorovi.
Za reorganizaciju indeksa možete koristiti i grafički SSMS alat i Transact-SQL izraz.
Reorganizacija indeksa pomoću Studio za upravljanje

Reorganizacija indeksa koristeći Transact-SQL
ALTER INDEX IX_NonClustered ON TestTable REORGANIZE GO
Obnova indeksa
Obnova indeksa Je li postupak kojim se stari indeks briše i stvara se novi, uslijed kojeg se fragmentacija eliminira.
Za obnovu indeksa možete koristiti dvije metode.
Prvi. Korištenje izraza ALTER INDEX s rečenicom REBUILD. Ova izjava zamjenjuje DBCC DBREINDEX izraz. Obično je to metoda koja se koristi za skupnu obnovu indeksa.
Primjer
ALTER INDEX IX_NonClustered ON TestTable REBUILD GO
I drugo, koristeći izraz CREATE INDEX s klauzurom DROP_EXISTING. Može se koristiti, na primjer, za obnovu indeksa s promjenom njegove definicije, tj. dodavanje ili uklanjanje stupaca ključeva.
Primjer
USTVARITE NEKLUSTIRANI INDEX IX_NonClustered ON TestTable (CategoryID ASC) SA (DROP_EXISTING \u003d ON) GO
Funkcija ponovne obnove dostupna je i u programu Studio Studio. Kliknite desnim klikom na željeni indeks " Obnovi».

Ovim se zaključuje materijal o osnovama indeksa u Microsoft SQL Serveru, ako vas zanima T-SQL jezik, onda preporučujem čitanje moje knjige "



