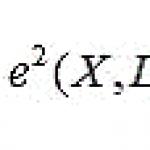1. Az adatok közvetlen felhasználása, ill adattárolás.
Ebben az esetben a kezdeti adatokat kifejezetten részletezett formában tárolják, és közvetlenül felhasználják a szakaszokban és/vagy kivételek elemzése... Ezzel a módszercsoporttal az a probléma, hogy használatuk során nehéz lehet nagyon nagy adatbázisokat elemezni.
E csoport módszerei: klaszteranalízis, legközelebbi szomszéd módszer, k-legközelebbi szomszéd módszer, analógiás érvelés.
2. A formalizált azonosítása és használata minták, vagy desztillációs sablonok.
Technológiával desztillációs sablonok A kiindulási adatokból egy információmintát (sablont) kinyerünk és formális konstrukciókká alakítunk, amelyek formája az alkalmazott adatbányászati módszertől függ. Ezt a folyamatot a szakaszban hajtják végre ingyenes keresés, a módszerek első csoportja elvileg nem rendelkezik ezzel a szakaszsal. Szakaszokban prediktív modellezésés kivételek elemzése szakasz eredményeit használják fel ingyenes keresés, sokkal kompaktabbak, mint maguk az adatbázisok. Emlékezzünk vissza, hogy ezeknek a modelleknek a felépítése értelmezhető az elemző által, vagy követhetetlen ("fekete dobozok").
Ebbe a csoportba tartozó módszerek: logikai módszerek; vizualizációs módszerek; kereszttáblás módszerek; egyenleteken alapuló módszerek.
A logikai módszerek vagy a logikai indukció módszerei a következők: fuzzy lekérdezések és elemzések; szimbolikus szabályok; döntési fák; genetikai algoritmusok.
Ennek a csoportnak a módszerei talán a leginkább értelmezhetőek - ezek formalizálják a talált mintákat, a legtöbb esetben a felhasználó szempontjából meglehetősen átlátható formában. Az eredményül kapott szabályok folytonos és diszkrét változókat tartalmazhatnak. Meg kell jegyezni, hogy a döntési fák könnyen átalakíthatók szimbolikus szabálykészletekké, ha egy szabályt generálunk a fa gyökerétől a fa gyökeréig vezető útvonal mentén. terminál teteje... A döntési fák és szabályok valójában egy probléma megoldásának különböző módjai, és csak képességeikben különböznek. Ráadásul a szabályok megvalósítását lassabb algoritmusok hajtják végre, mint a döntési fák indukciója.
Kereszttáblás módszerek: ügynökök, Bayes-i (bizalmi) hálózatok, kereszttáblás vizualizáció. Az utolsó módszer nem egészen felel meg az adatbányászat egyik tulajdonságának - a független keresésnek minták elemző rendszer. A kereszttáblák formájában történő információszolgáltatás azonban biztosítja az Adatbányászat fő feladatának - a minták keresésének - megvalósítását, ezért ez a módszer is az Adatbányászati módszerek egyikének tekinthető.
Egyenlet alapú módszerek.
Ennek a csoportnak a módszerei a feltárt mintákat matematikai kifejezések - egyenletek - formájában fejezik ki. Ezért csak numerikus változókkal dolgozhatnak, a más típusú változókat ennek megfelelően kell kódolni. Ez némileg korlátozza e csoport módszereinek alkalmazását, ennek ellenére széles körben alkalmazzák azokat különféle problémák, különösen előrejelzési problémák megoldásában.
E csoport főbb módszerei: statisztikai módszerek és neurális hálózatok
A statisztikai módszereket leggyakrabban az előrejelzési problémák megoldására alkalmazzák. A statisztikai adatelemzésnek számos módszere létezik, köztük a korreláció-regresszióanalízis, az idősorok korrelációja, az idősorok trendjeinek meghatározása, a harmonikus elemzés.
Egy másik osztályozás az adatbányászati módszerek teljes skáláját két csoportra osztja: statisztikai és kibernetikai módszerekre. Ez a felosztási séma a matematikai modellek tanításának különböző megközelítésein alapul.
Meg kell jegyezni, hogy kétféle megközelítés létezik a statisztikai módszerek adatbányászatként való osztályozására. Az első a statisztikai módszereket és az adatbányászatot állítja szembe, támogatói az adatelemzés külön irányának tekintik a klasszikus statisztikai módszereket. A második megközelítés szerint a statisztikai elemzési módszerek az Adatbányászat matematikai eszköztárának részét képezik. A legtöbb neves forrás a második megközelítést alkalmazza.
Ebben az osztályozásban a módszerek két csoportját különböztetjük meg:
- az átlagosan felhalmozott tapasztalatok felhasználásán alapuló statisztikai módszerek, amelyek tükröződnek a visszamenőleges adatokban;
- kibernetikai módszerek, amelyek sok heterogén matematikai megközelítést tartalmaznak.
Az ilyen osztályozás hátránya: mind a statisztikai, mind a kibernetikai algoritmusok valamilyen módon a statisztikai tapasztalatok összehasonlítására támaszkodnak a jelenlegi helyzet megfigyelésének eredményeivel.
Ennek az osztályozásnak az előnye, hogy könnyen értelmezhető – a modern megközelítés matematikai eszközeinek leírására szolgál. tudáskinyerés kezdeti megfigyelések tömbjéből (operatív és retrospektív), azaz. az adatbányászati feladatokban.
Nézzük meg közelebbről a fent bemutatott csoportokat.
Statisztikai adatbányászati módszerek
A módszerek négy egymással összefüggő szakaszt képviselnek:
- a statisztikai adatok jellegének előzetes elemzése (stacionaritási, normalitási, függetlenségi, homogenitási hipotézisek tesztelése, az eloszlásfüggvény formájának, paramétereinek értékelése stb.);
- linkek azonosítása és minták(lineáris és nemlineáris regresszióanalízis, korrelációs elemzés stb.);
- többváltozós statisztikai elemzés (lineáris és nemlineáris diszkriminanciaanalízis, klaszteranalízis, komponensanalízis, faktoranalízis satöbbi.);
- dinamikus modellekés idősoros előrejelzés.
A statisztikai módszerek arzenálja Az adatbányászat négy módszercsoportba sorolható:
- A kiindulási adatok leíró elemzése és leírása.
- Kapcsolatelemzés (korrelációs és regressziós elemzés, faktoranalízis, varianciaanalízis).
- Többváltozós statisztikai elemzés (komponensanalízis, diszkriminanciaanalízis, többváltozós regresszióanalízis, kanonikus korrelációk stb.).
- Idősor elemzés ( dinamikus modellekés előrejelzés).
Az adatbányászat kibernetikai módszerei
Az adatbányászat második iránya a számítógépes matematika gondolata és a mesterséges intelligencia elméletének alkalmazása által egyesített megközelítések összessége.
adatbányászat) és az online analitikai feldolgozás alapját képező "durva" feltáró elemzésen (OnLine Analytical Processing, OLAP), míg az adatbányászat egyik fő rendelkezése a nem nyilvánvaló keresés. minták... Az adatbányászati eszközök önmagukban is megtalálhatják az ilyen mintákat, és önállóan is hipotéziseket alkothatnak a kapcsolatokról. Mivel a függőségekre vonatkozó hipotézis megfogalmazása a legnehezebb feladat, az adatbányászat előnye más elemzési módszerekkel szemben nyilvánvaló.A legtöbb statisztikai módszer az adatok közötti kapcsolatok azonosítására a minta átlagolásának koncepcióját használja, ami nem létező értékeken végzett műveletekhez vezet, míg az adatbányászat valós értékeken működik.
Az OLAP alkalmasabb az előzményadatok megértésére, a Data Mining a múltbeli adatokra támaszkodik a jövővel kapcsolatos kérdések megválaszolásához.
Adatbányászati technológiai perspektívák
Az adatbányászatban rejlő lehetőségek zöld utat adnak a technológia határainak feszegetéséhez. Az adatbányászat kilátásait tekintve a következő fejlesztési irányok lehetségesek:
- a szakterületek típusainak azonosítása a megfelelő heurisztikákkal, amelyek formalizálása megkönnyíti az e területekhez kapcsolódó megfelelő adatbányászati problémák megoldását;
- formális nyelvek és logikai eszközök létrehozása, amelyek segítségével az érvelés formalizálódik, és amelyek automatizálása az adatbányászati problémák megoldásának eszközévé válik bizonyos tématerületeken;
- Adatbányászati módszerek létrehozása, amelyek nem csak mintákat tudnak kinyerni az adatokból, hanem empirikus adatokon alapuló elméleteket is alkotnak;
- az adatbányászati eszközök képességei és az e területen elért elméleti fejlődés közötti jelentős szakadék leküzdése.
Ha rövid távon tekintünk az adatbányászat jövőjére, akkor nyilvánvaló, hogy ennek a technológiának a fejlesztése leginkább az üzlettel kapcsolatos területekre irányul.
Rövid távon a Data Mining termékek olyan általánossá és nélkülözhetetlenné válhatnak, mint az e-mail, és például a felhasználók arra használhatják őket, hogy megtalálják a legalacsonyabb árakat egy adott termékhez vagy a legolcsóbb jegyeket.
Hosszú távon az adatbányászat jövője valóban izgalmas – lehet, hogy intelligens szerek keresnek különböző betegségek új kezelési módjait, illetve az univerzum természetének újszerű megértését.
Az adatbányászat azonban potenciális veszélyekkel jár – elvégre a világméretű hálózaton keresztül egyre több információ válik elérhetővé, beleértve a magánjellegű információkat is, és egyre több tudás nyerhető belőle:
Nem is olyan régen a legnagyobb online áruház, az Amazon volt a „Módszerek és rendszerek a felhasználók áruvásárlásának segítésére” szabadalom miatti botrány középpontjában, amely nem más, mint egy újabb adatbányászati termék, amelyet személyes adatok gyűjtésére terveztek az üzletről. látogatók. Az új módszertan lehetővé teszi a jövőbeni igények előrejelzését a vásárlások tényei alapján, valamint következtetések levonását azok céljára. Ennek a technikának az a célja, mint fentebb említettük, hogy a lehető legtöbb információt szerezzen az ügyfelekről, beleértve a magánjellegűeket is (nem, életkor, preferenciák stb.). Ily módon adatgyűjtés történik az áruház vásárlóinak, valamint családtagjaik, köztük a gyermekek magánéletének védelméről. Utóbbit számos ország jogszabályai tiltják - kiskorúakkal kapcsolatos információgyűjtés ott csak a szülők engedélyével lehetséges.
A kutatás megjegyzi, hogy vannak sikeres megoldások az adatbányászat használatával és rossz tapasztalatok is ezzel a technológiával. Azok a területek, ahol az adatbányászati technológia a legvalószínűbb, a következő tulajdonságokkal rendelkezik:
- tudásalapú megoldásokat igényelnek;
- változó környezettel rendelkeznek;
- hozzáférhető, elegendő és értelmes adatokkal rendelkezik;
- magas hozamot biztosít a megfelelő döntésekből.
Az elemzés meglévő megközelítései
Az adatbányászat tudományágat sokáig nem ismerték el az adatelemzés teljes értékű független területeként, néha a "statisztika hátsó udvarának" nevezik (Pregibon, 1997).
A mai napig az adatbányászattal kapcsolatban számos álláspont alakult ki. Egyikük támogatói délibábnak tartják, elvonja a figyelmet a klasszikus elemzésről.
Az Orosz Föderáció Oktatási és Tudományos Minisztériuma
Szövetségi Állami Költségvetési Szakmai Felsőoktatási Intézmény
"ORSZÁGOS KUTATÁSI TOMSZKI MŰSZAKI EGYETEM"
Kibernetikai Intézet
Irány Informatika és számítástechnika
VT osztály
Teszt
az informatika és számítástechnika tudományágban
Téma: Adatbányászati módszerek
Bevezetés
Adatbányászat. Alapfogalmak és definíciók
1 Az adatbányászati folyamat lépései
2 Bányászati rendszerek alkotóelemei
3 Az adatbányászat módszerei az adatbányászatban
Adatbányászati módszerek
1 Társulási szabályzat levezetése
2 Neurális hálózati algoritmusok
3 Nearest Neighbor és k-Nearest Neighbor Methods
4 Döntési fák
5 Klaszterezési algoritmusok
6 Genetikai algoritmusok
Alkalmazások
Adatbányászati eszközök gyártói
A módszerek kritikája
Következtetés
Bibliográfia
Bevezetés
Az információs technológia fejlődésének eredménye az elektronikus formában felhalmozott, rohamos ütemben növekvő adatmennyiség. Ezenkívül az adatok általában heterogén szerkezettel rendelkeznek (szövegek, képek, hangok, videók, hipertext dokumentumok, relációs adatbázisok). A hosszú időn keresztül felhalmozott adatok mintákat, trendeket és összefüggéseket tartalmazhatnak, amelyek értékes információk a tervezésben, előrejelzésben, döntéshozatalban és folyamatirányításban. Egy személy azonban fizikailag nem képes hatékonyan elemezni ilyen mennyiségű heterogén adatot. A hagyományos matematikai statisztika módszerei régóta tartják magukat az adatelemzés fő eszközének. Új hipotézisek szintetizálását azonban nem teszik lehetővé, csak a korábban megfogalmazott hipotézisek megerősítésére és az online analitikai feldolgozás (OLAP) alapját képező „durva” feltáró elemzésre használhatók. Gyakran egy hipotézis megfogalmazása bizonyul a legnehezebb feladatnak a későbbi döntéshozatali elemzés során, mivel az adatokban nem minden mintázat nyilvánvaló első pillantásra. Ezért az adatbányászati technológiákat az egyik legfontosabb és legígéretesebb kutatási és alkalmazási témának tekintik az információs technológiai iparban. Az adatbányászat ebben az esetben az új, helyes és potenciálisan hasznos ismeretek nagy mennyiségű adat alapján történő meghatározásának folyamatát jelenti. Így az MIT Technology Review az adatbányászatot a tíz feltörekvő technológia egyikeként írta le, amelyek megváltoztatják a világot.
1. Adatbányászat. Alapfogalmak és definíciók
Az adatbányászat a tudás korábban ismeretlen, nem triviális, gyakorlatiasan hasznos és hozzáférhető értelmezésének felderítése „nyers” adatokban, amely az emberi tevékenység különböző területein szükséges döntések meghozatalához.
Az adatbányászati technológia lényege és célja a következőképpen fogalmazható meg: ez egy olyan technológia, amelyet arra terveztek, hogy nagy mennyiségű adatban keressen nem nyilvánvaló, objektív és a gyakorlatban hasznos mintákat.
A nem nyilvánvaló minták olyan minták, amelyek nem észlelhetők szabványos információfeldolgozási módszerekkel vagy szakértői tanácsokkal.
Objektív törvényszerűségek alatt a valóságnak teljes mértékben megfelelő törvényszerűségeket kell érteni, ellentétben a mindig szubjektív szakértői véleményekkel.
Ez az adatelemzési koncepció a következőket feltételezi:
§ adatok lehetnek pontatlanok, hiányosak (hiányosak), ellentmondásosak, heterogének, közvetettek, ugyanakkor gigantikus terjedelműek; ezért az adatok specifikus alkalmazásokban való megértése jelentős intellektuális erőfeszítést igényel;
§ maguk az adatelemzési algoritmusok is rendelkezhetnek "intelligens elemekkel", különösen a precedensekből való tanulás képességével, azaz a magán megfigyelések alapján általános következtetések levonásával; az ilyen algoritmusok kidolgozása jelentős intellektuális erőfeszítést is igényel;
§ A nyers adatok információvá, illetve az információ tudássá feldolgozása manuálisan nem hajtható végre, automatizálást igényel.
Az adatbányászati technológia az adatok többdimenziós kapcsolatainak töredékeit tükröző minták (minták) koncepcióján alapul. Ezek a minták az adatok részmintáiban rejlő mintákat képviselnek, amelyek kompaktan, ember által olvasható formában kifejezhetők.
A minták keresése olyan módszerekkel történik, amelyeket nem korlátoznak a minta szerkezetére és az elemzett mutatók értékeinek eloszlásának típusára vonatkozó a priori feltételezések.
Az adatbányászat egyik fontos jellemzője, hogy a keresett minták nem szabványosak és nem nyilvánvalóak. Vagyis az adatbányászati eszközök abban különböznek a statisztikai adatfeldolgozó eszközöktől és az OLAP eszközöktől, hogy a felhasználók által előzetesen feltételezett kölcsönös függőségek ellenőrzése helyett a rendelkezésre álló adatok alapján önállóan is meg tudják találni ezeket az interdependenciákat, és hipotéziseket állítanak fel természetükről. . Az adatbányászati módszerek öt szabványos mintatípust azonosítanak:
· Társulás - az események egymással való összekapcsolásának nagy valószínűsége. Az asszociációra példa az üzletben található tételek, amelyeket gyakran együtt vásárolnak;
· Sorozat – időben összefüggő események láncolatának nagy valószínűsége. Példa a sorozatra az a helyzet, amikor az egyik termék beszerzését követő bizonyos időn belül nagy valószínűséggel egy másik terméket vásárolnak meg;
· Osztályozás - vannak olyan jelek, amelyek azt a csoportot jellemzik, amelyhez ez vagy az esemény vagy tárgy tartozik;
· Klaszterezés - az osztályozáshoz hasonló és attól eltérő minta, hogy maguk a csoportok nincsenek megadva - az adatfeldolgozás során automatikusan észlelik őket;
· Ideiglenes minták – minták jelenléte bizonyos adatok viselkedésének dinamikájában. Az időbeli mintázat tipikus példája bizonyos áruk vagy szolgáltatások iránti kereslet szezonális ingadozása.
1.1 Az adatbányászati folyamat lépései
Hagyományosan az adatbányászati folyamatban a következő szakaszokat különböztetik meg:
1. A témakör tanulmányozása, melynek eredményeként megfogalmazódnak az elemzés főbb céljai.
2. Adatgyűjtés.
Adatok előfeldolgozása:
a. Adattisztítás - az inkonzisztenciák és a véletlenszerű "zaj" kiküszöbölése az eredeti adatokból
b. Az adatintegráció a több lehetséges forrásból származó adatok egyetlen tárba történő összevonása. Adatátalakítás. Ebben a szakaszban az adatok elemzésre alkalmas formába kerülnek. Általánosan használt adatösszesítés, attribútum-mintavétel, adattömörítés és méretcsökkentés.
4. Adatelemzés. Ebben a szakaszban bányászati algoritmusokat alkalmaznak a minták kinyerésére.
5. A talált minták értelmezése. Ez a lépés magában foglalhatja a kinyert minták megjelenítését, az igazán hasznos minták azonosítását valamilyen segédfunkció alapján.
Új ismeretek felhasználása.
1.2 Bányászati rendszerek összetevői
Az adatbányászati rendszerek általában a következő fő összetevőket tartalmazzák:
1. Adatbázis, adattárház vagy egyéb információs tárház. Ez lehet egy vagy több adatbázis, adattárház, táblázatok, egyéb tárolók, amelyek tisztíthatók és integrálhatók.
2. Adatbázis szerver vagy adattárház. A megadott szerver felelős a lényeges adatok kinyeréséért a felhasználó kérése alapján.
Tudásbázis. A tartományismeret jelzi, hogyan kell keresni és értékelni a kapott minták hasznosságát.
Tudásbányászati szolgáltatás. Az adatbányászati rendszer szerves része, és funkcionális modulokat tartalmaz olyan feladatokhoz, mint a jellemzés, az asszociációk keresése, az osztályozás, a klaszteranalízis és a varianciaanalízis.
Mintaértékelő modul. Ez a komponens kiszámítja a minták érdeklődését vagy hasznosságát.
Grafikus felhasználói felület. Ez a modul felelős a felhasználó és az adatbányászati rendszer közötti kommunikációért, a minták különféle formájú megjelenítéséért.
1.3 Az adatbányászat módszerei az adatbányászatban
Az adatbányászati technológiában használt analitikai módszerek többsége jól ismert matematikai algoritmusok és módszerek. Alkalmazásukban újdonság, hogy a hardver és szoftver feltörekvő képességei miatt bizonyos speciális problémák megoldásában is alkalmazhatók. Megjegyzendő, hogy az adatbányászati módszerek többségét a mesterséges intelligencia elméletének keretein belül fejlesztették ki. Tekintsük a legszélesebb körben használt módszereket:
Az egyesületi szabályzat megkötése.
2. Neurális hálózati algoritmusok, amelyek ötlete az idegszövet működésével való analógián alapul, és abban a tényben rejlik, hogy a kezdeti paramétereket olyan jeleknek tekintik, amelyek a "neuronok" közötti meglévő kapcsolatoknak megfelelően átalakulnak. a teljes hálózat válaszát pedig az eredeti adatok elemzéséből származó válasznak tekintjük.
A kiindulási adatok szoros analógjának kiválasztása a meglévő történeti adatokból. A "legközelebbi szomszéd" módszernek is nevezik.
A döntési fák egy olyan hierarchikus struktúra, amely olyan kérdéseken alapul, amelyekre „igen” vagy „nem” választ kell adni.
A fürtmodellek a hasonló események csoportokba csoportosítására szolgálnak egy adatkészlet több mezőjének hasonló értékei alapján.
A következő fejezetben a fenti módszereket ismertetjük részletesebben.
2. Adatbányászati módszerek
2.1 A társulási szabályok levezetése
A társulási szabályok "ha ... akkor ..." alakú szabályok. Ilyen szabályok keresése egy adatkészletben rejtett kapcsolatokat tár fel a látszólag független adatokban. Az asszociációs szabályok keresésének egyik leggyakrabban idézett példája a stabil kapcsolatok megtalálásának problémája a kosárban. A kihívás annak meghatározása, hogy a vásárlók mely termékeket vásárolják együtt, hogy a marketingesek megfelelően el tudják helyezni ezeket a termékeket az üzletben az eladások növelése érdekében.
Az asszociációs szabályok (X1, X2, ..., Xn) -> Y formájú utasítások, ahol feltételezzük, hogy Y jelen lehet egy tranzakcióban, feltéve, hogy X1, X2, ..., Xn jelen van. ugyanabban a tranzakcióban. Meg kell jegyezni, hogy a "lehet" szó arra utal, hogy a szabály nem azonosság, hanem csak bizonyos valószínűséggel áll fenn. Ezenkívül Y lehet elemek halmaza, nem pedig egyetlen elem. Annak a valószínűségét, hogy egy olyan tranzakcióban találunk Y-t, amelyben X1, X2,…, Xn elemek vannak, bizalminak nevezzük. Támogatásnak nevezzük a szabályt tartalmazó tranzakciók százalékos arányát az összes tranzakcióból. Azt a megbízhatósági szintet, amelyet egy szabálynak meg kell haladnia, érdekességnek nevezzük.
Különféle típusú társulási szabályok léteznek. A legegyszerűbb formájukban az egyesületi szabályok csak a társulás meglétét vagy hiányát jelentik. Az ilyen szabályokat logikai asszociációs szabálynak nevezik. Példa egy ilyen szabályra: "Azok a vásárlók, akik joghurtot vásárolnak, zsírszegény vajat is vásárolnak."
Azokat a szabályokat, amelyek több társítási szabályt egyesítenek, többszintű vagy általánosított társítási szabályoknak nevezzük. Az ilyen szabályok megalkotásakor az elemeket általában hierarchia szerint csoportosítják, és a keresések a legmagasabb fogalmi szinten zajlanak. Például "a tejet vásárló vásárlók kenyeret is vásárolnak". Ebben a példában a tej és a kenyér különböző típusú és márkák hierarchiáját tartalmazza, de az alsó szinten végzett keresés nem talál érdekes szabályokat.
Egy bonyolultabb szabálytípus a mennyiségi asszociációs szabályok. Az ilyen típusú szabályokat mennyiségi (például ár) vagy kategorikus (például nem) attribútumokkal keresi, és a következőképpen definiálja: (
A fenti szabálytípusok nem foglalkoznak azzal a ténnyel, hogy a tranzakciók természetüknél fogva időfüggőek. Például egy termék eladásra kerülése előtt vagy a piacról való eltűnése után történő keresés hátrányosan befolyásolja a támogatási küszöböt. Ezt szem előtt tartva bevezették az attribútum élettartamának fogalmát az Időbeli asszociációs szabályok keresési algoritmusaiban.
Az asszociációs szabályok megtalálásának problémája általában két részre bontható: gyakran előforduló elemhalmazok keresése, és szabályok generálása a talált gyakran előforduló halmazok alapján. A korábbi kutatások többnyire ezeket az irányokat követték, és különféle irányokba terjesztették ki.
Az Apriori algoritmus megjelenése óta ez az algoritmus volt a leggyakrabban használt az első lépésben. Számos fejlesztés, például a sebesség és a skálázhatóság célja az Apriori algoritmus javítása, annak a hibás tulajdonságának kijavítása, hogy túl sok jelöltet generál a leggyakoribb elemkészletekhez. Az Apriori csak az előző lépésben talált nagy elemkészletek felhasználásával állít elő elemkészleteket, a tranzakciók újbóli vizsgálata nélkül. A módosított AprioriTid algoritmus úgy javítja az Apriorit, hogy csak az adatbázist használja az első lépésben. A következő lépésekben a számítások csak az első lépésben generált adatokat használják fel, amelyek sokkal kisebbek, mint az eredeti adatbázis. Ez óriási termelékenységnövekedéshez vezet. Az algoritmus továbbfejlesztett változata, az AprioriHybrid, úgy érhető el, hogy az első néhány lépésben Apriorit használunk, majd a későbbi lépéseknél, amikor a k-adik jelölthalmaz már teljes egészében lefoglalható a számítógép memóriájában, át kell váltani az AprioriTid-re.
Az Apriori algoritmus továbbfejlesztésére tett további erőfeszítések az algoritmus párhuzamosításával (Count Distribution, Data Distribution, Candidate Distribution stb.), skálázásával (Intelligent Data Distribution, Hybrid Distribution), új adatstruktúrák, például fák bevezetésével kapcsolatosak. gyakran előforduló elemek (FP-növekedés ).
A második lépés többnyire hiteles és érdekes. Az új módosítások hozzáadják a fent leírt dimenziót, minőséget és időbeli támogatást a hagyományos logikai szabályokhoz. A szabályok megtalálásához gyakran evolúciós algoritmust használnak.
2.2 Neurális hálózati algoritmusok
A mesterséges neurális hálózatok egy matematikai apparátus alkalmazása eredményeként jelentek meg az emberi idegrendszer működésének vizsgálatában, annak reprodukálása érdekében. Nevezetesen: az idegrendszer tanulási és hibajavítási képessége, aminek lehetővé kell tennie az emberi agy munkájának szimulálását, bár meglehetősen nyersen. A neurális hálózat fő szerkezeti és funkcionális része a formális neuron, az ábrán látható. 1, ahol x0, x1, ..., xn a bemeneti jelek vektorának összetevői, w0, w1, ..., wn a neuron bemeneti jeleinek súlyának értékei, y pedig a neuron kimeneti jele.
Rizs. 1. Formális neuron: szinapszisok (1), adder (2), transzducer (3).
A formális neuron 3 típusú elemből áll: szinapszisokból, összeadóból és transzducerből. A szinapszis két neuron közötti kapcsolat erősségét jellemzi.
Az összeadó összeadja a bemeneti jeleket a megfelelő súlyokkal előre megszorozva. A konverter egy argumentum – az összeadó kimenetének – funkcióját valósítja meg. Ezt a funkciót az idegsejt aktiválási függvényének vagy átviteli függvényének nevezik.
A fent leírt formális neuronok úgy kombinálhatók, hogy egyes neuronok kimenőjelei bemennek másokhoz. Az így létrejövő összekapcsolt neuronhalmazt mesterséges neurális hálózatoknak (ANN) nevezzük, vagy röviden neurális hálózatoknak.
A neurális hálózatban elfoglalt helyüktől függően három általános típusú neuron létezik:
Bemeneti neuronok, amelyek bemeneti jeleket fogadnak. Az ilyen neuronoknak, a neuronoknak általában egy egységsúllyal rendelkező bemenetük van, nincs torzítás, és az idegsejt kimenetének értéke megegyezik a bemeneti jellel;
Kimeneti neuronok (kimeneti csomópontok), amelyek kimeneti értékei a neurális hálózat eredő kimeneti jeleit jelentik;
Rejtett neuronok, amelyeknek nincs közvetlen kapcsolatuk a bemeneti jelekkel, míg a rejtett neuronok kimeneti jeleinek értékei nem az ANN kimeneti jelei.
Az interneuronális kapcsolatok szerkezete szerint az ANN két osztályát különböztetjük meg:
Közvetlen terjedésű ANN-ok, amelyekben a jel csak a bemeneti neuronoktól a kimeneti neuronokhoz terjed.
Ismétlődő ANN - ANN visszajelzéssel. Az ilyen ANN-okban a jelek bármely neuron között továbbíthatók, függetlenül azok elhelyezkedésétől az ANN-ban.
Az ANN tanításának két általános megközelítése van:
Tanulás tanárral.
Tanulás tanár nélkül.
A felügyelt tanulás előre meghatározott tanítási példák felhasználását jelenti. Mindegyik példa a bemeneti jelek vektorát és a referencia kimeneti jelek megfelelő vektorát tartalmazza, amelyek az adott feladattól függenek. Ezt a készletet edzőkészletnek vagy edzőkészletnek nevezik. A neurális hálózat képzése az ANN kapcsolatok súlyának olyan megváltoztatására irányul, amelyben az ANN kimeneti jelek értéke a lehető legkisebb mértékben tér el az adott bemeneti vektorhoz szükséges kimeneti jelek értékétől. jeleket.
A felügyelet nélküli tanulás során a kapcsolatok súlyát vagy az idegsejtek közötti versengés eredményeként, vagy az olyan neuronok kimeneti jeleinek korrelációját figyelembe véve, amelyek között kapcsolat van. Felügyelet nélküli tanulás esetén a képzési minta nem kerül felhasználásra.
A neurális hálózatokat számos feladat megoldására használják, például az űrsiklók hasznos teherének tervezésére és az árfolyamok előrejelzésére. Az adatbányászati rendszerekben azonban nem gyakran használják őket a modell összetettsége (a több száz interneurális kapcsolat súlyaként rögzített tudás teljesen felülmúlja az ember elemzését és értelmezését), valamint a nagy képzési mintán való hosszú betanítási idő miatt. Másrészt a neurális hálózatok olyan előnyökkel rendelkeznek az adatelemzési feladatokban, mint a zajos adatokkal szembeni ellenállás és a nagy pontosság.
2.3 Legközelebbi szomszéd és k-Legközelebbi szomszéd módszer
A legközelebbi szomszéd algoritmus és a k-legközelebbi szomszéd algoritmus (KNN) a jellemzők hasonlóságán alapul. A legközelebbi szomszéd algoritmus az összes ismert objektum közül kiválaszt egy objektumot, amely a lehető legközelebb van (az objektumok közötti távolság metrikájával, például az euklideszi mérőszámmal) egy új, korábban ismeretlen objektumhoz. A legközelebbi szomszéd módszerrel a fő probléma a képzési adatok kiugró értékeire való érzékenysége.
A leírt probléma elkerülhető a KNN algoritmussal, amely az összes megfigyelés között megkülönböztet egy új objektumhoz hasonló, már k-os legközelebbi szomszédot. A legközelebbi szomszédok osztályai alapján születik döntés az új objektumról. Ennek az algoritmusnak egy fontos feladata a k együttható kiválasztása - a hasonlónak tekintett rekordok száma. Az algoritmus olyan módosítása, amelyben a szomszéd hozzájárulása arányos az új objektum távolságával (a k-súlyozott legközelebbi szomszédok módszere), lehetővé teszi a nagyobb osztályozási pontosság elérését. A k legközelebbi szomszédok módszere lehetővé teszi az előrejelzés pontosságának becslését is. Például minden k legközelebbi szomszéd azonos osztályú, akkor nagyon nagy a valószínűsége annak, hogy az ellenőrzött objektum azonos osztályú lesz.
Az algoritmus jellemzői közül érdemes megemlíteni az anomális kitörésekkel szembeni ellenállást, mivel kicsi annak a valószínűsége, hogy egy ilyen rekord a k-közeli szomszédok számába essen. Ha ez megtörtént, akkor a szavazásra gyakorolt (különösen súlyozott) befolyás (k> 2 esetén) szintén elhanyagolható, így a besorolási eredményre gyakorolt hatás is kicsi lesz. Emellett az előnyök közé tartozik az egyszerű megvalósítás, az algoritmus eredményének könnyű értelmezhetősége, az algoritmus módosításának lehetősége a legmegfelelőbb kombinációs függvények és metrikák használatával, amely lehetővé teszi az algoritmus egy adott feladathoz való igazítását. A KNN algoritmusnak számos hátránya is van. Először is, az algoritmushoz használt adatkészletnek reprezentatívnak kell lennie. Másodszor, a modell nem választható el az adatoktól: minden példát fel kell használni egy új példa osztályozásához. Ez a funkció erősen korlátozza az algoritmus használatát.
2.4 Döntési fák
A „döntési fák” kifejezés alatt az osztályozási szabályok hierarchikus, szekvenciális struktúrában történő megjelenítésén alapuló algoritmusok családját értjük. Ez az adatbányászati problémák megoldására szolgáló algoritmusok legnépszerűbb osztálya.
A döntési fák felépítésére szolgáló algoritmuscsalád lehetővé teszi egy adott esetre vonatkozó paraméter értékének előrejelzését más hasonló esetekre vonatkozó nagy mennyiségű adat alapján. Általában ennek a családnak az algoritmusait használják olyan problémák megoldására, amelyek lehetővé teszik az összes forrásadat több különálló csoportra való felosztását.
Ha a döntési fák felépítésére szolgáló algoritmusokat egy bemeneti adathalmazra alkalmazzák, az eredmény fa formájában jelenik meg. Az ilyen algoritmusok egy ilyen felosztás több szintjét is lehetővé teszik, az így létrejövő csoportokat (faágakat) más jellemzők alapján kisebb csoportokra osztva. Az osztás addig folytatódik, amíg a megjósolni kívánt értékek az összes kapott csoportra (a fa leveleire) azonosak nem lesznek (vagy a megjósolt paraméter folytonos értéke esetén bezáródnak). Ezeket az értékeket használják a modell alapján történő előrejelzésekhez.
A döntési fák felépítésére szolgáló algoritmusok működése a regressziós és korrelációs elemzési módszerek alkalmazásán alapul. A család egyik legnépszerűbb algoritmusa a CART (Classification and Regression Trees), amely egy faág adatainak két gyermekágra való felosztásán alapul; ebben az esetben az egyik vagy másik ág további felosztása attól függ, hogy a kezdeti adatokból mennyit ír le ez az ág. Számos más hasonló algoritmus lehetővé teszi egy ág felosztását több gyermekágra. Ebben az esetben az osztás a leírt adatágra vonatkozó legmagasabb korrelációs együttható alapján történik az osztás szerinti paraméter és a jövőben megjósolandó paraméter között.
A megközelítés népszerűsége egyértelműséggel és egyértelműséggel jár. De a döntési fák alapvetően nem képesek megtalálni a „legjobb” (legteljesebb és legpontosabb) szabályokat az adatokban. A jellemzők szekvenciális megtekintésének naiv elvét valósítják meg, és ténylegesen megtalálják a valós minták részeit, csak a logikus következtetés illúzióját keltve.
2.5 Klaszterezési algoritmusok
A klaszterezés az objektumok halmazának fürtöknek nevezett csoportokra bontásának feladata. A fő különbség a klaszterezés és az osztályozás között az, hogy a csoportok listája nincs egyértelműen meghatározva, és az algoritmus működése során kerül meghatározásra.
A klaszteranalízis alkalmazása általában a következő szakaszokra redukálódik:
· Objektumminta kiválasztása klaszterezéshez;
· Annak a változókészletnek a meghatározása, amellyel a mintában lévő objektumok kiértékelődnek. Ha szükséges, normalizálja a változók értékeit;
· Az objektumok közötti hasonlóság mértékének értékeinek kiszámítása;
· A klaszteranalízis módszerének alkalmazása hasonló objektumok (klaszterek) csoportjainak létrehozására;
· Elemzési eredmények bemutatása.
Az eredmények megszerzése és elemzése után lehetőség van a kiválasztott metrika és klaszterezési módszer módosítására az optimális eredmény eléréséig.
A klaszterező algoritmusok között hierarchikus és lapos csoportokat különböztetünk meg. A hierarchikus algoritmusok (más néven taxonómiai algoritmusok) nem egy mintapartíciót építenek diszjunkt fürtökké, hanem beágyazott partíciók rendszerét. Így az algoritmus kimenete egy klaszterfa, melynek gyökere a teljes minta, a levelek pedig a legkisebb klaszterek. A lapos algoritmusok az objektumok egy partícióját diszjunkt fürtökbe építik fel.
A klaszterezési algoritmusok másik osztályozása az egyértelmű és fuzzy algoritmusok közé tartozik. Az egyértelmű (vagy nem átfedő) algoritmusok minden mintaobjektumhoz fürtszámot rendelnek, vagyis minden objektum csak egy fürthöz tartozik. A fuzzy (vagy átfedő) algoritmusok minden objektumot valódi értékek halmazához társítanak, amelyek megmutatják az objektum klaszterekhez való viszonyának mértékét. Így minden objektum bizonyos valószínűséggel minden klaszterhez tartozik.
A hierarchikus klaszterezési algoritmusok között két fő típus létezik: alulról felfelé és felülről lefelé haladó algoritmusok. A felülről lefelé irányuló algoritmusok felülről lefelé elven működnek: először az összes objektumot egy klaszterbe helyezik, amelyet aztán egyre kisebb klaszterekre osztanak fel. Elterjedtebbek az alulról felfelé építkező algoritmusok, amelyek a munka elején minden objektumot külön klaszterbe helyeznek, majd a klasztereket egyre nagyobbakká egyesítik, amíg a mintában szereplő összes objektum egy klaszterbe kerül. Így létrejön a beágyazott partíciók rendszere. Az ilyen algoritmusok eredményeit általában fa formájában mutatják be.
A hierarchikus algoritmusok hátránya a teljes partíciók rendszere, amely redundáns lehet a megoldandó probléma kontextusában.
Fontolja meg most a lapos algoritmusokat. Ebben az osztályban a legegyszerűbbek a négyzettörvényes algoritmusok. Ezen algoritmusok klaszterezési problémája úgy tekinthető, mint az objektumok csoportokba való optimális felosztása. Ebben az esetben az optimalitás úgy definiálható, mint a partíció átlagos négyzetes hibájának minimalizálásának követelménye:
 ,
,
ahol c j - a klaszter "tömegközéppontja". j(pont az adott klaszter jellemzőinek átlagos értékeivel).
Ebben a kategóriában a leggyakoribb algoritmus a k-közép módszer. Ez az algoritmus adott számú, egymástól a lehető legtávolabb elhelyezkedő klasztert épít fel. Az algoritmus működése több szakaszra oszlik:
Véletlenszerűen válasszon k pontok, amelyek a klaszterek kezdeti "tömegközéppontjai".
2. Rendeljen minden objektumot a legközelebbi "tömegközépponttal" rendelkező klaszterhez.
Ha az algoritmus leállításának feltétele nem teljesül, térjen vissza a 2. ponthoz.
Az algoritmus működésének leállításának kritériumaként általában a négyzetes hiba minimális változását választják. Lehetőség van az algoritmus működésének leállítására is, ha a 2. lépésben nem kerültek át objektumok fürtről klaszterre. Ennek az algoritmusnak a hátrányai közé tartozik, hogy meg kell adni a particionáláshoz szükséges klaszterek számát.
A legnépszerűbb fuzzy klaszterezési algoritmus a c-means algoritmus. Ez a k-közép módszer módosítása. Az algoritmus lépései:
1. Válasszon ki egy kezdeti fuzzy partíciót n tárgyakat k klasztereket a tagsági mátrix kiválasztásával U méret n x k.
2. Az U mátrix segítségével keresse meg a fuzzy hibakritérium értékét:
 ,
,
ahol c k - egy fuzzy klaszter "tömegközéppontja". k:
3. Csoportosítsa át az objektumokat a fuzzy hibakritérium értékének csökkentése érdekében.
4. Térjen vissza a 2. lépéshez, amíg a mátrix meg nem változik U nem lesz jelentéktelen.
Előfordulhat, hogy ez az algoritmus nem működik, ha a klaszterek száma előre nem ismert, vagy minden objektumot egyértelműen egy klaszterhez kell hozzárendelni.
Az algoritmusok következő csoportját a gráfelméletre épülő algoritmusok alkotják. Az ilyen algoritmusok lényege, hogy az objektumok egy részét gráf formájában ábrázolják G = (V, E), amelynek csúcsai objektumoknak felelnek meg, és az élek súlya megegyezik az objektumok közötti "távolsággal". A gráfklaszterező algoritmusok előnye az áttekinthetőség, a viszonylagos könnyű implementáció és a geometriai megfontolások alapján történő különféle fejlesztések lehetősége. A fő algoritmusok az összekapcsolt komponensek kinyerésére szolgáló algoritmus, a minimális feszítőfa felépítésére szolgáló algoritmus és a rétegenkénti klaszterezési algoritmus.
Paraméter kiválasztásához Ráltalában páronkénti távolságeloszlások hisztogramját ábrázolják. Az adatok jól kifejezett klaszterstruktúrájával kapcsolatos problémák esetén a hisztogramnak két csúcsa lesz – az egyik a klaszteren belüli távolságoknak, a második a klaszterek közötti távolságoknak felel meg. Paraméter R e csúcsok közötti minimum zónájából van kiválasztva. Ugyanakkor a klaszterek számát meglehetősen nehéz szabályozni a távolsági küszöb segítségével.
A minimális feszítőfa algoritmus először megszerkeszti a minimális feszítőfát a gráfon, majd sorban eltávolítja a legnagyobb súlyú éleket. A rétegenkénti klaszterezési algoritmus a gráf összekapcsolt komponenseinek kiválasztásán alapul az objektumok (csúcsok) közötti bizonyos távolságok szintjén. A távolság szintjét a távolsági küszöb határozza meg c... Például, ha az objektumok közötti távolság, akkor.
A rétegről rétegre klaszterező algoritmus gráf részgráfok sorozatát alkotja G amelyek a klaszterek közötti hierarchikus kapcsolatokat tükrözik:
![]() ,
,
ahol G t = (V, E t )
- grafikon a szinten val vel t, ![]() ,
,
val vel t a távolság t-edik küszöbértéke, m a hierarchiaszintek száma,
G 0 = (V, o), o a kapott gráfélek üres halmaza t 0 = 1,
G m = G, azaz objektumok gráfja a távolságra (a gráf éleinek hosszára) vonatkozó korlátozások nélkül, mivel t m = 1.
A távolsági küszöbök megváltoztatásával ( val vel 0 , …, val vel m), ahol 0 = val vel 0 < val vel 1 < …< val vel m = 1, akkor szabályozható a kapott klaszterek hierarchiájának mélysége. Így a rétegről rétegre klaszterező algoritmus képes sík és hierarchikus adatparticionálást is létrehozni.
A klaszterezés lehetővé teszi a következő célok elérését:
· A szerkezeti csoportok azonosításával javítja az adatok megértését. A minta hasonló objektumok csoportjaira bontása lehetővé teszi a további adatfeldolgozás és döntéshozatal egyszerűsítését azáltal, hogy minden klaszterre saját elemzési módszert alkalmaz;
· Lehetővé teszi az adatok kompakt tárolását. Ehhez a teljes minta tárolása helyett hagyhat egy tipikus megfigyelést minden klaszterből;
· Új atipikus objektumok észlelése, amelyek nem szerepeltek egyetlen klaszterben sem.
A klaszterezést általában az adatelemzés segédeszközeként használják.
2.6 Genetikai algoritmusok
A genetikai algoritmusok az univerzális optimalizálási módszerek közé tartoznak, amelyek különféle típusú (kombinatorikus, általános problémák korlátozásokkal és korlátozás nélkül) és különböző bonyolultságú problémák megoldását teszik lehetővé. Ugyanakkor a genetikai algoritmusokra jellemző az egykritériumú és többszempontú keresés is nagy térben, amelynek tájképe nem egyenletes.
Ez a módszercsoport a modellgenerációk sorozatának iteratív evolúciós folyamatát alkalmazza, beleértve a szelekció, a mutáció és a keresztezés műveleteit. Az algoritmus kezdetén a populációt véletlenszerűen alakítjuk ki. A kódolt megoldások minőségének felmérésére a fitnesz függvényt használják, amely az egyes egyedek alkalmasságának kiszámításához szükséges. Az egyedek felmérésének eredménye szerint közülük a leginkább alkalmazkodottakat választják ki a keresztezésre. A kiválasztott egyedek genetikai keresztezési operátor segítségével történő keresztezése során utódok jönnek létre, amelyek genetikai információi a szülő egyedek közötti kromoszómális információcsere eredményeként jönnek létre. A létrehozott utódok új populációt alkotnak, és az utódok egy része mutálódik, ami genotípusuk véletlenszerű változásában fejeződik ki. A „Népességbecslés” – „Kiválasztás” – „Keresztezés” – „Mutáció” sorozatot tartalmazó szakaszt generációnak nevezzük. A népesség evolúciója ilyen generációk sorozatából áll.
A következő algoritmusokat különböztetjük meg az egyének keresztezésre való kiválasztásához:
· Panmixia. A szülőpárt alkotó mindkét egyed véletlenszerűen kerül kiválasztásra a teljes populációból. Bármely egyén több pár tagja lehet. Ez a megközelítés univerzális, de az algoritmus hatékonysága csökken a populáció méretének növekedésével.
· Kiválasztás. Szülőkké válhatnak a legalább átlagos kondíciójú egyének. Ez a megközelítés gyorsabb konvergenciát biztosít az algoritmusban.
· Beltenyésztés. A módszer szoros kapcsolaton alapuló pár kialakításon alapul. Itt rokonság alatt a populáció tagjai közötti távolságot értjük, mind a paramétertérben lévő egyedek geometriai távolsága, mind a genotípusok közötti Heming-távolság értelmében. Ezért különbséget kell tenni genotípusos és fenotípusos beltenyésztés között. A keresztezéshez a pár első tagját véletlenszerűen választják ki, a második pedig nagyobb valószínűséggel a hozzá legközelebb álló egyén lesz. A beltenyésztés a keresés helyi csomópontokban való koncentrálódásának tulajdonságával jellemezhető, ami tulajdonképpen a populáció különálló lokális csoportokra oszlásához vezet a táj szélsőséges gyanús területei körül.
· Kitenyésztés. Páralakítás távoli kapcsolat alapján, a legtávolabbi egyedek számára. Az outbreeding célja, hogy megakadályozza az algoritmus konvergenciáját a már megtalált megoldásokhoz, és arra kényszeríti az algoritmust, hogy új, feltáratlan területeket keressen.
Algoritmusok új sokaság kialakításához:
· Kiválasztás elmozdulással. Az azonos genotípusú egyedek közül azokat részesítik előnyben, akiknek az alkalmassága magasabb. Ezzel két célt valósítunk meg: a legjobban megtalált megoldások különböző kromoszómakészletekkel nem vesznek el, a populációban folyamatosan megmarad a kellő genetikai diverzitás. Az elmozdulás egy új populációt alkot távoli egyedekből, ahelyett, hogy az egyedek a jelenlegi megoldás köré csoportosulnának. Ezt a módszert több extrém feladatokhoz használják.
· Elit kiválasztás. Az elit szelekciós módszerek biztosítják, hogy a populáció legjobb tagjai garantáltan életben maradjanak. Ugyanakkor a legjobb egyedek egy része minden változás nélkül átmegy a következő generációba. Az elitszelekció által biztosított gyors konvergenciát megfelelő szülői szelekciós módszerrel lehet kompenzálni. Ebben az esetben gyakran alkalmazzák az outbreeding-et. Ez a "tenyésztés - elit szelekció" kombinációja az egyik leghatékonyabb.
· Versenyválasztás. A versenykiválasztás n versenyt valósít meg n személy kiválasztásához. Minden verseny a sokaságból vett k elemből álló mintára és a legjobb egyén kiválasztására épül. A leggyakoribb versenykiválasztás k = 2-vel.
A genetikai algoritmusok egyik legnépszerűbb alkalmazása az adatbányászat területén a legoptimálisabb modell keresése (egy adott terület sajátosságainak megfelelő algoritmus keresése). A genetikai algoritmusokat elsősorban a neurális hálózat topológiájának és súlyozásának optimalizálására használják. Lehetséges azonban önálló eszközként is használni őket.
3. Alkalmazási területek
Az adatbányászati technológiának nagyon széles körű alkalmazásai vannak, valójában egy univerzális eszközkészlet minden típusú adat elemzéséhez.
Marketing
Az egyik legkorábbi adatbányászati technológia alkalmazási területe a marketing volt. Az adatbányászati módszerek fejlesztését elindító feladatot bevásárlókosár elemzésnek nevezzük.
Ez a feladat azon termékek azonosítása, amelyeket a vásárlók együtt kívánnak megvásárolni. A bevásárlókosár ismerete szükséges a reklámkampányokhoz, a vásárlóknak szóló személyes ajánlások kialakításához, az árukészletek létrehozására vonatkozó stratégia kidolgozásához és az értékesítési területeken való elrendezésének módszereihez.
A marketingben is olyan feladatokat oldanak meg, mint egy adott termék célközönségének meghatározása a sikeresebb promóció érdekében; az időbeli minták tanulmányozása, amely segít a vállalkozásoknak a készletekkel kapcsolatos döntésekben; prediktív modellek létrehozása, amelyek lehetővé teszik a vállalkozások számára, hogy felismerjék az ügyfelek különböző kategóriáinak szükségleteit bizonyos viselkedéssel; a vásárlói hűség előrejelzése, amely lehetővé teszi, hogy viselkedésének elemzésekor előre azonosítsa az ügyfél távozásának pillanatát, és esetleg megelőzze egy értékes ügyfél elvesztését.
Ipar
Ezen a területen az egyik fontos irány a monitoring és a minőség-ellenőrzés, ahol elemző eszközök segítségével előre jelezhető a berendezés meghibásodása, a meghibásodások megjelenése, megtervezhető a javítási munkák. Egyes jellemzők népszerűségének előrejelzése és annak ismerete, hogy mely jellemzőket szokták együtt rendelni, elősegíti a termelés optimalizálását, a fogyasztók valós igényeihez igazítását.
Orvosság
Az orvostudományban az adatelemzést is meglehetősen sikeresen alkalmazzák. Példa a feladatokra a vizsgálati eredmények elemzése, diagnosztika, a kezelési módszerek és gyógyszerek hatékonyságának összehasonlítása, a betegségek és megoszlásuk elemzése, a mellékhatások azonosítása. Az adatbányászati technológiákat, például az asszociációs szabályokat és a szekvenciális mintákat sikeresen alkalmazták a gyógyszerbevitel és a mellékhatások közötti kapcsolatok azonosítására.
Molekuláris genetika és géntechnológia
A kísérleti adatok mintáinak feltárásának talán a legégetőbb és egyben legvilágosabb feladata a molekuláris genetika és a géntechnológia. Itt a markerek definíciójaként van megfogalmazva, amelyek genetikai kódok alatt értendők, amelyek egy élő szervezet bizonyos fenotípusos jellemzőit szabályozzák. Az ilyen kódok több száz, ezer vagy több kapcsolódó elemet tartalmazhatnak. Az adatok analitikus elemzésének eredménye egyben a genetikusok által felfedezett kapcsolat a személy DNS-szekvenciájában bekövetkezett változások és a különféle betegségek kialakulásának kockázata között.
Alkalmazott kémia
Az adatbányászati módszereket az alkalmazott kémia területén is alkalmazzák. Itt gyakran felmerül a kérdés, hogy meg kell tisztázni bizonyos vegyületek kémiai szerkezetének jellemzőit, amelyek meghatározzák a tulajdonságaikat. Ez a probléma különösen aktuális az összetett kémiai vegyületek elemzésénél, amelyek leírása több száz és ezer szerkezeti elemet és azok kötéseit tartalmazza.
A bűnözés elleni küzdelem
Az adatbányászati eszközöket viszonylag nemrégiben alkalmazzák a biztonság biztosításában, de már születtek gyakorlati eredmények, amelyek megerősítik az adatbányászat hatékonyságát ezen a területen. Svájci tudósok kifejlesztettek egy rendszert a tiltakozási tevékenység elemzésére, hogy előre jelezzék a jövőbeni incidenseket, valamint egy rendszert a feltörekvő kiberfenyegetések és a hackerek tevékenységének nyomon követésére a világon. Ez utóbbi rendszer lehetővé teszi a kiberfenyegetések és egyéb információbiztonsági kockázatok előrejelzését. Ezenkívül az adatbányászati módszereket sikeresen használják a hitelkártya-csalás felderítésére. A múltbeli tranzakciók elemzésével, amelyekről később kiderült, hogy csalás történt, a bank azonosítja az ilyen csalás néhány sztereotípiáját.
Egyéb alkalmazások
· Kockázatelemzés. Például a kifizetett kárigényekhez kapcsolódó tényezők kombinációjának azonosításával a biztosítók csökkenthetik felelősségi veszteségeiket. Ismert olyan eset, amikor egy nagy biztosítótársaság az Egyesült Államokban felfedezte, hogy a házasok nyilatkozatai alapján fizetett összeg kétszerese volt annak, mint a hajadonok nyilatkozatának. A cég erre az új tudásra reagált a családi vásárlók általános kedvezménypolitikájának felülvizsgálatával.
· Meteorológia. Időjárás-előrejelzés neurális hálózatokkal, különösen önszerveződő Kohonen térképekkel.
· Személyzeti politika. Az elemző eszközök segítségével a HR szolgálatok önéletrajzuk adatainak elemzése alapján kiválaszthatják a legsikeresebb jelölteket, modellezhetik az adott pozícióra ideális munkatársak jellemzőit.
4. Adatbányászati eszközök előállítói
Az adatbányászati eszközök hagyományosan a drága szoftvertermékek közé tartoznak. Ezért ennek a technológiának egészen a közelmúltig a bankok, a pénzügyi és biztosítótársaságok, a kereskedelmi nagyvállalatok voltak a fő fogyasztói, az Adatbányászat alkalmazását igénylő fő feladatok pedig a hitel- és biztosítási kockázatok felmérése, valamint a marketingpolitika, tarifatervek kidolgozása volt. és az ügyfelekkel való munka egyéb alapelvei. Az elmúlt években a helyzet bizonyos változásokon ment keresztül: viszonylag olcsó Data Mining eszközök, sőt ingyenes terjesztési rendszerek jelentek meg a szoftverpiacon, amelyek a kis- és középvállalkozások számára is elérhetővé tették ezt a technológiát.
A fizetős eszközök és adatelemző rendszerek közül a SAS Institute (SAS Enterprise Miner), az SPSS (SPSS, Clementine) és a StatSoft (STATISTICA Data Miner) a vezető. Elég jól ismertek az Angoss (Angoss KnowledgeSTUDIO), IBM (IBM SPSS Modeler), Microsoft (Microsoft Analysis Services) és (Oracle) Oracle Data Mining megoldásai.
Az ingyenes szoftverek választéka is változatos. Vannak univerzális elemző eszközök, mint például JHepWork, KNIME, Orange, RapidMiner, és speciális eszközök, például a Carrot2 - egy keretrendszer szöveges adatok és keresési eredmények klaszterezésére, Chemicalize.org - megoldás az alkalmazott kémia területén, NLTK (Natural Language Toolkit) természetes nyelvi feldolgozó eszköz.
5. A módszerek kritikája
Az adatbányászat eredményei nagymértékben az adatok előkészítésének szintjétől függenek, és nem egyes algoritmusok vagy algoritmuskészletek "csodálatos képességeitől". Az adatbányászattal kapcsolatos munka körülbelül 75%-a adatgyűjtésből áll, amelyre még az elemző eszközök használata előtt kerül sor. Az eszközök írástudatlan használata a vállalat potenciáljának értelmetlen elpazarolásához vezet, és néha több millió dollárt.
Herb Edelstein, az adatbányászat, az adatraktározás és a CRM világhírű szakértője szerint: „A Two Crows legújabb tanulmánya kimutatta, hogy az adatbányászat még mindig a kezdeti szakaszában van. Sok szervezet érdeklődik a technológia iránt, de csak néhányan hajtanak végre ilyen projekteket. Sikerült megtudnunk még egy fontos dolgot: az adatbányászat gyakorlati megvalósításának folyamata a vártnál bonyolultabbnak bizonyul, a csapatokat elragadta az a mítosz, hogy az adatbányászati eszközöket könnyű használni. Feltételezhető, hogy elég egy ilyen eszközt egy terabájtos adatbázison futtatni, és azonnal megjelennek a hasznos információk. Valójában egy sikeres adatbányászati projekthez szükség van a tevékenység lényegének megértésére, az adatok és eszközök ismeretére, valamint az adatelemzés folyamatára." Az adatbányászati technológia alkalmazása előtt tehát alaposan elemezni kell a módszerek által támasztott korlátokat és a hozzá kapcsolódó kritikus kérdéseket, valamint józanul fel kell mérni a technológia adottságait. A kritikus problémák közé tartoznak a következők:
1. A technológia nem tud választ adni olyan kérdésekre, amelyeket fel sem tettek. Nem helyettesítheti az elemzőt, csupán hatékony eszközt ad neki munkájának megkönnyítésére és javítására.
2. Az Adatbányászati alkalmazás fejlesztésének és működésének összetettsége.
Mivel ez a technológia egy multidiszciplináris terület, az adatbányászatot is magában foglaló alkalmazás fejlesztéséhez különböző szakterületek szakembereinek bevonása, valamint minőségi interakciójuk biztosítása szükséges.
3. Felhasználói képesítések.
A különböző adatbányászati eszközök eltérő fokú felhasználóbarátsággal rendelkeznek, és bizonyos felhasználói képesítéseket igényelnek. Ezért a szoftvernek meg kell felelnie a felhasználó képzettségi szintjének. Az adatbányászat használatát elválaszthatatlanul össze kell kapcsolni a felhasználó képzettségének javításával. Jelenleg azonban kevés olyan adatbányászati szakember van, aki jártas az üzleti folyamatokban.
4. A hasznos információk kinyerése lehetetlen az adatok lényegének alapos megértése nélkül.
A modell gondos kiválasztására és a talált függőségek vagy minták értelmezésére van szükség. Ezért az ilyen eszközökkel való munkavégzés szoros együttműködést igényel a téma szakértője és az adatbányászati eszköz specialistája között. Az állandó modelleket intelligensen integrálni kell az üzleti folyamatokba, hogy értékelni és frissíteni lehessen a modelleket. Az utóbbi időben az adatbányászati rendszereket az adattárház technológia részeként szállították.
5. Az adatok előkészítésének összetettsége.
A sikeres elemzéshez jó minőségű adat-előfeldolgozás szükséges. Elemzők és adatbázis-felhasználók szerint az előfeldolgozási folyamat a teljes adatbányászati folyamat akár 80%-át is igénybe veheti.
Így ahhoz, hogy a technológia magától működjön, rengeteg erőfeszítést és időt vesz igénybe, amit az előzetes adatelemzésre, modellválasztásra és annak korrekciójára fordítanak.
6. Hamis, megbízhatatlan vagy haszontalan eredmények nagy százaléka.
A Data Mining technológiák segítségével valóban nagyon értékes információkat találhat, amelyek jelentős előnyt jelenthetnek a további tervezésben, menedzsmentben, döntéshozatalban. Az adatbányászati módszerekkel kapott eredmények azonban gyakran tartalmaznak hamis és értelmetlen következtetéseket. Sok szakértő azzal érvel, hogy az adatbányászati eszközök hatalmas mennyiségű statisztikailag megbízhatatlan eredményt tudnak produkálni. Az ilyen eredmények százalékos arányának csökkentése érdekében ellenőrizni kell a kapott modellek megfelelőségét a tesztadatokon. A hamis következtetéseket azonban lehetetlen teljesen elkerülni.
7. Magas költség.
A minőségi szoftvertermék a fejlesztő jelentős erőfeszítéseinek eredménye. Ezért a Data Mining szoftvert hagyományosan drága szoftverterméknek tekintik.
8. Elegendő reprezentatív adat rendelkezésre állása.
Az adatbányászati eszközök a statisztikai eszközökkel ellentétben elméletileg nem igényelnek szigorúan meghatározott mennyiségű történelmi adatot. Ez a funkció pontatlan, hamis modellek észlelését és ennek eredményeként ezek alapján helytelen döntések meghozatalát okozhatja. A feltárt tudás statisztikai szignifikanciájának ellenőrzése szükséges.
neurális hálózati algoritmus klaszterező adatbányászat
Következtetés
Röviden ismertetjük az alkalmazási köröket, valamint kifejtjük az adatbányászati technológiával kapcsolatos kritikákat és a terület szakértőinek véleményét.
Listairodalom
1. Han és Micheline Kamber. Adatbányászat: fogalmak és technikák. Második kiadás. - Illinoisi Egyetem, Urbana-Champaign
Berry, Michael J. A. Adatbányászati technikák: marketinghez, értékesítéshez és ügyfélkapcsolat-kezeléshez – 2. kiadás.
Siu Nin Lam. Társítási szabályok felfedezése az adatbányászatban. - Az Illinoisi Egyetem Számítástechnikai Tanszéke, Urbana-Champaign
Küldje el a jó munkát a tudásbázis egyszerű. Használja az alábbi űrlapot
Azok a hallgatók, végzős hallgatók, fiatal tudósok, akik tanulmányaikban és munkájuk során használják fel a tudásbázist, nagyon hálásak lesznek Önnek.
Hasonló dokumentumok
- a vásárlói pályák elemzése a weboldal látogatásától az áruk vásárlásáig
- szolgáltatás hatékonyságának értékelése, áruhiány miatti meghibásodások elemzése
- a látogatók számára érdekes áruk összekapcsolása
- bevásárlókosár elemzés;
- prediktív modellek létrehozása a vásárlók és a vásárolt áruk osztályozási modelljei;
- ügyfélprofilok létrehozása;
- CRM, különböző kategóriák vásárlói lojalitásának felmérése, hűségprogramok tervezése;
- idősoros kutatásés időfüggések, a szezonális tényezők kiemelése, a promóciók hatékonyságának értékelése valós adatok széles skáláján.
- ügyfélbesorolás a hívások legfontosabb jellemzői (gyakorisága, időtartama stb.), SMS gyakorisága alapján;
- a vásárlói hűség azonosítása;
- csalás meghatározása stb.
- kockázatelemzés... A fizetett kárigényekhez kapcsolódó tényezők kombinációinak azonosításával a biztosítók csökkenthetik felelősségi veszteségeiket. Ismert eset, amikor egy biztosító társaság megállapította, hogy a házasok követelései után fizetett összeg kétszerese volt az egyedülállók követeléseinek. A cég válaszul átdolgozta családi kedvezménypolitikáját.
- csalások felderítése... A biztosítótársaságok úgy csökkenthetik a csalást, hogy sajátos sztereotípiákat keresnek a keresetekben, amelyek az ügyvédek, orvosok és az igénylők kapcsolatát jellemzik.
A DataMining feladatok osztályozása. Jelentések és összesítések készítése. A Data Miner szolgáltatásai a Statisticában. Osztályozási, klaszterezési és regressziós probléma. Elemző eszközök Statistica Data Miner. A probléma lényege az asszociációs szabályok keresése. Túlélési előrejelző elemzés.
szakdolgozat, hozzáadva 2011.05.19
Az adatbányászati technológia, mint ismeretlen adatok észlelésére szolgáló folyamat funkcionalitásának leírása. Neurális hálózati algoritmusok asszociatív szabályainak és mechanizmusainak következtetési rendszereinek tanulmányozása. Klaszterezési algoritmusok leírása és az adatbányászat alkalmazási területei.
teszt, hozzáadva 2013.06.14
A klaszterezés alapjai. Az adatbányászat használata a tudás „adatbázisokban való felfedezésének” módjaként. Klaszterezési algoritmusok kiválasztása. Adatok lekérése a távoli műhely adatbázis tárolójából. A tanulók és feladatok csoportosítása.
szakdolgozat hozzáadva 2017.10.07
Adatbányászat, az adatbányászat és a tudásfeltárás fejlődéstörténete. Az adatbányászat technológiai elemei és módszerei. A tudás felfedezésének lépései. Változás és eltérés észlelése. Kapcsolódó tudományágak, információkeresés és szövegkinyerés.
jelentés hozzáadva: 2012.06.16
A klaszterezési módszerek és algoritmusok alkalmazásából adódó problémák elemzése. Alapvető algoritmusok a klaszterezéshez. A RapidMiner szoftver gépi tanulási és adatelemzési környezetként. A klaszterezés minőségének felmérése Data Mining módszerekkel.
szakdolgozat, hozzáadva 2012.10.22
Adatrögzítési és -tárolási technológiák fejlesztése. Az információs adatfeldolgozás modern követelményeinek sajátossága. Az adatok többdimenziós kapcsolatainak töredékeit tükröző minták koncepciója a modern adatbányászati technológia középpontjában.
teszt, hozzáadva: 2010.09.02
Neurális hálózatok tőzsdei helyzet-előrejelzési és döntéshozatali felhasználásának elemzése a Trajan 3.0 neurális hálózatmodellező szoftvercsomag segítségével. Elsődleges adatok, táblázatok konvertálása. Ergonómikus programértékelés.
szakdolgozat, hozzáadva: 2011.06.27
Az evolúciós algoritmusok használatának nehézségei. Számítógépes rendszerek építése a természetes szelekció elvei alapján. A genetikai algoritmusok hátrányai. Példák evolúciós algoritmusokra. Az evolúciós modellezés irányai és szakaszai.
Üdvözöljük az Adatbányászati Portálon – egy egyedülálló portálon, amely a modern adatbányászati módszereknek szentelt.
Az adatbányászati technológiák a modern üzleti intelligencia és adatbányászat hatékony eszközei a rejtett minták felfedezéséhez és a prediktív modellek felépítéséhez. Az adatbányászat vagy tudásbányászat nem spekulatív érvelésen, hanem valós adatokon alapul.

Rizs. 1. Adatbányászati alkalmazás sémája
Problémameghatározás - A probléma megfogalmazása: adatok osztályozása, szegmentálás, prediktív modellek felépítése, előrejelzés.
Adatgyűjtés és -előkészítés - Adatgyűjtés és -előkészítés, tisztítás, ellenőrzés, ismétlődő rekordok törlése.
Modellkészítés - Modellkészítés, pontosság felmérése.
Knowledge Deployment - Modell alkalmazása egy adott probléma megoldására.
Az adatbányászatot nagyszabású elemzési projektek megvalósítására használják az üzleti élet, a marketing, az internet, a távközlés, az ipar, a geológia, az orvostudomány, a gyógyszeripar és más területeken.
Az adatbányászat lehetővé teszi, hogy a modern mintafelismerési módszerek és egyedi analitikai technológiák, köztük döntési fák és osztályozások, klaszterezés, neurális hálózati módszerek segítségével hatalmas adattömb átszitálása révén jelentős összefüggések és kapcsolatok felkutatása megkezdődjön. , és mások.
Az a felhasználó, aki először fedezte fel az adatbányászat technológiáját, lenyűgözi a rengeteg módszert és hatékony algoritmust, amelyek lehetővé teszik, hogy megoldásokat találjanak a nagy mennyiségű adat elemzésével kapcsolatos bonyolult problémák megoldására.
Általánosságban elmondható, hogy az adatbányászat egy olyan technológia, amelyet nagy mennyiségű adat keresésére terveztek. nyilvánvaló, célkitűzésés gyakorlatilag hasznos minták.
Az adatbányászat hatékony módszereken és algoritmusokon alapul, amelyeket nagy volumenű és méretű strukturálatlan adatok elemzésére fejlesztettek ki.
A lényeg az, hogy a nagy volumenű, nagy dimenziójú adatok struktúrától és kapcsolatoktól mentesnek tűnnek. Az adatbányászati technológia célja, hogy azonosítsa ezeket a struktúrákat, és olyan mintákat találjon, ahol első pillantásra káosz és önkény uralkodik.
Íme egy aktuális esettanulmány a gyógyszer- és gyógyszeripar adatbányászati alkalmazásairól.
A kábítószer-kölcsönhatások egyre nagyobb problémát jelentenek a modern egészségügyben.
Idővel nő a felírt gyógyszerek (recept nélkül és mindenféle kiegészítők) száma, így egyre valószínűbb, hogy a gyógyszerkölcsönhatások súlyos mellékhatásokat okozhatnak, amelyekről az orvosok és a betegek nem is tudnak.
Ez a terület a posztklinikai kutatásokhoz tartozik, amikor egy gyógyszer már piacra került és intenzíven alkalmazzák.
A klinikai vizsgálatok egy gyógyszer hatékonyságának értékelésére vonatkoznak, de nem veszik figyelembe ennek a gyógyszernek a kölcsönhatásait a piacon lévő más gyógyszerekkel.
A kaliforniai Stanford Egyetem kutatói megvizsgálták az Élelmiszer- és Gyógyszerügyi Hatóság (FDA) gyógyszermellékhatások adatbázisát, és megállapították, hogy két gyakran használt gyógyszer – az antidepresszáns paroxetin és a koleszterinszint csökkentésére használt pravasztatin – együtt alkalmazva növeli a cukorbetegség kialakulásának kockázatát.
Egy, az FDA adatain alapuló, hasonló elemzést végző tanulmány 47 korábban ismeretlen káros kölcsönhatást azonosított.
Ez figyelemre méltó, azzal a fenntartással, hogy a betegek által jelentett negatív hatások közül sok nem kerül felismerésre. Itt teheti meg a legjobbat az online keresés.
Közelgő adatbányászati tanfolyamok a StatSoft Data Analysis Academy-n 2020-ban
Az Adatbányászattal való ismerkedésünket az Adatelemző Akadémia csodálatos videóival kezdjük.
Feltétlenül nézze meg videóinkat, és megérti, mi az adatbányászat!
Videó 1. Mi az adatbányászat?
2. videó: Adatbányászati módszerek áttekintése: döntési fák, általánosított prediktív modellek, klaszterezés és még sok más
A JavaScript le van tiltva a böngészőjében
A kutatási projekt megkezdése előtt meg kell szerveznünk a külső forrásokból származó adatok beszerzésének folyamatát, most megmutatjuk, hogyan történik ez.
A videó bemutatja az egyedülálló technológiát STATISZTIKA Helyi adatbázis-feldolgozás és adatbányászati kapcsolat valós adatokkal.
Videó 3. Az adatbázisokkal való interakció sorrendje: grafikus felület SQL lekérdezések készítéséhez Helyi adatbázis-feldolgozási technológia
A JavaScript le van tiltva a böngészőjében
Most megvizsgáljuk azokat az interaktív fúrási technológiákat, amelyek hatékonyak a feltárási adatok elemzésében. Maga a fúrás kifejezés az adatbányászati technológia és a geológiai feltárás közötti kapcsolatot tükrözi.
4. videó: Interaktív fúrás: Feltárás és grafikus technikák az interaktív adatfeltáráshoz
A JavaScript le van tiltva a böngészőjében
Most megismerkedünk az asszociációk elemzésével (asszociációs szabályok), ezek az algoritmusok lehetővé teszik a valós adatokban létező kapcsolatok megtalálását. A kulcspont az algoritmusok hatékonysága nagy mennyiségű adat esetén.
A linkelemző algoritmusok eredménye, például az Apriori algoritmus, a vizsgált objektumokra adott, például 80%-os megbízhatósággal linkszabályok megtalálása.
A geológiában ezek az algoritmusok felhasználhatók ásványok feltáró elemzésére, például arra, hogy az A jellemző hogyan kapcsolódik a B és C tulajdonságokhoz.
Konkrét példákat találhat ilyen megoldásokra linkjeinket követve:
A kiskereskedelemben az Apriori algoritmus vagy azok módosításai lehetővé teszik a különböző termékek kapcsolatának vizsgálatát, például parfümök (parfüm - lakk - szempillaspirál stb.) vagy különböző márkájú áruk értékesítése során.
Az oldal legérdekesebb rovatainak elemzése az egyesületi szabályzat segítségével is hatékonyan elvégezhető.
Tehát nézze meg a következő videónkat.
Videó 5. Egyesületi szabályzat
A JavaScript le van tiltva a böngészőjében
Adjunk példákat az adatbányászat alkalmazására bizonyos területeken.
Online kereskedelem:
Kiskereskedelem: Elemezze az ügyfelek adatait hitelkártyák, kedvezménykártyák és egyebek alapján.
Az adatbányászati eszközökkel megoldott tipikus kiskereskedelmi feladatok:
A távközlési szektor korlátlan lehetőségeket nyit az adatbányászati módszerek, valamint a modern big data technológiák alkalmazására:
Biztosítás:
Az adatbányászat gyakorlati alkalmazását és konkrét problémák megoldását a következő videónkban mutatjuk be.
Webinárium 1. Webinárium "Gyakorlati adatbányászati feladatok: problémák és megoldások"
A JavaScript le van tiltva a böngészőjébenWebinar 2. Webinar "Adatbányászat és szövegbányászat: Példák valós problémák megoldására"
A JavaScript le van tiltva a böngészőjében
Az adatbányászat módszertanáról és technológiájáról a StatSoft tanfolyamokon szerezhet mélyebb ismereteket.