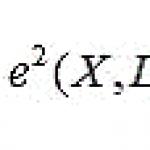1. მონაცემთა პირდაპირი გამოყენება, ან მონაცემთა საცავი.
ამ შემთხვევაში, საწყისი მონაცემები ინახება მკაფიოდ დეტალური ფორმით და უშუალოდ გამოიყენება ეტაპებზე და/ან გამონაკლისების გარჩევა... ამ ჯგუფის მეთოდების პრობლემა ის არის, რომ მათი გამოყენებისას შეიძლება რთული იყოს ძალიან დიდი მონაცემთა ბაზის ანალიზი.
ამ ჯგუფის მეთოდები: კლასტერული ანალიზი, უახლოესი მეზობლის მეთოდი, კ-უახლოესი მეზობლის მეთოდი, მსჯელობა ანალოგიით.
2. გაფორმებულის იდენტიფიცირება და გამოყენება ნიმუშები, ან დისტილაციის შაბლონები.
ტექნოლოგიით დისტილაციის შაბლონებიინფორმაციის ერთი ნიმუში (თარგი) ამოღებულია საწყისი მონაცემებიდან და გარდაიქმნება ზოგიერთ ფორმალურ კონსტრუქციად, რომლის ფორმა დამოკიდებულია მონაცემთა მოპოვების გამოყენებულ მეთოდზე. ეს პროცესი ეტაპობრივად ტარდება უფასო ძებნა, მეთოდთა პირველ ჯგუფს პრინციპში ეს ეტაპი არ გააჩნია. ეტაპობრივად პროგნოზირებადი მოდელირებადა გამონაკლისების გარჩევაგამოიყენება ეტაპის შედეგები უფასო ძებნა, ისინი ბევრად უფრო კომპაქტურია ვიდრე თავად მონაცემთა ბაზები. შეგახსენებთ, რომ ამ მოდელების კონსტრუქციების ინტერპრეტაცია შესაძლებელია ანალიტიკოსის მიერ ან გაუთვალისწინებელი („შავი ყუთები“).
მეთოდები ამ ჯგუფში: ლოგიკური მეთოდები; ვიზუალიზაციის მეთოდები; ჯვარედინი ცხრილების მეთოდები; განტოლებებზე დაფუძნებული მეთოდები.
ლოგიკური მეთოდები ანუ ლოგიკური ინდუქციის მეთოდები მოიცავს: ბუნდოვან შეკითხვებს და ანალიზებს; სიმბოლური წესები; გადაწყვეტილების ხეები; გენეტიკური ალგორითმები.
ამ ჯგუფის მეთოდები, ალბათ, ყველაზე ინტერპრეტაციებია - ისინი აფორმებენ ნაპოვნი შაბლონებს, უმეტეს შემთხვევაში, მომხმარებლის თვალსაზრისით საკმაოდ გამჭვირვალე ფორმით. შედეგად მიღებული წესები შეიძლება შეიცავდეს უწყვეტ და დისკრეტულ ცვლადებს. უნდა აღინიშნოს, რომ გადაწყვეტილების ხეები შეიძლება ადვილად გარდაიქმნას სიმბოლურ წესად, ერთი წესის წარმოქმნით ხის ფესვიდან მისკენ მიმავალ გზაზე. ტერმინალის ზედა... გადაწყვეტილების ხეები და წესები რეალურად ერთი პრობლემის გადაჭრის სხვადასხვა გზაა და განსხვავდება მხოლოდ მათი შესაძლებლობებით. გარდა ამისა, წესების იმპლემენტაცია ხორციელდება უფრო ნელი ალგორითმებით, ვიდრე გადაწყვეტილების ხეების ინდუქცია.
ჯვარედინი ცხრილების მეთოდები: აგენტები, ბაიესის (ნდობის) ქსელები, ჯვარედინი ტაბულური ვიზუალიზაცია. ბოლო მეთოდი საკმაოდ არ შეესაბამება მონაცემთა მოპოვების ერთ-ერთ თვისებას - დამოუკიდებელ ძიებას ნიმუშებიანალიტიკური სისტემა. თუმცა ინფორმაციის მიწოდება ჯვარედინი ცხრილების სახით უზრუნველყოფს მონაცემთა მოპოვების მთავარი ამოცანის - შაბლონების ძიებას შესრულებას, ამიტომ ეს მეთოდი ასევე შეიძლება ჩაითვალოს მონაცემთა მოპოვების ერთ-ერთ მეთოდად.
განტოლებაზე დაფუძნებული მეთოდები.
ამ ჯგუფის მეთოდები გამოვლენილ შაბლონებს გამოხატავს მათემატიკური გამონათქვამების - განტოლებების სახით. აქედან გამომდინარე, მათ შეუძლიათ მხოლოდ ციფრულ ცვლადებთან მუშაობა და სხვა ტიპის ცვლადები შესაბამისად უნდა იყოს კოდირებული. ეს გარკვეულწილად ზღუდავს ამ ჯგუფის მეთოდების გამოყენებას, მიუხედავად ამისა, ისინი ფართოდ გამოიყენება სხვადასხვა პრობლემის გადაჭრაში, განსაკუთრებით პრობლემების პროგნოზირებაში.
ამ ჯგუფის ძირითადი მეთოდები: სტატისტიკური მეთოდები და ნერვული ქსელები
სტატისტიკური მეთოდები ყველაზე ხშირად გამოიყენება პროგნოზირების პრობლემების გადასაჭრელად. არსებობს სტატისტიკური მონაცემების ანალიზის მრავალი მეთოდი, მათ შორის, მაგალითად, კორელაციულ-რეგრესიული ანალიზი, დროის სერიების კორელაცია, დროის სერიების ტენდენციების იდენტიფიცირება, ჰარმონიული ანალიზი.
სხვა კლასიფიკაცია მონაცემთა მოპოვების მეთოდთა მთელ მრავალფეროვნებას ყოფს ორ ჯგუფად: სტატისტიკურ და კიბერნეტიკური მეთოდებით. დაყოფის ეს სქემა ეფუძნება მათემატიკური მოდელების სწავლების სხვადასხვა მიდგომას.
უნდა აღინიშნოს, რომ სტატისტიკური მეთოდების მონაცემთა მოპოვების სახით კლასიფიკაციის ორი მიდგომა არსებობს. პირველი მათგანი უპირისპირდება სტატისტიკურ მეთოდებსა და მონაცემთა მოპოვებას, მისი მომხრეები კლასიკურ სტატისტიკურ მეთოდებს მონაცემთა ანალიზის ცალკე მიმართულებად მიიჩნევენ. მეორე მიდგომის მიხედვით, ანალიზის სტატისტიკური მეთოდები მონაცემთა მოპოვების მათემატიკური ინსტრუმენტარიუმის ნაწილია. ყველაზე ცნობილი წყაროები მეორე მიდგომას მიმართავენ.
ამ კლასიფიკაციაში გამოიყოფა მეთოდების ორი ჯგუფი:
- საშუალოდ დაგროვილი გამოცდილების გამოყენებაზე დაფუძნებული სტატისტიკური მეთოდები, რაც აისახება რეტროსპექტულ მონაცემებში;
- კიბერნეტიკური მეთოდები, რომლებიც მოიცავს მრავალ ჰეტეროგენულ მათემატიკურ მიდგომას.
ასეთი კლასიფიკაციის მინუსი: როგორც სტატისტიკური, ისე კიბერნეტიკური ალგორითმები ამა თუ იმ გზით ეყრდნობა სტატისტიკური გამოცდილების შედარებას არსებული სიტუაციის მონიტორინგის შედეგებთან.
ამ კლასიფიკაციის უპირატესობა არის მისი ინტერპრეტაციის მოხერხებულობა - იგი გამოიყენება თანამედროვე მიდგომის მათემატიკური ინსტრუმენტების აღსაწერად. ცოდნის მოპოვებასაწყისი დაკვირვებების მასივებიდან (ოპერატიული და რეტროსპექტული), ე.ი. მონაცემთა მოპოვების ამოცანებში.
მოდით უფრო ახლოს მივხედოთ ზემოთ მოცემულ ჯგუფებს.
სტატისტიკური მონაცემების მოპოვების მეთოდები
მეთოდები წარმოადგენს ოთხ ურთიერთდაკავშირებულ განყოფილებას:
- სტატისტიკური მონაცემების ბუნების წინასწარი ანალიზი (სტაციონარობის, ნორმალურობის, დამოუკიდებლობის, ჰომოგენურობის ჰიპოთეზების ტესტირება, განაწილების ფუნქციის ფორმის შეფასება, მისი პარამეტრები და ა.შ.);
- ბმულების იდენტიფიცირება და ნიმუშები(წრფივი და არაწრფივი რეგრესიული ანალიზი, კორელაციური ანალიზი და ა.შ.);
- მრავალვარიანტული სტატისტიკური ანალიზი (წრფივი და არაწრფივი დისკრიმინაციული ანალიზი, კლასტერული ანალიზი, კომპონენტის ანალიზი, ფაქტორული ანალიზიდა სხვ.);
- დინამიური მოდელებიდა დროის სერიების პროგნოზი.
სტატისტიკური მეთოდების არსენალი მონაცემთა მოპოვება კლასიფიცირებულია მეთოდების ოთხ ჯგუფად:
- აღწერითი ანალიზი და საწყისი მონაცემების აღწერა.
- ურთიერთობის ანალიზი (კორელაცია და რეგრესიული ანალიზი, ფაქტორული ანალიზი, დისპერსიის ანალიზი).
- მრავალვარიანტული სტატისტიკური ანალიზი (კომპონენტური ანალიზი, დისკრიმინაციული ანალიზი, მრავალვარიანტული რეგრესიული ანალიზი, კანონიკური კორელაციები და ა.შ.).
- დროის სერიების ანალიზი ( დინამიური მოდელებიდა პროგნოზირება).
მონაცემთა მოპოვების კიბერნეტიკური მეთოდები
მონაცემთა მოპოვების მეორე მიმართულება არის მიდგომების ერთობლიობა, რომელიც გაერთიანებულია კომპიუტერული მათემატიკის იდეით და ხელოვნური ინტელექტის თეორიის გამოყენებით.
მონაცემთა მოპოვება) და „უხეში“ საძიებო ანალიზზე, რომელიც საფუძვლად უდევს ონლაინ ანალიტიკურ დამუშავებას (OnLine Analytical Processing, OLAP), ხოლო მონაცემთა მოპოვების ერთ-ერთი მთავარი დებულებაა არააშკარა ნიმუშები... მონაცემთა მოპოვების ინსტრუმენტებს შეუძლიათ დამოუკიდებლად იპოვონ ასეთი შაბლონები და ასევე დამოუკიდებლად შექმნან ჰიპოთეზა ურთიერთობების შესახებ. ვინაიდან დამოკიდებულებების შესახებ ჰიპოთეზის ფორმულირება ყველაზე რთული ამოცანაა, მონაცემთა მოპოვების უპირატესობა ანალიზის სხვა მეთოდებთან შედარებით აშკარაა.სტატისტიკური მეთოდების უმეტესობა, რათა დადგინდეს ურთიერთობები მონაცემებში, იყენებს ნიმუშზე საშუალოდ გაანგარიშების კონცეფციას, რაც იწვევს ოპერაციებს არარსებულ მნიშვნელობებზე, ხოლო მონაცემთა მოპოვება მოქმედებს რეალურ მნიშვნელობებზე.
OLAP უფრო შესაფერისია ისტორიული მონაცემების გასაგებად, მონაცემთა მოპოვება ეყრდნობა ისტორიულ მონაცემებს მომავლის შესახებ კითხვებზე პასუხის გასაცემად.
მონაცემთა მოპოვების ტექნოლოგიების პერსპექტივები
მონაცემთა მოპოვების პოტენციალი მწვანე შუქს აძლევს ტექნოლოგიის საზღვრებს. რაც შეეხება მონაცემთა მოპოვების პერსპექტივებს, შესაძლებელია განვითარების შემდეგი მიმართულებები:
- საგნობრივი სფეროების ტიპების იდენტიფიცირება შესაბამისი ევრისტიკით, რომელთა ფორმალიზება ხელს შეუწყობს ამ სფეროებთან დაკავშირებული მონაცემთა მოპოვების შესაბამისი პრობლემების გადაჭრას;
- ფორმალური ენებისა და ლოგიკური საშუალებების შექმნა, რომელთა დახმარებითაც მოხდება მსჯელობის ფორმალიზება და რომლის ავტომატიზაცია გახდება მონაცემთა მოპოვების პრობლემების გადაჭრის ინსტრუმენტი კონკრეტულ საგნებში;
- მონაცემთა მოპოვების მეთოდების შექმნა, რომლებსაც შეუძლიათ არა მხოლოდ მონაცემებიდან შაბლონების ამოღება, არამედ ემპირიულ მონაცემებზე დაფუძნებული ზოგიერთი თეორიის ჩამოყალიბება;
- მონაცემთა მოპოვების ინსტრუმენტების შესაძლებლობებსა და ამ სფეროში თეორიულ მიღწევებს შორის მნიშვნელოვანი უფსკრულის დაძლევა.
თუ მოკლევადიან პერსპექტივაში განვიხილავთ მონაცემთა მაინინგის მომავალს, მაშინ აშკარაა, რომ ამ ტექნოლოგიის განვითარება ყველაზე მეტად მიმართულია ბიზნესთან დაკავშირებული სფეროებისკენ.
მოკლევადიან პერსპექტივაში, მონაცემთა მოპოვების პროდუქტები შეიძლება გახდეს ისეთივე გავრცელებული და აუცილებელი, როგორც ელ.წერილი და, მაგალითად, გამოიყენონ მომხმარებლებმა კონკრეტული პროდუქტის ან ყველაზე იაფი ბილეთების ყველაზე დაბალი ფასების მოსაძებნად.
გრძელვადიან პერსპექტივაში, მონაცემთა მოპოვების მომავალი მართლაც საინტერესოა - ეს შეიძლება იყოს ინტელექტუალური აგენტების ძიება სხვადასხვა დაავადების მკურნალობის ახალი მეთოდებისა და სამყაროს ბუნების ახალი გაგებისთვის.
თუმცა, მონაცემთა მოპოვება სავსეა პოტენციური საფრთხით - ყოველივე ამის შემდეგ, ინფორმაციის მზარდი რაოდენობა ხელმისაწვდომი ხდება მსოფლიო ქსელის საშუალებით, მათ შორის პირადი ინფორმაციის ჩათვლით, და მისგან უფრო და უფრო მეტი ცოდნის მიღებაა შესაძლებელი:
არც ისე დიდი ხნის წინ, უმსხვილესი ონლაინ მაღაზია "ამაზონი" სკანდალის ცენტრში აღმოჩნდა პატენტის "მეთოდები და სისტემები, რათა დაეხმაროს მომხმარებლებს საქონლის შეძენაში", რომელიც სხვა არაფერია, თუ არა მონაცემთა მოპოვების კიდევ ერთი პროდუქტი, რომელიც შექმნილია მაღაზიის შესახებ პერსონალური მონაცემების შესაგროვებლად. სტუმრები. ახალი მეთოდოლოგია შესაძლებელს ხდის სამომავლო მოთხოვნების პროგნოზირებას შესყიდვების ფაქტებზე დაყრდნობით, ასევე მათი დანიშნულების შესახებ დასკვნების გამოტანას. ამ ტექნიკის მიზანია, როგორც ზემოთ აღინიშნა, კლიენტების შესახებ რაც შეიძლება მეტი ინფორმაციის მიღება, მათ შორის კერძო ხასიათის (სქესი, ასაკი, პრეფერენციები და ა.შ.). ამ გზით გროვდება მონაცემები მაღაზიის მყიდველების, ასევე მათი ოჯახის წევრების, მათ შორის ბავშვების კონფიდენციალურობის შესახებ. ეს უკანასკნელი აკრძალულია მრავალი ქვეყნის კანონმდებლობით - არასრულწლოვანთა შესახებ ინფორმაციის შეგროვება იქ მხოლოდ მშობლების ნებართვით არის შესაძლებელი.
კვლევა აღნიშნავს, რომ არსებობს როგორც წარმატებული გადაწყვეტილებები მონაცემთა მოპოვების გამოყენებით, ასევე ცუდი გამოცდილება ამ ტექნოლოგიით. სფეროებს, სადაც მონაცემთა მოპოვების ტექნოლოგია ყველაზე მეტად წარმატებული იქნება, აქვს შემდეგი მახასიათებლები:
- მოითხოვოს ცოდნაზე დაფუძნებული გადაწყვეტილებები;
- აქვს ცვალებადი გარემო;
- ჰქონდეს ხელმისაწვდომი, საკმარისი და შინაარსიანი მონაცემები;
- უზრუნველყოს მაღალი დივიდენდები სწორი გადაწყვეტილებებისგან.
ანალიზის არსებული მიდგომები
დიდი ხნის განმავლობაში, მონაცემთა მოპოვების დისციპლინა არ იყო აღიარებული, როგორც მონაცემთა ანალიზის სრულფასოვანი დამოუკიდებელი სფერო, ზოგჯერ მას უწოდებენ "სტატისტიკის შემოგარენს" (Pregibon, 1997).
დღეისათვის დადგინდა მონაცემთა მოპოვების შესახებ რამდენიმე თვალსაზრისი. ერთ-ერთი მათგანის მომხრეები მას მირაჟად თვლიან, რაც ყურადღებას ამახვილებს კლასიკური ანალიზისგან.
რუსეთის ფედერაციის განათლებისა და მეცნიერების სამინისტრო
უმაღლესი პროფესიული განათლების ფედერალური სახელმწიფო საბიუჯეტო საგანმანათლებლო დაწესებულება
"ეროვნული კვლევითი ტომსკის პოლიტექნიკური უნივერსიტეტი"
კიბერნეტიკის ინსტიტუტი
მიმართულება ინფორმატიკა და კომპიუტერული ინჟინერია
დეპარტამენტი VT
ტესტი
დისციპლინაში ინფორმატიკა და კომპიუტერული ინჟინერია
თემა: მონაცემთა მოპოვების მეთოდები
შესავალი
Მონაცემების მოპოვება. ძირითადი ცნებები და განმარტებები
1 საფეხური მონაცემთა მოპოვების პროცესში
მაინინგის სისტემების 2 კომპონენტი
მონაცემთა მოპოვების 3 მეთოდები მონაცემთა მოპოვებაში
მონაცემთა მოპოვების მეთოდები
1 ასოციაციის წესების გამოყვანა
2 ნერვული ქსელის ალგორითმები
3 უახლოესი მეზობელი და k-უახლოესი მეზობლის მეთოდები
4 გადაწყვეტილების ხეები
5 კლასტერიზაციის ალგორითმები
6 გენეტიკური ალგორითმები
აპლიკაციები
მონაცემთა მოპოვების ხელსაწყოების მწარმოებლები
მეთოდების კრიტიკა
დასკვნა
ბიბლიოგრაფია
შესავალი
საინფორმაციო ტექნოლოგიების განვითარების შედეგია ელექტრონული ფორმით დაგროვილი მონაცემთა კოლოსალური რაოდენობა, რომელიც სწრაფი ტემპით იზრდება. უფრო მეტიც, მონაცემებს, როგორც წესი, აქვთ ჰეტეროგენული სტრუქტურა (ტექსტები, სურათები, აუდიო, ვიდეო, ჰიპერტექსტური დოკუმენტები, რელაციური მონაცემთა ბაზები). დიდი ხნის განმავლობაში დაგროვილი მონაცემები შეიძლება შეიცავდეს შაბლონებს, ტენდენციებს და ურთიერთობებს, რომლებიც ღირებული ინფორმაციაა დაგეგმვის, პროგნოზირების, გადაწყვეტილების მიღებისა და პროცესის კონტროლში. თუმცა, ადამიანს ფიზიკურად არ შეუძლია ეფექტურად გააანალიზოს ასეთი მოცულობის ჰეტეროგენული მონაცემები. ტრადიციული მათემატიკური სტატისტიკის მეთოდები დიდი ხანია აცხადებდა, რომ იყო ძირითადი ინსტრუმენტი მონაცემთა ანალიზისთვის. თუმცა, ისინი არ იძლევიან ახალი ჰიპოთეზების სინთეზის საშუალებას, მაგრამ მათი გამოყენება შესაძლებელია მხოლოდ ადრე ჩამოყალიბებული ჰიპოთეზებისა და „უხეში“ საძიებო ანალიზის დასადასტურებლად, რაც საფუძველს უქმნის ონლაინ ანალიტიკურ დამუშავებას (OLAP). ხშირად, ეს არის ჰიპოთეზის ფორმულირება, რომელიც აღმოჩნდება ყველაზე რთული ამოცანა შემდგომი გადაწყვეტილების მისაღებად ანალიზის ჩატარებისას, რადგან მონაცემების ყველა ნიმუში ერთი შეხედვით აშკარა არ არის. აქედან გამომდინარე, მონაცემთა მოპოვების ტექნოლოგიები განიხილება, როგორც ერთ-ერთი ყველაზე მნიშვნელოვანი და პერსპექტიული თემა ინფორმაციული ტექნოლოგიების ინდუსტრიაში კვლევისა და გამოყენებისთვის. ამ შემთხვევაში მონაცემთა მოპოვება გულისხმობს ახალი, სწორი და პოტენციურად სასარგებლო ცოდნის განსაზღვრის პროცესს, რომელიც ეფუძნება დიდი რაოდენობით მონაცემებს. ამრიგად, MIT Technology Review-მა აღწერა მონაცემთა მოპოვება, როგორც ერთ-ერთი ათი განვითარებადი ტექნოლოგიადან, რომელიც შეცვლის სამყაროს.
1. მონაცემთა მოპოვება. ძირითადი ცნებები და განმარტებები
მონაცემთა მოპოვება არის ცოდნის მანამდე უცნობი, არატრივიალური, პრაქტიკულად სასარგებლო და ხელმისაწვდომი ინტერპრეტაციის გამოვლენის პროცესი „ნედლეულ“ მონაცემებში, რაც აუცილებელია ადამიანის საქმიანობის სხვადასხვა სფეროში გადაწყვეტილების მისაღებად.
მონაცემთა მოპოვების ტექნოლოგიის არსი და მიზანი შეიძლება ჩამოყალიბდეს შემდეგნაირად: ეს არის ტექნოლოგია, რომელიც შექმნილია დიდი რაოდენობით მონაცემების მოსაძიებლად არა აშკარა, ობიექტური და პრაქტიკაში გამოსადეგი შაბლონებისთვის.
არაცხადი შაბლონები არის შაბლონები, რომელთა აღმოჩენა შეუძლებელია ინფორმაციის დამუშავების სტანდარტული მეთოდებით ან ექსპერტების რჩევით.
ობიექტური კანონზომიერებები უნდა გავიგოთ, როგორც კანონზომიერებები, რომლებიც სრულად შეესაბამება რეალობას, განსხვავებით ექსპერტის მოსაზრებისგან, რომელიც ყოველთვის სუბიექტურია.
მონაცემთა ანალიზის ეს კონცეფცია ვარაუდობს, რომ:
§ მონაცემები შეიძლება იყოს არაზუსტი, არასრული (შეიცავს ხარვეზებს), წინააღმდეგობრივი, ჰეტეროგენული, არაპირდაპირი და ამავე დროს ჰქონდეს გიგანტური მოცულობები; შესაბამისად, მონაცემების გაგება კონკრეტულ აპლიკაციებში მოითხოვს მნიშვნელოვან ინტელექტუალურ ძალისხმევას;
§ თავად მონაცემთა ანალიზის ალგორითმებს შეიძლება ჰქონდეთ „ინტელექტის ელემენტები“, კერძოდ, პრეცედენტების სწავლის, ანუ კერძო დაკვირვების საფუძველზე ზოგადი დასკვნების გამოტანის უნარი; ასეთი ალგორითმების შემუშავება ასევე მოითხოვს მნიშვნელოვან ინტელექტუალურ ძალისხმევას;
§ ნედლი მონაცემების ინფორმაციად და ინფორმაციის ცოდნად გადამუშავების პროცესები არ შეიძლება განხორციელდეს ხელით და მოითხოვს ავტომატიზაციას.
მონაცემთა მოპოვების ტექნოლოგია ეფუძნება შაბლონების (ნიმუშების) კონცეფციას, რომლებიც ასახავს მონაცემებში მრავალგანზომილებიანი ურთიერთობების ფრაგმენტებს. ეს შაბლონები წარმოადგენს მონაცემთა ქვენიმუშებში თანდაყოლილ შაბლონებს, რომლებიც შეიძლება კომპაქტურად იყოს გამოხატული ადამიანისთვის წასაკითხად.
შაბლონების ძიება ხორციელდება მეთოდებით, რომლებიც არ შემოიფარგლება ნიმუშის სტრუქტურის შესახებ აპრიორული ვარაუდების ჩარჩოებით და გაანალიზებული ინდიკატორების მნიშვნელობების განაწილების ტიპზე.
მონაცემთა მოპოვების მნიშვნელოვანი მახასიათებელია მოძიებული შაბლონების არასტანდარტული და არააშკარაობა. სხვა სიტყვებით რომ ვთქვათ, მონაცემთა მოპოვების ინსტრუმენტები განსხვავდება სტატისტიკური მონაცემების დამუშავების ინსტრუმენტებისგან და OLAP ინსტრუმენტებისგან იმით, რომ იმის ნაცვლად, რომ შეამოწმონ წინასწარ მიღებული ურთიერთდამოკიდებულებები, მათ შეუძლიათ დამოუკიდებლად იპოვონ ასეთი ურთიერთდამოკიდებულებები არსებული მონაცემების საფუძველზე და შექმნან ჰიპოთეზა მათი ბუნების შესახებ. . არსებობს ხუთი სტანდარტული ტიპის შაბლონები, რომლებიც იდენტიფიცირებულია მონაცემთა მოპოვების მეთოდებით:
· ასოციაცია - მოვლენების ერთმანეთთან დაკავშირების მაღალი ალბათობა. ასოციაციის მაგალითია მაღაზიაში არსებული ნივთები, რომლებსაც ხშირად ერთად ყიდულობენ;
· თანმიმდევრობა - დროში დაკავშირებული მოვლენების ჯაჭვის მაღალი ალბათობა. თანმიმდევრობის მაგალითია სიტუაცია, როდესაც ერთი პროდუქტის შეძენის შემდეგ გარკვეული პერიოდის განმავლობაში მეორე შეძენილი იქნება მაღალი ალბათობით;
· კლასიფიკაცია - არის ნიშნები, რომლებიც ახასიათებს ჯგუფს, რომელსაც მიეკუთვნება ესა თუ ის მოვლენა ან ობიექტი;
· კლასტერირება - კლასიფიკაციის მსგავსი ნიმუში და მისგან განსხვავებული იმით, რომ თავად ჯგუფები არ არის მითითებული - ისინი ავტომატურად ვლინდება მონაცემთა დამუშავებისას;
· დროებითი შაბლონები - შაბლონების არსებობა გარკვეული მონაცემების ქცევის დინამიკაში. დროებითი ნიმუშის ტიპიური მაგალითია გარკვეულ საქონელზე ან მომსახურებაზე მოთხოვნის სეზონური რყევები.
1.1 ნაბიჯები მონაცემთა მოპოვების პროცესში
ტრადიციულად, მონაცემთა მოპოვების პროცესში გამოიყოფა შემდეგი ეტაპები:
1. საგნობრივი არეალის შესწავლა, რის შედეგადაც ყალიბდება ანალიზის ძირითადი მიზნები.
2. მონაცემთა შეგროვება.
მონაცემთა წინასწარი დამუშავება:
ა. მონაცემთა გაწმენდა - ორიგინალური მონაცემებიდან შეუსაბამობების და შემთხვევითი "ხმაურის" აღმოფხვრა
ბ. მონაცემთა ინტეგრაცია არის მონაცემთა გაერთიანება მრავალი შესაძლო წყაროდან ერთ საცავში. მონაცემთა ტრანსფორმაცია. ამ ეტაპზე მონაცემები გარდაიქმნება ანალიზისთვის შესაფერის ფორმაში. ჩვეულებრივ გამოიყენება მონაცემთა აგრეგაცია, ატრიბუტების შერჩევა, მონაცემთა შეკუმშვა და განზომილების შემცირება.
4. მონაცემთა ანალიზი. ამ ეტაპზე, მაინინგის ალგორითმები გამოიყენება შაბლონების ამოსაღებად.
5. ნაპოვნი ნიმუშების ინტერპრეტაცია. ეს ნაბიჯი შეიძლება მოიცავდეს მოპოვებული შაბლონების ვიზუალიზაციას, მართლაც სასარგებლო შაბლონების იდენტიფიცირებას ზოგიერთი სასარგებლო ფუნქციის საფუძველზე.
ახალი ცოდნის გამოყენება.
1.2 მაინინგ სისტემების კომპონენტები
როგორც წესი, მონაცემთა მოპოვების სისტემებს აქვთ შემდეგი ძირითადი კომპონენტები:
1. მონაცემთა ბაზა, მონაცემთა საწყობი ან სხვა ინფორმაციის საცავი. ეს შეიძლება იყოს ერთი ან მეტი მონაცემთა ბაზა, მონაცემთა საწყობი, ცხრილები, სხვა სახის საცავი, რომელთა გასუფთავება და ინტეგრირება შესაძლებელია.
2. მონაცემთა ბაზის სერვერი ან მონაცემთა საწყობი. მითითებული სერვერი პასუხისმგებელია მომხმარებლის მოთხოვნის საფუძველზე არსებითი მონაცემების ამოღებაზე.
Ცოდნის ბაზა. ეს არის დომენის ცოდნა, რომელიც მიუთითებს, თუ როგორ უნდა მოძებნოთ და შეაფასოთ მიღებული შაბლონების სარგებლიანობა.
ცოდნის მოპოვების სერვისი. ეს არის მონაცემთა მოპოვების სისტემის განუყოფელი ნაწილი და შეიცავს ფუნქციური მოდულების ერთობლიობას ამოცანებისთვის, როგორიცაა დახასიათება, ასოციაციების პოვნა, კლასიფიკაცია, კლასტერული ანალიზი და დისპერსიული ანალიზი.
ნიმუშის შეფასების მოდული. ეს კომპონენტი ითვლის შაბლონების ინტერესის ან სარგებლობის ზომებს.
Მომხმარებლის გრაფიკული ინტერფეისი. ეს მოდული პასუხისმგებელია მომხმარებლისა და მონაცემთა მოპოვების სისტემას შორის კომუნიკაციაზე, შაბლონების ვიზუალიზაციაზე სხვადასხვა ფორმით.
1.3 მონაცემთა მოპოვების მეთოდები მონაცემთა მოპოვებაში
მონაცემთა მოპოვების ტექნოლოგიაში გამოყენებული ანალიტიკური მეთოდების უმეტესობა არის ცნობილი მათემატიკური ალგორითმები და მეთოდები. მათ განაცხადში ახალია მათი გამოყენების შესაძლებლობა გარკვეული კონკრეტული პრობლემების გადაჭრაში, ტექნიკის და პროგრამული უზრუნველყოფის შესაძლებლობების გამო. უნდა აღინიშნოს, რომ მონაცემთა მოპოვების მეთოდების უმეტესობა შემუშავდა ხელოვნური ინტელექტის თეორიის ფარგლებში. განვიხილოთ ყველაზე გავრცელებული მეთოდები:
ასოციაციის წესების დასკვნა.
2. ნერვული ქსელის ალგორითმები, რომელთა იდეა ემყარება ნერვული ქსოვილის ფუნქციონირების ანალოგიას და მდგომარეობს იმაში, რომ საწყისი პარამეტრები განიხილება როგორც სიგნალები, რომლებიც გარდაიქმნება "ნეირონებს" შორის არსებული კავშირების შესაბამისად. ხოლო მთლიანი ქსელის პასუხი განიხილება, როგორც ორიგინალური მონაცემების ანალიზის შედეგად მიღებული პასუხი.
საწყისი მონაცემების ახლო ანალოგის შერჩევა არსებული ისტორიული მონაცემებიდან. ასევე უწოდებენ "უახლოესი მეზობლის" მეთოდს.
გადაწყვეტილების ხეები არის იერარქიული სტრუქტურა, რომელიც დაფუძნებულია კითხვების ერთობლიობაზე, რომელიც მოითხოვს "დიახ" ან "არა" პასუხს.
კლასტერული მოდელები გამოიყენება მსგავსი მოვლენების ჯგუფებად დასაჯგუფებლად, მონაცემთა ნაკრების რამდენიმე ველის მსგავსი მნიშვნელობების საფუძველზე.
შემდეგ თავში უფრო დეტალურად განვიხილავთ ზემოთ მოცემულ მეთოდებს.
2. მონაცემთა მოპოვების მეთოდები
2.1 ასოციაციის წესების დასკვნა
ასოციაციის წესები არის "თუ ... მაშინ ..." ფორმის წესები. მონაცემთა ნაკრებში ასეთი წესების ძიება ავლენს დამალულ ურთიერთობებს ერთი შეხედვით დაუკავშირებელ მონაცემებში. ასოციაციის წესების ძიების ერთ-ერთი ყველაზე ხშირად მოყვანილი მაგალითია კალათაში სტაბილური ურთიერთობების პოვნის პრობლემა. გამოწვევა მდგომარეობს იმაში, რომ დადგინდეს, რომელ საქონელს ყიდულობენ მომხმარებლები ერთად, რათა მარკეტოლოგებმა სწორად განათავსონ ეს ნივთები მაღაზიაში გაყიდვების გაზრდის მიზნით.
ასოციაციის წესები განისაზღვრება, როგორც ფორმის დებულებები (X1, X2, ..., Xn) -> Y, სადაც ვარაუდობენ, რომ Y შეიძლება იყოს ტრანზაქციაში, იმ პირობით, რომ არსებობს X1, X2, ..., Xn. იმავე გარიგებაში. უნდა აღინიშნოს, რომ სიტყვა „შეიძლება“ გულისხმობს, რომ წესი არ არის იდენტობა, არამედ მოქმედებს მხოლოდ გარკვეული ალბათობით. გარდა ამისა, Y შეიძლება იყოს ნივთების ნაკრები და არა მხოლოდ ერთი ელემენტი. Y-ის პოვნის ალბათობას გარიგებაში, რომელშიც არის ელემენტები X1, X2,…, Xn, ეწოდება ნდობა. ტრანზაქციების პროცენტს, რომელიც შეიცავს ტრანზაქციების მთლიანი რაოდენობის წესს, ეწოდება მხარდაჭერა. ნდობის დონეს, რომელსაც წესი უნდა აღემატებოდეს, საინტერესოობა ეწოდება.
არსებობს სხვადასხვა სახის ასოციაციის წესები. მათი უმარტივესი ფორმით, ასოციაციის წესები მხოლოდ ასოციაციის არსებობას ან არარსებობას აცნობებს. ასეთ წესებს ლოგიკური ასოციაციის წესს უწოდებენ. ასეთი წესის მაგალითი იქნება: „მომხმარებლები, რომლებიც იოგურტს ყიდულობენ, უცხიმო კარაქსაც ყიდულობენ“.
წესებს, რომლებიც აერთიანებს რამდენიმე ასოციაციის წესს, ეწოდება მრავალდონიანი ან გენერალიზებული ასოციაციის წესები. ასეთი წესების აგებისას ნივთები, როგორც წესი, ჯგუფდება იერარქიის მიხედვით და ჩხრეკა ტარდება უმაღლეს კონცეპტუალურ დონეზე. მაგალითად, „მომხმარებლები, რომლებიც რძეს ყიდულობენ, პურსაც ყიდულობენ“. ამ მაგალითში რძე და პური შეიცავს სხვადასხვა ტიპისა და ბრენდის იერარქიას, მაგრამ ქვედა დონეზე ძიება ვერ იპოვის საინტერესო წესებს.
წესების უფრო რთული ტიპია რაოდენობრივი ასოციაციის წესები. ამ ტიპის წესი იძებნება რაოდენობრივი (მაგალითად, ფასი) ან კატეგორიული (მაგალითად, სქესი) ატრიბუტების გამოყენებით და განისაზღვრება როგორც (
ზემოაღნიშნული წესების ტიპები არ ეხება იმ ფაქტს, რომ ტრანზაქციები, თავისი ბუნებით, დროზეა დამოკიდებული. მაგალითად, პროდუქტის გაყიდვამდე ან ბაზრიდან გაქრობის შემდეგ ძიება უარყოფითად იმოქმედებს მხარდაჭერის ზღურბლზე. ამის გათვალისწინებით, დაინერგა ატრიბუტის სიცოცხლის ხანგრძლივობა დროებითი ასოციაციის წესების საძიებო ალგორითმებში.
ასოციაციის წესების პოვნის პრობლემა ზოგადად შეიძლება დაიყოს ორ ნაწილად: ელემენტების ხშირად წარმოქმნილი ნაკრების ძიება და ხშირად ნაპოვნი სიმრავლეების საფუძველზე წესების გენერირება. უმეტესწილად, წინა კვლევები მიჰყვა ამ მიმართულებებს და გააფართოვა ისინი სხვადასხვა მიმართულებით.
Apriori ალგორითმის გამოჩენის შემდეგ, ეს ალგორითმი ყველაზე ხშირად გამოიყენება პირველ ეტაპზე. მრავალი გაუმჯობესება, მაგალითად, სიჩქარესა და მასშტაბურობაში, მიზნად ისახავს აპრიორის ალგორითმის გაუმჯობესებას, მისი მცდარი თვისების გამოსწორებას ელემენტების ყველაზე გავრცელებული ნაკრებისთვის ძალიან ბევრი კანდიდატის გენერირების შესახებ. Apriori აგენერირებს ერთეულების ნაკრებებს მხოლოდ წინა საფეხურზე ნაპოვნი დიდი ერთეულების გამოყენებით, ტრანზაქციების ხელახალი შემოწმების გარეშე. შეცვლილი AprioriTid ალგორითმი აუმჯობესებს Apriori-ს მხოლოდ მონაცემთა ბაზის გამოყენებით პირველ უღელტეხილზე. შემდგომი ნაბიჯების გამოთვლები მხოლოდ პირველ უღელტეხილში გამომუშავებულ მონაცემებს იყენებს, რაც გაცილებით მცირეა, ვიდრე თავდაპირველი მონაცემთა ბაზა. ეს იწვევს პროდუქტიულობის უზარმაზარ ზრდას. ალგორითმის შემდგომი გაუმჯობესებული ვერსია, სახელწოდებით AprioriHybrid, შეგიძლიათ მიიღოთ Apriori-ის გამოყენებით პირველ რამდენიმე გადასასვლელზე, შემდეგ კი, მოგვიანებით გადასვლებზე, როდესაც kth კანდიდატის კომპლექტები უკვე მთლიანად იქნება განაწილებული კომპიუტერის მეხსიერებაში, გადადით AprioriTid-ზე.
Apriori ალგორითმის გაუმჯობესების შემდგომი ძალისხმევა დაკავშირებულია ალგორითმის პარალელიზებასთან (Count Distribution, Data Distribution, Candidate Distribution და ა.შ.), მის მასშტაბირებასთან (ინტელექტუალური მონაცემთა განაწილება, ჰიბრიდული განაწილება), მონაცემთა ახალი სტრუქტურების დანერგვასთან, როგორიცაა ხეები. ხშირად წარმოქმნილი ელემენტების (FP-growth ).
მეორე ნაბიჯი ძირითადად ავთენტური და საინტერესოა. ახალი მოდიფიკაციები ამატებს ზემოთ აღწერილ განზომილებას, ხარისხს და დროებით მხარდაჭერას ტრადიციულ ლოგიკურ წესებს. წესების მოსაძებნად ხშირად გამოიყენება ევოლუციური ალგორითმი.
2.2 ნერვული ქსელის ალგორითმები
ხელოვნური ნერვული ქსელები გაჩნდა მათემატიკური აპარატის გამოყენების შედეგად ადამიანის ნერვული სისტემის ფუნქციონირების შესასწავლად მისი რეპროდუცირების მიზნით. კერძოდ: ნერვული სისტემის უნარი ისწავლოს და გამოასწოროს შეცდომები, რამაც შესაძლებელი უნდა გახადოს ადამიანის ტვინის მუშაობის სიმულაცია, თუმცა საკმაოდ უხეშად. ნერვული ქსელის მთავარი სტრუქტურული და ფუნქციური ნაწილია ფორმალური ნეირონი, რომელიც ნაჩვენებია ნახ. 1, სადაც x0, x1, ..., xn არის შეყვანის სიგნალების ვექტორის კომპონენტები, w0, w1, ..., wn არის ნეირონის შეყვანის სიგნალების წონის მნიშვნელობები, ხოლო y არის ნეირონის გამომავალი სიგნალი.
ბრინჯი. 1. ფორმალური ნეირონი: სინაფსები (1), შემკრები (2), გადამყვანი (3).
ფორმალური ნეირონი შედგება 3 ტიპის ელემენტისგან: სინაფსები, შემკრები და გადამყვანი. სინაფსი ახასიათებს ორ ნეირონს შორის კავშირის სიძლიერეს.
შემკრები ამატებს შეყვანის სიგნალებს წინასწარ გამრავლებულ შესაბამის წონებზე. გადამყვანი ახორციელებს ერთი არგუმენტის ფუნქციას - დამამატებლის გამომავალი. ამ ფუნქციას ეწოდება აქტივაციის ფუნქცია ან ნეირონის გადაცემის ფუნქცია.
ზემოთ აღწერილი ფორმალური ნეირონები შეიძლება გაერთიანდეს ისე, რომ ზოგიერთი ნეირონის გამომავალი სიგნალები შევიდეს სხვებში. შედეგად მიღებული ურთიერთდაკავშირებული ნეირონების ნაკრები ეწოდება ხელოვნურ ნერვულ ქსელებს (ANNs), ან, მოკლედ, ნეირონულ ქსელებს.
არსებობს ნეირონების სამი ზოგადი ტიპი, რაც დამოკიდებულია ნერვულ ქსელში მათი პოზიციიდან:
შეყვანის ნეირონები, რომლებიც იღებენ შეყვანის სიგნალებს. ასეთ ნეირონებს, ნეირონებს, როგორც წესი, აქვთ ერთი შეყვანა ერთეული წონით, არ არის მიკერძოებული და ნეირონის გამომავალი მნიშვნელობა უდრის შეყვანის სიგნალს;
გამომავალი ნეირონები (გამომავალი კვანძები), რომელთა გამომავალი მნიშვნელობები წარმოადგენს ნერვული ქსელის გამომავალ სიგნალებს;
ფარული ნეირონები, რომლებსაც არ აქვთ პირდაპირი კავშირი შეყვანის სიგნალებთან, ხოლო ფარული ნეირონების გამომავალი სიგნალების მნიშვნელობები არ არის ANN-ის გამომავალი სიგნალები.
ინტერნეირონული კავშირების სტრუქტურის მიხედვით, ANN-ის ორი კლასი გამოირჩევა:
პირდაპირი გავრცელების ANN-ები, რომლებშიც სიგნალი ვრცელდება მხოლოდ შეყვანის ნეირონებიდან გამომავალ ნეირონებამდე.
განმეორებადი ANN - ANN გამოხმაურებით. ასეთ ANN-ებში სიგნალები შეიძლება გადაიცეს ნებისმიერ ნეირონს შორის, მიუხედავად მათი მდებარეობისა ANN-ში.
ANN-ის სწავლების ორი ზოგადი მიდგომა არსებობს:
სწავლა მასწავლებელთან ერთად.
სწავლა მასწავლებლის გარეშე.
ზედამხედველობითი სწავლება გულისხმობს სწავლების მაგალითების წინასწარ განსაზღვრული ნაკრების გამოყენებას. თითოეული მაგალითი შეიცავს შეყვანის სიგნალების ვექტორს და საცნობარო გამომავალი სიგნალების შესაბამის ვექტორს, რომლებიც დამოკიდებულია სამუშაოზე. ამ კომპლექტს ეწოდება სავარჯიშო ნაკრები ან სასწავლო ნაკრები. ნერვული ქსელის ვარჯიში მიზნად ისახავს ANN კავშირების წონის ისეთ ცვლილებას, რომელშიც ANN გამომავალი სიგნალების მნიშვნელობა რაც შეიძლება ნაკლებად განსხვავდება გამომავალი სიგნალების საჭირო მნიშვნელობებისგან შეყვანის მოცემული ვექტორისთვის. სიგნალები.
უკონტროლო სწავლისას, კავშირების წონა რეგულირდება ან ნეირონებს შორის კონკურენციის შედეგად, ან ნეირონების გამომავალი სიგნალების კორელაციის გათვალისწინებით, რომელთა შორის არის კავშირი. უკონტროლო სწავლების შემთხვევაში სასწავლო ნიმუში არ გამოიყენება.
ნერვული ქსელები გამოიყენება ამოცანების ფართო სპექტრის გადასაჭრელად, როგორიცაა კოსმოსური შატლების დატვირთვის დაგეგმვა და გაცვლითი კურსის პროგნოზირება. თუმცა, ისინი ხშირად არ გამოიყენება მონაცემთა მოპოვების სისტემებში მოდელის სირთულის გამო (ცოდნა, რომელიც ჩაწერილია, როგორც რამდენიმე ასეული შიდა კავშირის წონა, სრულიად სცილდება ადამიანების ანალიზსა და ინტერპრეტაციას) და ვარჯიშის დიდ დროს. მეორე მხრივ, ნერვულ ქსელებს აქვთ ისეთი უპირატესობები მონაცემთა ანალიზის ამოცანების გამოსაყენებლად, როგორიცაა ხმაურიანი მონაცემების წინააღმდეგობა და მაღალი სიზუსტე.
2.3 უახლოესი მეზობელი და k- უახლოესი მეზობლის მეთოდები
უახლოესი მეზობელი ალგორითმი და k-უახლოესი მეზობელი ალგორითმი (KNN) დაფუძნებულია მახასიათებლების მსგავსებაზე. უახლოესი მეზობელი ალგორითმი ირჩევს ობიექტს ყველა ცნობილ ობიექტს შორის, რომელიც მაქსიმალურად ახლოსაა (ობიექტებს შორის მანძილის მეტრიკის გამოყენებით, მაგალითად, ევკლიდური) ახალ ადრე უცნობ ობიექტს. უახლოესი მეზობლის მეთოდის მთავარი პრობლემა არის მისი მგრძნობელობა საწვრთნელ მონაცემებში გამოკვეთილების მიმართ.
აღწერილი პრობლემის თავიდან აცილება შესაძლებელია KNN ალგორითმით, რომელიც ყველა დაკვირვებას შორის განასხვავებს უკვე k- უახლოეს მეზობლებს ახალი ობიექტის მსგავსი. უახლოესი მეზობლების კლასებიდან გამომდინარე, გადაწყვეტილება მიიღება ახალ ობიექტთან დაკავშირებით. ამ ალგორითმის მნიშვნელოვანი ამოცანაა შეარჩიოს კოეფიციენტი k - ჩანაწერების რაოდენობა, რომლებიც ჩაითვლება მსგავსი. ალგორითმის მოდიფიკაცია, რომელშიც მეზობლის წვლილი პროპორციულია ახალ ობიექტამდე მანძილის (k-წონიანი უახლოესი მეზობლების მეთოდი) საშუალებას იძლევა მივაღწიოთ უფრო დიდი კლასიფიკაციის სიზუსტეს. k უახლოესი მეზობლების მეთოდი ასევე გვაძლევს საშუალებას შევაფასოთ პროგნოზის სიზუსტე. მაგალითად, ყველა k უახლოეს მეზობელს აქვს ერთი და იგივე კლასი, მაშინ ალბათობა იმისა, რომ შემოწმებულ ობიექტს ექნება იგივე კლასი, ძალიან დიდია.
ალგორითმის მახასიათებლებს შორის უნდა აღინიშნოს ანომალიური გამოხტომების წინააღმდეგობა, რადგან ასეთი ჩანაწერის ალბათობა k- უახლოეს მეზობლების რიცხვში მოხვდება მცირეა. თუ ეს მოხდა, მაშინ გავლენა ხმის მიცემაზე (განსაკუთრებით შეწონილი) (k> 2-ისთვის) ასევე სავარაუდოდ უმნიშვნელო იქნება და, შესაბამისად, გავლენა კლასიფიკაციის შედეგზე ასევე მცირე იქნება. ასევე, უპირატესობებია მარტივი განხორციელება, ალგორითმის შედეგის ინტერპრეტაციის სიმარტივე, ალგორითმის მოდიფიცირების შესაძლებლობა ყველაზე შესაფერისი კომბინირებული ფუნქციებისა და მეტრიკის გამოყენებით, რაც საშუალებას გაძლევთ დაარეგულიროთ ალგორითმი კონკრეტული ამოცანისთვის. KNN ალგორითმს ასევე აქვს მთელი რიგი უარყოფითი მხარეები. პირველ რიგში, ალგორითმისთვის გამოყენებული მონაცემთა ნაკრები უნდა იყოს წარმომადგენლობითი. მეორე, მოდელი არ შეიძლება იყოს გამოყოფილი მონაცემებისგან: ყველა მაგალითი უნდა იყოს გამოყენებული ახალი მაგალითის კლასიფიკაციისთვის. ეს ფუნქცია მკვეთრად ზღუდავს ალგორითმის გამოყენებას.
2.4 გადაწყვეტილების ხეები
ტერმინში „გადაწყვეტილების ხეები“ იგულისხმება ალგორითმების ოჯახი, რომელიც დაფუძნებულია კლასიფიკაციის წესების იერარქიულ, თანმიმდევრულ სტრუქტურაში წარმოდგენაზე. ეს არის ალგორითმების ყველაზე პოპულარული კლასი მონაცემთა მოპოვების პრობლემების გადასაჭრელად.
გადაწყვეტილების ხეების ასაგებად ალგორითმების ოჯახი შესაძლებელს ხდის მოცემული შემთხვევისთვის პარამეტრის მნიშვნელობის პროგნოზირებას სხვა მსგავსი შემთხვევების დიდი რაოდენობით მონაცემების საფუძველზე. ჩვეულებრივ, ამ ოჯახის ალგორითმები გამოიყენება პრობლემების გადასაჭრელად, რაც საშუალებას იძლევა დაყოს ყველა წყაროს მონაცემები რამდენიმე დისკრეტულ ჯგუფად.
როდესაც გადაწყვეტილების ხეების აგების ალგორითმები გამოიყენება შეყვანის მონაცემების კომპლექტზე, შედეგი ნაჩვენებია ხის სახით. ასეთი ალგორითმები იძლევა ასეთი დაყოფის რამდენიმე დონეს, შედეგად მიღებული ჯგუფების (ხის ტოტები) დაყოფას სხვა მახასიათებლებზე დაყრდნობით. დაყოფა გრძელდება მანამ, სანამ სავარაუდო მნიშვნელობები არ გახდება იგივე (ან, პროგნოზირებული პარამეტრის უწყვეტი მნიშვნელობის შემთხვევაში, დაიხურება) ყველა მიღებული ჯგუფისთვის (ხის ფოთლები). ეს არის ეს მნიშვნელობები, რომლებიც გამოიყენება ამ მოდელის საფუძველზე პროგნოზების გასაკეთებლად.
გადაწყვეტილების ხეების აგების ალგორითმების მოქმედება ეფუძნება რეგრესიისა და კორელაციური ანალიზის მეთოდებს. ამ ოჯახში ერთ-ერთი ყველაზე პოპულარული ალგორითმია CART (კლასიფიკაციის და რეგრესიის ხეები), რომელიც დაფუძნებულია ხის ტოტში მონაცემების ორ შვილად ტოტად დაყოფაზე; ამ შემთხვევაში, ამა თუ იმ ფილიალის შემდგომი დაყოფა დამოკიდებულია იმაზე, თუ რამდენი საწყისი მონაცემია აღწერილი ამ ფილიალის მიერ. რამდენიმე სხვა მსგავსი ალგორითმი საშუალებას გაძლევთ გაყოთ ფილიალი უფრო მეტ შვილად ტოტებად. ამ შემთხვევაში, დაყოფა ხდება ყველაზე მაღალი კორელაციის კოეფიციენტის საფუძველზე მონაცემების აღწერილი ფილიალისთვის პარამეტრს შორის, რომლის მიხედვითაც ხდება გაყოფა და პარამეტრს, რომელიც უნდა იყოს პროგნოზირებული მომავალში.
მიდგომის პოპულარობა დაკავშირებულია სიცხადესთან და სიცხადესთან. მაგრამ გადაწყვეტილების ხეები ფუნდამენტურად ვერ პოულობენ "საუკეთესო" (ყველაზე სრულყოფილი და ზუსტი) წესების მონაცემებში. ისინი ახორციელებენ მახასიათებლების თანმიმდევრული ნახვის გულუბრყვილო პრინციპს და რეალურად პოულობენ რეალური შაბლონების ნაწილებს, ქმნიან მხოლოდ ლოგიკური დასკვნის ილუზიას.
2.5 დაჯგუფების ალგორითმები
კლასტერირება არის ობიექტების კომპლექტის დაშლა ჯგუფებად, რომელსაც ეწოდება კლასტერები. კლასტერიზაციასა და კლასიფიკაციას შორის მთავარი განსხვავება ისაა, რომ ჯგუფების სია მკაფიოდ არ არის განსაზღვრული და განისაზღვრება ალგორითმის მუშაობის დროს.
ზოგადად კლასტერული ანალიზის გამოყენება მცირდება შემდეგ ეტაპებზე:
· ობიექტების ნიმუშის შერჩევა დაჯგუფებისთვის;
· ცვლადების ნაკრების განსაზღვრა, რომლითაც შეფასდება ნიმუშში არსებული ობიექტები. საჭიროების შემთხვევაში, ცვლადების მნიშვნელობების ნორმალიზება;
· ობიექტებს შორის მსგავსების საზომის მნიშვნელობების გამოთვლა;
· კლასტერული ანალიზის მეთოდის გამოყენება მსგავსი ობიექტების (კლასტერების) ჯგუფების შესაქმნელად;
· ანალიზის შედეგების პრეზენტაცია.
შედეგების მიღებისა და ანალიზის შემდეგ შესაძლებელია შერჩეული მეტრიკული და კლასტერული მეთოდის კორექტირება ოპტიმალური შედეგის მიღებამდე.
კლასტერიზაციის ალგორითმებს შორის გამოიყოფა იერარქიული და ბრტყელი ჯგუფები. იერარქიული ალგორითმები (ასევე უწოდებენ ტაქსონომიის ალგორითმებს) ქმნიან ნიმუშის არა ერთ ნაწილს დისჯონტურ კლასტერებად, არამედ წყობილი დანაყოფების სისტემას. ამრიგად, ალგორითმის გამომავალი არის მტევნის ხე, რომლის ფესვი არის მთელი ნიმუში, ხოლო ფოთლები ყველაზე პატარა მტევნებია. ბრტყელი ალგორითმები ქმნიან ობიექტების ერთ დანაყოფს განცალკევებულ კლასტერებად.
კლასტერიზაციის ალგორითმების კიდევ ერთი კლასიფიკაცია არის მკაფიო და ბუნდოვანი ალგორითმები. წმინდა (ან გადახურვის გარეშე) ალგორითმები თითოეულ სანიმუშო ობიექტს ანიჭებენ კლასტერულ ნომერს, ანუ თითოეული ობიექტი ეკუთვნის მხოლოდ ერთ კლასტერს. ბუნდოვანი (ან გადახურვის) ალგორითმები თითოეულ ობიექტს უკავშირებენ რეალური მნიშვნელობების ერთობლიობას, რომელიც აჩვენებს ობიექტის კლასტერებთან მიმართების ხარისხს. ამრიგად, თითოეული ობიექტი მიეკუთვნება თითოეულ კლასტერს გარკვეული ალბათობით.
იერარქიულ კლასტერიზაციის ალგორითმებს შორის არის ორი ძირითადი ტიპი: ქვემოდან ზევით და ზემოდან ქვევით ალგორითმები. ზემოდან ქვევით ალგორითმები მუშაობს ზემოდან ქვევით პრინციპით: პირველ რიგში, ყველა ობიექტი მოთავსებულია ერთ კლასტერში, რომელიც შემდეგ იყოფა უფრო და უფრო პატარა კლასტერებად. უფრო გავრცელებულია ქვემოდან ზემოთ ალგორითმები, რომლებიც სამუშაოს დასაწყისში ათავსებენ თითოეულ ობიექტს ცალკე კლასტერში და შემდეგ აერთიანებენ კლასტერებს უფრო და უფრო დიდებად, სანამ ნიმუშის ყველა ობიექტი ერთ კლასტერში მოხვდება. ამრიგად, აგებულია წყობილი დანაყოფების სისტემა. ასეთი ალგორითმების შედეგები ჩვეულებრივ წარმოდგენილია ხის სახით.
იერარქიული ალგორითმების მინუსი არის სრული დანაყოფების სისტემა, რომელიც შეიძლება ზედმეტი იყოს მოგვარებული პრობლემის კონტექსტში.
ახლა განიხილეთ ბრტყელი ალგორითმები. ამ კლასს შორის უმარტივესი არის კვადრატული კანონის ალგორითმები. ამ ალგორითმების კლასტერული პრობლემა შეიძლება ჩაითვალოს, როგორც ობიექტების ოპტიმალური დაყოფის აგება ჯგუფებად. ამ შემთხვევაში, ოპტიმალურობა შეიძლება განისაზღვროს, როგორც დანაყოფის საშუალო კვადრატული შეცდომის მინიმიზაციის მოთხოვნა:
 ,
,
სადაც გ j - მტევნის „მასის ცენტრი“. ჯ(წერტილი მახასიათებლების საშუალო მნიშვნელობებით მოცემული კლასტერისთვის).
ყველაზე გავრცელებული ალგორითმი ამ კატეგორიაში არის k-means მეთოდი. ეს ალგორითმი აშენებს კლასტერების მოცემულ რაოდენობას, რომლებიც განლაგებულია ერთმანეთისგან რაც შეიძლება შორს. ალგორითმის მოქმედება დაყოფილია რამდენიმე ეტაპად:
შემთხვევით აირჩიეთ კწერტილები, რომლებიც წარმოადგენენ მტევნის საწყისი „მასის ცენტრებს“.
2. თითოეულ ობიექტს მიაკუთვნეთ კლასტერს უახლოესი „მასობრივი ცენტრი“.
თუ ალგორითმის შეჩერების კრიტერიუმი არ არის დაკმაყოფილებული, დაუბრუნდით მე-2 პუნქტს.
ალგორითმის მოქმედების შეჩერების კრიტერიუმად ჩვეულებრივ არჩეულია ფესვის საშუალო კვადრატის შეცდომის მინიმალური ცვლილება. ასევე შესაძლებელია ალგორითმის მოქმედების შეჩერება, თუ მე-2 საფეხურზე არ იყო ობიექტები გადატანილი კლასტერიდან კლასტერში. ამ ალგორითმის უარყოფითი მხარე მოიცავს დაყოფისთვის კლასტერების რაოდენობის მითითების აუცილებლობას.
ყველაზე პოპულარული ბუნდოვანი კლასტერიზაციის ალგორითმი არის c-means ალგორითმი. ეს არის k-means მეთოდის მოდიფიკაცია. ალგორითმის ნაბიჯები:
1. აირჩიეთ საწყისი ბუნდოვანი დანაყოფი ნობიექტები კკლასტერები წევრობის მატრიცის არჩევით Uზომა n x k.
2. U მატრიცის გამოყენებით იპოვეთ ბუნდოვანი შეცდომის კრიტერიუმის მნიშვნელობა:
 ,
,
სადაც გ k - ბუნდოვანი მტევნის "მასის ცენტრი". კ:
3. ობიექტების გადაჯგუფება ბუნდოვანი შეცდომის კრიტერიუმის ამ მნიშვნელობის შესამცირებლად.
4. დაუბრუნდით მე-2 საფეხურს, სანამ მატრიცა არ შეიცვლება Uარ გახდება უმნიშვნელო.
ამ ალგორითმმა შეიძლება არ იმუშაოს, თუ კლასტერების რაოდენობა წინასწარ უცნობია, ან აუცილებელია თითოეული ობიექტის ცალსახად მინიჭება ერთ კლასტერზე.
ალგორითმების შემდეგი ჯგუფი არის გრაფიკების თეორიაზე დაფუძნებული ალგორითმები. ასეთი ალგორითმების არსი მდგომარეობს იმაში, რომ ობიექტების შერჩევა წარმოდგენილია გრაფიკის სახით. G = (V, E), რომლის წვეროები შეესაბამება ობიექტებს, ხოლო კიდეებს აქვთ წონა ტოლი ობიექტებს შორის "მანძილის". გრაფიკის კლასტერიზაციის ალგორითმების უპირატესობებია სიცხადე, განხორციელების შედარებით სიმარტივე და გეომეტრიული მოსაზრებების საფუძველზე სხვადასხვა გაუმჯობესების შესაძლებლობა. ძირითადი ალგორითმებია დაკავშირებული კომპონენტების ამოღების ალგორითმი, მინიმალური გაშლილი ხის აგების ალგორითმი და ფენა-ფენა კლასტერის ალგორითმი.
პარამეტრის შესარჩევად რჩვეულებრივ გამოსახულია წყვილი მანძილის განაწილების ჰისტოგრამა. მონაცემთა კარგად გამოხატული კასეტური სტრუქტურის პრობლემების დროს ჰისტოგრამას ექნება ორი პიკი - ერთი შეესაბამება კლასტერშიდა დისტანციებს, მეორე - კლასტერთაშორის დისტანციებს. Პარამეტრი რშერჩეულია ამ მწვერვალებს შორის მინიმალური ზონიდან. ამავდროულად, საკმაოდ რთულია კლასტერების რაოდენობის კონტროლი მანძილის ზღვრის გამოყენებით.
მინიმალური გაშლილი ხის ალგორითმი ჯერ აყალიბებს მინიმალურ გაშლილ ხეს გრაფიკზე და შემდეგ თანმიმდევრულად აშორებს ყველაზე მაღალი წონის კიდეებს. ფენა-ფენა კლასტერის ალგორითმი ეფუძნება გრაფიკის დაკავშირებული კომპონენტების შერჩევას ობიექტებს შორის მანძილების გარკვეულ დონეზე (ვერტიკებზე). მანძილის დონე განისაზღვრება მანძილის ზღვრით გ... მაგალითად, თუ მანძილი ობიექტებს შორის, მაშინ.
ფენა-ფენა კლასტერიზაციის ალგორითმი ქმნის გრაფიკის ქვეგრაფების თანმიმდევრობას გრომლებიც ასახავს იერარქიულ კავშირებს კლასტერებს შორის:
![]() ,
,
სადაც გტ = (V, Eტ )
- გრაფიკი დონეზე თანტ, ![]() ,
,
თან t არის მანძილის t-th ბარიერი, m არის იერარქიის დონეების რაოდენობა,
გ 0 = (V, o), o არის გრაფიკის კიდეების ცარიელი ნაკრები, რომელიც მიღებულია ტ 0 = 1,
გმ = გ, ანუ ობიექტების გრაფიკი მანძილის შეზღუდვის გარეშე (გრაფიკის კიდეების სიგრძე), ვინაიდან ტმ = 1.
მანძილის ზღურბლების შეცვლით ( თან 0 ,…, თანმ), სადაც 0 = თან 0 < თან 1 < …< თან m = 1, შესაძლებელია მიღებული კლასტერების იერარქიის სიღრმის კონტროლი. ამრიგად, ფენა-ფენა კლასტერიზაციის ალგორითმს შეუძლია შექმნას როგორც ბრტყელი, ისე იერარქიული მონაცემების დაყოფა.
კლასტერირება საშუალებას გაძლევთ მიაღწიოთ შემდეგ მიზნებს:
· აუმჯობესებს მონაცემთა გაგებას სტრუქტურული ჯგუფების გამოვლენით. ნიმუშის მსგავსი ობიექტების ჯგუფებად დაყოფა შესაძლებელს ხდის მონაცემთა შემდგომი დამუშავებისა და გადაწყვეტილების მიღების გამარტივებას თითოეულ კლასტერზე საკუთარი ანალიზის მეთოდის გამოყენებით;
· საშუალებას გაძლევთ კომპაქტურად შეინახოთ მონაცემები. ამისათვის, მთლიანი ნიმუშის შენახვის ნაცვლად, შეგიძლიათ დატოვოთ ერთი ტიპიური დაკვირვება თითოეული კლასტერიდან;
· ახალი ატიპიური ობიექტების გამოვლენა, რომლებიც არ შედიოდა არცერთ კლასტერში.
როგორც წესი, კლასტერირება გამოიყენება როგორც დამხმარე საშუალება მონაცემთა ანალიზისთვის.
2.6 გენეტიკური ალგორითმები
გენეტიკური ალგორითმები არის უნივერსალური ოპტიმიზაციის მეთოდებს შორის, რომლებიც საშუალებას გაძლევთ გადაჭრას სხვადასხვა ტიპის (კომბინატორიული, ზოგადი პრობლემები შეზღუდვებით და გარეშე) და სირთულის სხვადასხვა ხარისხით. ამავდროულად, გენეტიკურ ალგორითმებს ახასიათებს როგორც ერთკრიტერიუმიანი, ისე მრავალკრიტერიუმიანი ძიების შესაძლებლობა დიდ სივრცეში, რომლის ლანდშაფტი არ არის გლუვი.
მეთოდების ეს ჯგუფი იყენებს მოდელების თაობების თანმიმდევრობის ევოლუციის განმეორებით პროცესს, მათ შორის შერჩევის, მუტაციისა და გადაკვეთის ოპერაციებს. ალგორითმის დასაწყისში პოპულაცია ყალიბდება შემთხვევით. კოდირებული გადაწყვეტილებების ხარისხის შესაფასებლად გამოიყენება ფიტნესის ფუნქცია, რომელიც აუცილებელია თითოეული ინდივიდის ფიტნესის გამოსათვლელად. ინდივიდების შეფასების შედეგების მიხედვით, მათგან ყველაზე ადაპტირებული შერჩეულია გადაკვეთისთვის. შერჩეული ინდივიდების შეჯვარების შედეგად გენეტიკური გადაკვეთის ოპერატორის გამოყენებით წარმოიქმნება შთამომავლობა, რომლის გენეტიკური ინფორმაცია ყალიბდება მშობელ ინდივიდებს შორის ქრომოსომული ინფორმაციის გაცვლის შედეგად. შექმნილი შთამომავლობა ქმნის ახალ პოპულაციას და ზოგიერთი შთამომავლობა მუტაციას განიცდის, რაც გამოიხატება მათი გენოტიპების შემთხვევითი ცვლილებით. ეტაპს, რომელიც მოიცავს თანმიმდევრობას "პოპულაციის შეფასება" - "არჩევა" - "გადაკვეთა" - "მუტაცია" ეწოდება თაობას. მოსახლეობის ევოლუცია შედგება ასეთი თაობების თანმიმდევრობისგან.
გამოირჩევა შემდეგი ალგორითმები გადაკვეთისთვის პირების არჩევისთვის:
· პანმიქსია. ორივე ინდივიდი, რომლებიც ქმნიან მშობელთა წყვილს, შემთხვევითად შერჩეულია მთელი პოპულაციისგან. ნებისმიერ ინდივიდს შეუძლია გახდეს რამდენიმე წყვილის წევრი. ეს მიდგომა უნივერსალურია, მაგრამ ალგორითმის ეფექტურობა მცირდება მოსახლეობის რაოდენობის მატებასთან ერთად.
· შერჩევა. საშუალო ფიზიკური ვარჯიშის მქონე პირებს შეუძლიათ გახდნენ მშობლები. ეს მიდგომა უზრუნველყოფს ალგორითმის უფრო სწრაფ კონვერგენციას.
· შეჯვარება. მეთოდი ემყარება ახლო ურთიერთობის საფუძველზე წყვილის ჩამოყალიბებას. აქ ნათესაობა გაგებულია, როგორც მანძილი პოპულაციის წევრებს შორის, როგორც ინდივიდების გეომეტრიული მანძილის მნიშვნელობით პარამეტრულ სივრცეში, ასევე ჰემინგის მანძილით გენოტიპებს შორის. აქედან გამომდინარე, განასხვავებენ გენოტიპურ და ფენოტიპურ შეჯვარებას. გადაკვეთისთვის წყვილის პირველი წევრი ირჩევა შემთხვევით, ხოლო მეორე, უფრო დიდი ალბათობით, იქნება მასთან რაც შეიძლება ახლოს. შეჯვარება შეიძლება ხასიათდებოდეს ლოკალურ კვანძებში ძიების კონცენტრაციის თვისებით, რაც რეალურად იწვევს პოპულაციის ცალკეულ ლოკალურ ჯგუფებად დაყოფას ლანდშაფტის ექსტრემებზე საეჭვო უბნების ირგვლივ.
· გამრავლება. შორეულ ურთიერთობაზე დაფუძნებული წყვილის ჩამოყალიბება ყველაზე შორეული ინდივიდებისთვის. Outbreeding მიზნად ისახავს თავიდან აიცილოს ალგორითმის კონვერგენცია უკვე ნაპოვნი გადაწყვეტილებებთან, აიძულოს ალგორითმი მოძებნოს ახალი, შეუსწავლელი ადგილები.
ალგორითმები ახალი პოპულაციის ფორმირებისთვის:
· შერჩევა გადაადგილებით. ერთი და იგივე გენოტიპის მქონე ყველა ინდივიდიდან უპირატესობა ენიჭება მათ, ვისი ფიტნესი უფრო მაღალია. ამრიგად, მიღწეულია ორი მიზანი: საუკეთესოდ ნაპოვნი ხსნარები სხვადასხვა ქრომოსომული ნაკრებით არ იკარგება; საკმარისი გენეტიკური მრავალფეროვნება მუდმივად შენარჩუნებულია პოპულაციაში. გადაადგილება აყალიბებს შორეულ ინდივიდების ახალ პოპულაციას, ნაცვლად იმისა, რომ ინდივიდები დაჯგუფდნენ მიმდინარე გამოსავლის ირგვლივ. ეს მეთოდი გამოიყენება მრავალ ექსტრემალური ამოცანებისთვის.
· ელიტური შერჩევა. ელიტური შერჩევის მეთოდები უზრუნველყოფს მოსახლეობის საუკეთესო წევრების გადარჩენის გარანტიას. ამავდროულად, ზოგიერთი საუკეთესო ინდივიდი ყოველგვარი ცვლილების გარეშე გადადის მომავალ თაობაში. ელიტის შერჩევის შედეგად მიღწეული სწრაფი კონვერგენცია შეიძლება კომპენსირებული იყოს მშობლის შერჩევის შესაბამისი მეთოდით. ამ შემთხვევაში ხშირად გამოიყენება გამრავლება. სწორედ ეს კომბინაცია „გამრავლება - ელიტური სელექცია“ არის ერთ-ერთი ყველაზე ეფექტური.
· ტურნირის შერჩევა. ტურნირის შერჩევა ახორციელებს n ტურნირს n ინდივიდის შესარჩევად. თითოეული ტურნირი აგებულია მოსახლეობის k ელემენტების ნიმუშზე და მათ შორის საუკეთესო ინდივიდის შერჩევაზე. ყველაზე გავრცელებული ტურნირის შერჩევა k = 2-ით.
მონაცემთა მოპოვების სფეროში გენეტიკური ალგორითმების ერთ-ერთი ყველაზე პოპულარული გამოყენება არის ყველაზე ოპტიმალური მოდელის ძიება (ალგორითმის ძიება, რომელიც შეესაბამება კონკრეტული სფეროს სპეციფიკას). გენეტიკური ალგორითმები ძირითადად გამოიყენება ნერვული ქსელის ტოპოლოგიისა და წონის ოპტიმიზაციისთვის. თუმცა, მათი დამოუკიდებელ იარაღად გამოყენებაც შესაძლებელია.
3. გამოყენების სფეროები
მონაცემთა მოპოვების ტექნოლოგიას აქვს აპლიკაციების მართლაც ფართო სპექტრი, რაც, ფაქტობრივად, არის უნივერსალური ინსტრუმენტების ნაკრები ნებისმიერი ტიპის მონაცემების გასაანალიზებლად.
მარკეტინგი
ერთ-ერთი ყველაზე ადრეული სფერო, სადაც მონაცემთა მოპოვების ტექნოლოგიები იქნა გამოყენებული, იყო მარკეტინგი. ამოცანა, რომელმაც დაიწყო მონაცემთა მოპოვების მეთოდების შემუშავება, ეწოდება სავაჭრო კალათის ანალიზი.
ეს ამოცანაა იმ პროდუქტების იდენტიფიცირება, რომელთა შეძენასაც მყიდველები ერთად ცდილობენ. საყიდლების კალათის ცოდნა აუცილებელია სარეკლამო კამპანიებისთვის, მომხმარებლისთვის პირადი რეკომენდაციების ფორმირებისთვის, საქონლის მარაგების შექმნის სტრატეგიის შემუშავებისთვის და მათი განლაგების მეთოდების გაყიდვის ზონებში.
ასევე მარკეტინგში წყდება ისეთი ამოცანები, როგორიცაა კონკრეტული პროდუქტის სამიზნე აუდიტორიის განსაზღვრა მისი უფრო წარმატებული პოპულარიზაციისთვის; დროის შაბლონების შესწავლა, რომელიც ეხმარება ბიზნესს ინვენტარიზაციის გადაწყვეტილების მიღებაში; პროგნოზირებადი მოდელების შექმნა, რაც საშუალებას აძლევს საწარმოებს ამოიცნონ გარკვეული ქცევის მქონე მომხმარებელთა სხვადასხვა კატეგორიის საჭიროებების ბუნება; მომხმარებელთა ლოიალობის პროგნოზირება, რაც საშუალებას გაძლევთ წინასწარ განსაზღვროთ კლიენტის წასვლის მომენტი მისი ქცევის გაანალიზებისას და, შესაძლოა, თავიდან აიცილოთ ღირებული მომხმარებლის დაკარგვა.
მრეწველობა
ამ სფეროში ერთ-ერთი მნიშვნელოვანი მიმართულებაა მონიტორინგი და ხარისხის კონტროლი, სადაც ანალიზის ხელსაწყოების გამოყენებით შესაძლებელია აღჭურვილობის გაუმართაობის, გაუმართაობის გამოვლენის პროგნოზირება და სარემონტო სამუშაოების დაგეგმვა. გარკვეული მახასიათებლების პოპულარობის პროგნოზირება და იმის ცოდნა, თუ რომელი მახასიათებლებია ჩვეულებრივ შეკვეთილი ერთად, ხელს უწყობს წარმოების ოპტიმიზაციას, მის ორიენტირებას მომხმარებელთა რეალურ საჭიროებებზე.
Წამალი
მედიცინაში მონაცემთა ანალიზიც საკმაოდ წარმატებით გამოიყენება. ამოცანების მაგალითია გამოკვლევის შედეგების ანალიზი, დიაგნოსტიკა, მკურნალობის მეთოდებისა და მედიკამენტების ეფექტურობის შედარება, დაავადებების ანალიზი და მათი გავრცელება, გვერდითი ეფექტების იდენტიფიცირება. მონაცემთა მოპოვების ტექნოლოგიები, როგორიცაა ასოციაციის წესები და თანმიმდევრული შაბლონები, წარმატებით იქნა გამოყენებული წამლის მიღებასა და გვერდით ეფექტებს შორის კავშირების დასადგენად.
მოლეკულური გენეტიკა და გენეტიკური ინჟინერია
ექსპერიმენტულ მონაცემებში შაბლონების აღმოჩენის ყველაზე მწვავე და ამავდროულად მკაფიო ამოცანაა მოლეკულური გენეტიკა და გენური ინჟინერია. აქ იგი ჩამოყალიბებულია, როგორც მარკერების განმარტება, რომლებიც გაგებულია, როგორც გენეტიკური კოდები, რომლებიც აკონტროლებენ ცოცხალი ორგანიზმის გარკვეულ ფენოტიპურ მახასიათებლებს. ასეთი კოდები შეიძლება შეიცავდეს ასობით, ათასობით ან მეტ დაკავშირებულ ელემენტს. მონაცემების ანალიტიკური ანალიზის შედეგია აგრეთვე გენეტიკოსების მიერ აღმოჩენილი პირის დნმ-ის თანმიმდევრობის ცვლილებასა და სხვადასხვა დაავადების განვითარების რისკს შორის კავშირი.
გამოყენებითი ქიმია
მონაცემთა მოპოვების მეთოდები ასევე გამოიყენება გამოყენებითი ქიმიის დარგში. აქ ხშირად ჩნდება კითხვა გარკვეული ნაერთების ქიმიური სტრუქტურის თავისებურებების გარკვევის შესახებ, რომლებიც განსაზღვრავენ მათ თვისებებს. ეს პრობლემა განსაკუთრებით აქტუალურია რთული ქიმიური ნაერთების ანალიზისას, რომელთა აღწერა მოიცავს ასობით და ათასობით სტრუქტურულ ელემენტს და მათ ბმებს.
დანაშაულთან ბრძოლა
მონაცემთა მოპოვების ინსტრუმენტები შედარებით ცოტა ხნის წინ იქნა გამოყენებული უსაფრთხოების უზრუნველსაყოფად, თუმცა უკვე მიღებულია პრაქტიკული შედეგები, რომლებიც ადასტურებენ მონაცემთა მოპოვების ეფექტურობას ამ სფეროში. შვეიცარიელმა მეცნიერებმა შეიმუშავეს საპროტესტო აქტივობის ანალიზის სისტემა მომავალი ინციდენტების პროგნოზირების მიზნით და მსოფლიოში წარმოქმნილი კიბერ საფრთხეებისა და ჰაკერების ქმედებების თვალთვალის სისტემა. ეს უკანასკნელი სისტემა კიბერ საფრთხეების და ინფორმაციული უსაფრთხოების სხვა რისკების პროგნოზირების საშუალებას იძლევა. ასევე, მონაცემთა მოპოვების მეთოდები წარმატებით გამოიყენება საკრედიტო ბარათის თაღლითობის გამოსავლენად. წარსული ტრანზაქციების ანალიზით, რომლებიც მოგვიანებით აღმოჩნდა თაღლითური, ბანკი ადგენს ასეთი თაღლითობის ზოგიერთ სტერეოტიპს.
სხვა აპლიკაციები
· რისკის ანალიზი. მაგალითად, გადახდილ ზარალთან დაკავშირებული ფაქტორების კომბინაციების იდენტიფიცირებით, მზღვეველებს შეუძლიათ შეამცირონ თავიანთი ვალდებულებების ზარალი. ცნობილია შემთხვევა, როდესაც შეერთებულ შტატებში მსხვილმა სადაზღვევო კომპანიამ აღმოაჩინა, რომ დაქორწინებულთა ჩვენებებზე გადახდილი თანხები ორჯერ აღემატებოდა მარტოხელა პირთა ჩვენებებზე გადახდილ თანხას. კომპანიამ უპასუხა ამ ახალ ცოდნას საოჯახო მომხმარებლებისთვის ფასდაკლების პოლიტიკის გადახედვით.
· მეტეოროლოგია. ამინდის პროგნოზირება ნერვული ქსელების გამოყენებით, კერძოდ, გამოიყენება თვითორგანიზებული Kohonen რუქები.
· საკადრო პოლიტიკა. ანალიზის ინსტრუმენტები ეხმარება HR სერვისებს, შეარჩიონ ყველაზე წარმატებული კანდიდატები მათი რეზიუმეს მონაცემების ანალიზის საფუძველზე, მოდელირდნენ კონკრეტული პოზიციისთვის იდეალური თანამშრომლების მახასიათებლებს.
4. მონაცემთა მოპოვების ინსტრუმენტების მწარმოებლები
მონაცემთა მოპოვების ინსტრუმენტები ტრადიციულად ეკუთვნის ძვირადღირებულ პროგრამულ პროდუქტებს. ამიტომ, ბოლო დრომდე, ამ ტექნოლოგიის ძირითადი მომხმარებლები იყვნენ ბანკები, ფინანსური და სადაზღვევო კომპანიები, მსხვილი სავაჭრო საწარმოები, ხოლო ძირითადი ამოცანები, რომლებიც მოითხოვდნენ მონაცემთა მოპოვების გამოყენებას, იყო საკრედიტო და სადაზღვევო რისკების შეფასება და მარკეტინგული პოლიტიკის, სატარიფო გეგმების შემუშავება. და კლიენტებთან მუშაობის სხვა პრინციპები. ბოლო წლებში სიტუაციამ გარკვეული ცვლილებები განიცადა: პროგრამული უზრუნველყოფის ბაზარზე გამოჩნდა შედარებით იაფი მონაცემთა მოპოვების ინსტრუმენტები და უფასო სადისტრიბუციო სისტემებიც კი, რამაც ეს ტექნოლოგია ხელმისაწვდომი გახადა მცირე და საშუალო ბიზნესისთვის.
ფასიან ინსტრუმენტებსა და მონაცემთა ანალიზის სისტემებს შორის ლიდერები არიან SAS Institute (SAS Enterprise Miner), SPSS (SPSS, Clementine) და StatSoft (STATISTICA Data Miner). საკმაოდ ცნობილია Angoss-ის (Angoss KnowledgeSTUDIO), IBM (IBM SPSS Modeler), Microsoft-ის (Microsoft Analysis Services) და (Oracle) Oracle Data Mining-ის გადაწყვეტილებები.
უფასო პროგრამული უზრუნველყოფის არჩევანი ასევე მრავალფეროვანია. არსებობს როგორც უნივერსალური ანალიზის ხელსაწყოები, როგორიცაა JHepWork, KNIME, Orange, RapidMiner და სპეციალიზებული ხელსაწყოები, მაგალითად, Carrot2 - ჩარჩო ტექსტური მონაცემებისა და ძიების შედეგების კლასტერისთვის, Chemicalize.org - გამოსავალი გამოყენებითი ქიმიის სფეროში, NLTK. (Natural Language Toolkit) ბუნებრივი ენის დამუშავების ინსტრუმენტი.
5. მეთოდების კრიტიკა
მონაცემთა მოპოვების შედეგები დიდწილად დამოკიდებულია მონაცემთა მომზადების დონეზე და არა რომელიმე ალგორითმის ან ალგორითმების ნაკრების „სასწაულო შესაძლებლობებზე“. მონაცემთა მოპოვებაზე სამუშაოს დაახლოებით 75% მოიცავს მონაცემთა შეგროვებას, რომელიც კეთდება ანალიზის ინსტრუმენტების გამოყენებამდეც კი. ხელსაწყოების გაუნათლებელი გამოყენება გამოიწვევს კომპანიის პოტენციალის უაზრო ხარჯვას, ზოგჯერ კი მილიონობით დოლარს.
ჰერბ ედელშტეინის, მსოფლიოში ცნობილი ექსპერტის მონაცემების მოპოვების, მონაცემთა შენახვისა და CRM-ის მიხედვით: „ორი ყვავის ბოლო კვლევამ აჩვენა, რომ მონაცემთა მოპოვება ჯერ კიდევ ადრეულ ეტაპზეა. ბევრი ორგანიზაცია დაინტერესებულია ამ ტექნოლოგიით, მაგრამ მხოლოდ რამდენიმე ახორციელებს აქტიურად ასეთ პროექტებს. ჩვენ მოვახერხეთ კიდევ ერთი მნიშვნელოვანი პუნქტის გარკვევა: მონაცემთა მოპოვების პრაქტიკაში დანერგვის პროცესი მოსალოდნელზე უფრო რთული აღმოჩნდება.გუნდები გაიტაცა მითით, რომ მონაცემთა მოპოვების ინსტრუმენტები მარტივი გამოსაყენებელია. ვარაუდობენ, რომ საკმარისია ასეთი ხელსაწყოს გაშვება ტერაბაიტის მონაცემთა ბაზაში და მაშინვე გამოჩნდება სასარგებლო ინფორმაცია. სინამდვილეში, წარმატებული მონაცემთა მოპოვების პროექტი მოითხოვს საქმიანობის არსის გააზრებას, მონაცემთა და ინსტრუმენტების ცოდნას, ასევე მონაცემთა ანალიზის პროცესს. ” ამრიგად, მონაცემთა მაინინგის ტექნოლოგიის გამოყენებამდე საჭიროა ფრთხილად გაანალიზდეს მეთოდებით დაწესებული შეზღუდვები და მასთან დაკავშირებული კრიტიკული საკითხები, ასევე ფხიზელი შეფასდეს ტექნოლოგიის შესაძლებლობები. კრიტიკული საკითხები მოიცავს შემდეგს:
1. ტექნოლოგია ვერ გასცემს პასუხს კითხვებზე, რომლებიც დაუსვეს. მას არ შეუძლია ჩაანაცვლოს ანალიტიკოსი, მაგრამ მხოლოდ აძლევს მას მძლავრ ინსტრუმენტს მისი მუშაობის გასაადვილებლად და გასაუმჯობესებლად.
2. მონაცემთა მოპოვების აპლიკაციის შემუშავებისა და ექსპლუატაციის სირთულე.
ვინაიდან ეს ტექნოლოგია მულტიდისციპლინარული სფეროა, აპლიკაციის შესაქმნელად, რომელიც მოიცავს მონაცემთა მოპოვებას, აუცილებელია სხვადასხვა სფეროს სპეციალისტების ჩართვა, ასევე მათი მაღალი ხარისხის ურთიერთქმედების უზრუნველყოფა.
3. მომხმარებლის კვალიფიკაცია.
მონაცემთა მოპოვების სხვადასხვა ინსტრუმენტს აქვს მომხმარებლის კეთილგანწყობის განსხვავებული ხარისხი და მოითხოვს მომხმარებლის გარკვეულ კვალიფიკაციას. ამიტომ, პროგრამა უნდა შეესაბამებოდეს მომხმარებლის მომზადების დონეს. მონაცემთა მოპოვების გამოყენება განუყოფლად უნდა იყოს დაკავშირებული მომხმარებლის კვალიფიკაციის ამაღლებასთან. თუმცა, ამჟამად ცოტაა მონაცემთა მოპოვების სპეციალისტი, რომლებიც კარგად ერკვევიან ბიზნეს პროცესებში.
4. სასარგებლო ინფორმაციის მოპოვება შეუძლებელია მონაცემთა არსის კარგად გააზრების გარეშე.
საჭიროა მოდელის ფრთხილად შერჩევა და აღმოჩენილი დამოკიდებულებების ან შაბლონების ინტერპრეტაცია. ამიტომ, ასეთ ინსტრუმენტებთან მუშაობა მოითხოვს მჭიდრო თანამშრომლობას საგნის ექსპერტსა და მონაცემთა მოპოვების ინსტრუმენტის სპეციალისტს შორის. მუდმივი მოდელები ინტელექტუალურად უნდა იყოს ინტეგრირებული ბიზნეს პროცესებში, რათა შეძლონ მოდელების შეფასება და განახლება. ცოტა ხნის წინ, მონაცემთა მოპოვების სისტემები იქნა გაგზავნილი, როგორც მონაცემთა საწყობის ტექნოლოგიის ნაწილი.
5. მონაცემთა მომზადების სირთულე.
წარმატებული ანალიზი მოითხოვს მაღალი ხარისხის მონაცემთა წინასწარ დამუშავებას. ანალიტიკოსებისა და მონაცემთა ბაზის მომხმარებლების აზრით, წინასწარი დამუშავების პროცესს შეუძლია მონაცემთა მოპოვების მთელი პროცესის 80%-მდე დასჭირდეს.
ამრიგად, იმისთვის, რომ ტექნოლოგიამ თავისთვის იმუშაოს, დასჭირდება დიდი ძალისხმევა და დრო, რომელიც იხარჯება მონაცემთა წინასწარ ანალიზზე, მოდელის შერჩევასა და მის კორექტირებაზე.
6. ცრუ, არასანდო ან უსარგებლო შედეგების დიდი პროცენტი.
მონაცემთა მოპოვების ტექნოლოგიების დახმარებით თქვენ შეგიძლიათ იპოვოთ მართლაც ძალიან ღირებული ინფორმაცია, რომელსაც შეუძლია მნიშვნელოვანი უპირატესობა მისცეს შემდგომი დაგეგმვის, მართვისა და გადაწყვეტილების მიღებისას. თუმცა მონაცემთა მოპოვების მეთოდებით მიღებული შედეგები საკმაოდ ხშირად შეიცავს ცრუ და უაზრო დასკვნებს. ბევრი ექსპერტი ამტკიცებს, რომ მონაცემთა მოპოვების ინსტრუმენტებს შეუძლიათ სტატისტიკურად არასანდო შედეგების უზარმაზარი რაოდენობა. ასეთი შედეგების პროცენტული შემცირების მიზნით აუცილებელია ტესტის მონაცემებზე მიღებული მოდელების ადეკვატურობის შემოწმება. თუმცა, შეუძლებელია ცრუ დასკვნების სრულად თავიდან აცილება.
7. მაღალი ღირებულება.
ხარისხიანი პროგრამული პროდუქტი არის დეველოპერის მხრიდან მნიშვნელოვანი ძალისხმევის შედეგი. ამიტომ, მონაცემთა მოპოვების პროგრამა ტრადიციულად ითვლება ძვირადღირებულ პროგრამულ პროდუქტად.
8. საკმარისი წარმომადგენლობითი მონაცემების არსებობა.
მონაცემთა მოპოვების ინსტრუმენტები, სტატისტიკურისგან განსხვავებით, თეორიულად არ საჭიროებს ისტორიული მონაცემების მკაცრად განსაზღვრულ რაოდენობას. ამ მახასიათებელმა შეიძლება გამოიწვიოს არაზუსტი, ყალბი მოდელების გამოვლენა და, შედეგად, მათზე დაყრდნობით არასწორი გადაწყვეტილებების მიღება. აუცილებელია აღმოჩენილი ცოდნის სტატისტიკური მნიშვნელობის კონტროლი.
ნერვული ქსელის ალგორითმის კლასტერირება მონაცემთა მოპოვება
დასკვნა
მოცემულია გამოყენების სფეროების მოკლე აღწერა და მოცემულია მონაცემთა მოპოვების ტექნოლოგიის კრიტიკა და ამ სფეროში ექსპერტების მოსაზრებები.
სიალიტერატურა
1. ჰანი და მიშლინ კამბერები. მონაცემთა მოპოვება: ცნებები და ტექნიკა. Მეორე გამოცემა. - ილინოისის უნივერსიტეტი ურბანა-შამპეინში
ბერი, მაიკლ ჯ.ა. მონაცემთა მოპოვების ტექნიკა: მარკეტინგის, გაყიდვების და მომხმარებელთან ურთიერთობის მენეჯმენტისთვის - 2nd ed.
სიუ ნინ ლამ. ასოციაციის წესების აღმოჩენა მონაცემთა მოპოვებაში. - ილინოისის კომპიუტერული მეცნიერების უნივერსიტეტის დეპარტამენტი ურბანა-შამპეინში
თქვენი კარგი სამუშაოს გაგზავნა ცოდნის ბაზაში მარტივია. გამოიყენეთ ქვემოთ მოცემული ფორმა
სტუდენტები, კურსდამთავრებულები, ახალგაზრდა მეცნიერები, რომლებიც იყენებენ ცოდნის ბაზას სწავლასა და მუშაობაში, ძალიან მადლობლები იქნებიან თქვენი.
მსგავსი დოკუმენტები
- მომხმარებელთა ტრაექტორიების ანალიზი ვებსაიტის მონახულებადან საქონლის შეძენამდე
- მომსახურების ეფექტურობის შეფასება, საქონლის ნაკლებობის გამო ჩავარდნების ანალიზი
- მნახველებისთვის საინტერესო საქონლის დაკავშირება
- სავაჭრო კალათის ანალიზი;
- პროგნოზირებადი მოდელების შექმნამყიდველებისა და შეძენილი საქონლის კლასიფიკაციის მოდელები;
- მომხმარებლის პროფილების შექმნა;
- CRM, სხვადასხვა კატეგორიის მომხმარებლის ლოიალობის შეფასება, ლოიალობის პროგრამების დაგეგმვა;
- დროის სერიების კვლევადა დროზე დამოკიდებულებები, სეზონური ფაქტორების ხაზგასმა, აქციების ეფექტურობის შეფასება რეალური მონაცემების დიდ დიაპაზონზე.
- მომხმარებელთა კლასიფიკაცია ზარების ძირითადი მახასიათებლების მიხედვით (სიხშირე, ხანგრძლივობა და ა.შ.), SMS სიხშირე;
- მომხმარებელთა ლოიალობის იდენტიფიცირება;
- თაღლითობის განმარტება და ა.შ.
- რისკის ანალიზი... გადახდილ ზარალებთან დაკავშირებული ფაქტორების კომბინაციის იდენტიფიცირებით, მზღვეველებს შეუძლიათ შეამცირონ თავიანთი ვალდებულებების ზარალი. ცნობილია შემთხვევა, როდესაც სადაზღვევო კომპანიამ დაადგინა, რომ დაქორწინებულთა პრეტენზიებზე გადახდილი თანხები ორჯერ აღემატებოდა მარტოხელა ადამიანების პრეტენზიებს. კომპანიამ უპასუხა საოჯახო ფასდაკლების პოლიტიკის გადახედვით.
- თაღლითობის გამოვლენა... სადაზღვევო კომპანიებს შეუძლიათ შეამცირონ თაღლითობა კონკრეტული სტერეოტიპების მოძიებით პრეტენზიებში, რომლებიც ახასიათებს ურთიერთობას იურისტებს, ექიმებსა და მოსარჩელეებს შორის.
DataMining ამოცანების კლასიფიკაცია. ანგარიშების და ჯამების შექმნა. Data Miner-ის მახასიათებლები სტატისტიკაში. კლასიფიკაციის, კლასტერიზაციის და რეგრესიის პრობლემა. ანალიზის ხელსაწყოები Statistica Data Miner. პრობლემის არსი ასოციაციის წესების ძიებაა. გადარჩენის პროგნოზირების ანალიზი.
საკურსო ნაშრომი, დამატებულია 19.05.2011
მონაცემთა მოპოვების ტექნოლოგიის ფუნქციონირების აღწერა, როგორც უცნობი მონაცემების გამოვლენის პროცესი. ასოციაციური წესებისა და ნერვული ქსელის ალგორითმების მექანიზმების დასკვნის სისტემების შესწავლა. მონაცემთა მაინინგის კლასტერიზაციის ალგორითმებისა და გამოყენების სფეროების აღწერა.
ტესტი, დამატებულია 06/14/2013
კლასტერიზაციის საფუძვლები. მონაცემთა მოპოვების გამოყენება „ბაზებში ცოდნის აღმოსაჩენად“. კლასტერიზაციის ალგორითმების არჩევანი. მონაცემთა მოძიება დისტანციური სახელოსნოს მონაცემთა ბაზის საცავიდან. მოსწავლეთა კლასტერირება და ამოცანები.
საკურსო ნაშრომი დამატებულია 07/10/2017
მონაცემთა მოპოვება, მონაცემთა მოპოვების განვითარების ისტორია და ცოდნის აღმოჩენა. მონაცემთა მოპოვების ტექნოლოგიური ელემენტები და მეთოდები. ნაბიჯები ცოდნის აღმოჩენაში. ცვლილების და გადახრის გამოვლენა. დაკავშირებული დისციპლინები, ინფორმაციის მოძიება და ტექსტის მოპოვება.
ანგარიში დამატებულია 06/16/2012
კლასტერიზაციის მეთოდებისა და ალგორითმების გამოყენების შედეგად წარმოქმნილი პრობლემების ანალიზი. კლასტერიზაციის ძირითადი ალგორითმები. RapidMiner პროგრამული უზრუნველყოფა, როგორც გარემო მანქანური სწავლისა და მონაცემთა ანალიზისთვის. კლასტერინგის ხარისხის შეფასება მონაცემთა მოპოვების მეთოდების გამოყენებით.
საკურსო ნაშრომი, დამატებულია 22.10.2012
მონაცემთა ჩაწერისა და შენახვის ტექნოლოგიების გაუმჯობესება. ინფორმაციის მონაცემთა დამუშავების თანამედროვე მოთხოვნების სპეციფიკა. მრავალგანზომილებიანი ურთიერთობების ფრაგმენტების ამსახველი შაბლონების კონცეფცია მონაცემთა მოპოვების თანამედროვე ტექნოლოგიის ცენტრში.
ტესტი, დამატებულია 09/02/2010
ნერვული ქსელების გამოყენების ანალიზი საფონდო ბირჟაზე სიტუაციის პროგნოზირებისთვის და გადაწყვეტილების მისაღებად Trajan 3.0 ნერვული ქსელის მოდელირების პროგრამული პაკეტის გამოყენებით. პირველადი მონაცემების, ცხრილების კონვერტაცია. ერგონომიული პროგრამის შეფასება.
დისერტაცია, დამატებულია 06/27/2011
ევოლუციური ალგორითმების გამოყენების სირთულეები. გამოთვლითი სისტემების აგება ბუნებრივი გადარჩევის პრინციპებზე დაყრდნობით. გენეტიკური ალგორითმების ნაკლოვანებები. ევოლუციური ალგორითმების მაგალითები. ევოლუციური მოდელირების მიმართულებები და სექციები.
მივესალმებით მონაცემთა მოპოვების პორტალს - უნიკალური პორტალი, რომელიც ეძღვნება მონაცემთა მოპოვების თანამედროვე მეთოდებს.
მონაცემთა მოპოვების ტექნოლოგიები თანამედროვე ბიზნეს დაზვერვისა და მონაცემთა მოპოვების მძლავრი ინსტრუმენტია ფარული შაბლონების აღმოსაჩენად და პროგნოზირებადი მოდელების შესაქმნელად. მონაცემთა მოპოვება ან ცოდნის მოპოვება ეფუძნება არა სპეკულაციურ მსჯელობას, არამედ რეალურ მონაცემებს.

ბრინჯი. 1. მონაცემთა მოპოვების აპლიკაციის სქემა
პრობლემის განმარტება - პრობლემის ფორმულირება: მონაცემთა კლასიფიკაცია, სეგმენტაცია, პროგნოზირებადი მოდელების აგება, პროგნოზირება.
მონაცემთა შეგროვება და მომზადება - მონაცემთა შეგროვება და მომზადება, გაწმენდა, გადამოწმება, დუბლიკატი ჩანაწერების წაშლა.
მოდელის შენობა - მოდელის აგება, სიზუსტის შეფასება.
ცოდნის დანერგვა - მოდელის გამოყენება მოცემული პრობლემის გადასაჭრელად.
მონაცემთა მოპოვება გამოიყენება ფართომასშტაბიანი ანალიტიკური პროექტების განსახორციელებლად ბიზნესში, მარკეტინგში, ინტერნეტში, ტელეკომუნიკაციებში, მრეწველობაში, გეოლოგიაში, მედიცინაში, ფარმაცევტულ და სხვა სფეროებში.
მონაცემთა მოპოვება საშუალებას გაძლევთ დაიწყოთ მნიშვნელოვანი კორელაციებისა და კავშირების პოვნის პროცესი, მონაცემთა უზარმაზარი მასივის მოძიების შედეგად, ნიმუშის ამოცნობის თანამედროვე მეთოდების გამოყენებით და უნიკალური ანალიტიკური ტექნოლოგიების გამოყენებით, მათ შორის გადაწყვეტილების ხეები და კლასიფიკაციები, კლასტერირება, ნერვული ქსელის მეთოდები. , და სხვა.
მომხმარებელი, რომელმაც პირველად აღმოაჩინა მონაცემთა მოპოვების ტექნოლოგია, გაოცებულია მეთოდებისა და ეფექტური ალგორითმების სიმრავლით, რომლებიც საშუალებას გაძლევთ იპოვოთ მიდგომები რთული პრობლემების გადასაჭრელად, რომლებიც დაკავშირებულია დიდი რაოდენობით მონაცემთა ანალიზთან.
ზოგადად, მონაცემთა მოპოვება შეიძლება დახასიათდეს, როგორც ტექნოლოგია, რომელიც შექმნილია დიდი რაოდენობით მონაცემების მოსაძიებლად. გაუგებარი, ობიექტურიდა პრაქტიკულად სასარგებლონიმუშები.
მონაცემთა მოპოვება ეფუძნება ეფექტურ მეთოდებსა და ალგორითმებს, რომლებიც შემუშავებულია დიდი მოცულობისა და განზომილების არასტრუქტურირებული მონაცემების ანალიზისთვის.
მთავარი ის არის, რომ დიდი მოცულობის, დიდი განზომილების მონაცემები მოკლებულია სტრუქტურასა და კავშირებს. მონაცემთა მოპოვების ტექნოლოგიის მიზანია ამ სტრუქტურების იდენტიფიცირება და ისეთი შაბლონების პოვნა, სადაც, ერთი შეხედვით, ქაოსი და თვითნებობა სუფევს.
აქ არის მონაცემთა მოპოვების აპლიკაციების მიმდინარე საქმის შესწავლა ფარმაცევტულ და წამლის ინდუსტრიაში.
ნარკოტიკების ურთიერთქმედება მზარდი პრობლემაა თანამედროვე ჯანდაცვის წინაშე.
დროთა განმავლობაში, გამოწერილი წამლების რაოდენობა (ურეცეპტოდ გაცემული და ყველა სახის დანამატი) იზრდება, რაც უფრო და უფრო სავარაუდოს ხდის, რომ წამლების ურთიერთქმედებამ შეიძლება გამოიწვიოს სერიოზული გვერდითი მოვლენები, რომლებიც ექიმებმა და პაციენტებმა არ იციან.
ეს სფერო განეკუთვნება პოსტკლინიკურ კვლევებს, როდესაც პრეპარატი უკვე გამოვიდა ბაზარზე და ინტენსიურად გამოიყენება.
კლინიკური კვლევები დაკავშირებულია პრეპარატის ეფექტურობის შეფასებასთან, მაგრამ არ ითვალისწინებს ამ პრეპარატის ურთიერთქმედებას ბაზარზე არსებულ სხვა პრეპარატებთან.
კალიფორნიის სტენფორდის უნივერსიტეტის მკვლევარებმა გამოიკვლიეს საკვებისა და წამლების ადმინისტრაციის (FDA) მონაცემთა ბაზა მედიკამენტების გვერდითი ეფექტების შესახებ და დაადგინეს, რომ ორი ხშირად გამოყენებული პრეპარატი - ანტიდეპრესანტი პაროქსეტინი და პრავასტატინი, რომლებიც გამოიყენება ქოლესტერინის დონის შესამცირებლად - ზრდის დიაბეტის განვითარების რისკს ერთად გამოყენების შემთხვევაში.
FDA-ს მონაცემებზე დაფუძნებული მსგავსი ანალიზის შედეგად ჩატარებულმა კვლევამ გამოავლინა 47 ადრე უცნობი არასასურველი ურთიერთქმედება.
ეს გასაოცარია, იმ სიფრთხილით, რომ პაციენტების მიერ მოხსენებული მრავალი უარყოფითი ეფექტი ამოუცნობი რჩება. ეს არის ის, სადაც ონლაინ ძიებას შეუძლია ყველაფერი გააკეთოს.
მონაცემთა მოპოვების მომავალი კურსები StatSoft მონაცემთა ანალიზის აკადემიაში 2020 წელს
მონაცემთა მაინინგის გაცნობას ვიწყებთ მონაცემთა ანალიზის აკადემიის შესანიშნავი ვიდეოების გამოყენებით.
აუცილებლად უყურეთ ჩვენს ვიდეოებს და მიხვდებით რა არის მონაცემთა მაინინგი!
ვიდეო 1. რა არის მონაცემთა მოპოვება?
ვიდეო 2. მონაცემთა მოპოვების მეთოდების მიმოხილვა: გადაწყვეტილების ხეები, განზოგადებული პროგნოზირების მოდელები, კლასტერირება და მრავალი სხვა
JavaScript გამორთულია თქვენს ბრაუზერში
კვლევითი პროექტის დაწყებამდე უნდა მოვაწყოთ გარე წყაროებიდან მონაცემების მოპოვების პროცესი, ახლა ვაჩვენებთ როგორ კეთდება ეს.
ვიდეო გაგაცნობთ უნიკალურ ტექნოლოგიას სტატისტიკამონაცემთა ბაზის ადგილზე დამუშავება და მონაცემთა მოპოვების კავშირი რეალურ მონაცემებთან.
ვიდეო 3. მონაცემთა ბაზებთან ურთიერთქმედების თანმიმდევრობა: გრაფიკული ინტერფეისი SQL მოთხოვნების შესაქმნელად მონაცემთა ბაზის ადგილზე დამუშავების ტექნოლოგია
JavaScript გამორთულია თქვენს ბრაუზერში
ჩვენ ახლა ვუყურებთ ბურღვის ინტერაქტიულ ტექნოლოგიებს, რომლებიც ეფექტურია საძიებო მონაცემების ანალიზში. თავად ტერმინი ბურღვა ასახავს მონაცემთა მოპოვების ტექნოლოგიასა და გეოლოგიურ კვლევას შორის კავშირს.
ვიდეო 4. ინტერაქტიული ბურღვა: საძიებო და გრაფიკული ტექნიკა მონაცემთა ინტერაქტიული კვლევისთვის
JavaScript გამორთულია თქვენს ბრაუზერში
ახლა ჩვენ გავეცნობით ასოციაციების ანალიზს (ასოცირების წესებს), ეს ალგორითმები საშუალებას გაძლევთ იპოვოთ რეალურ მონაცემებში არსებული ურთიერთობები. მთავარი პუნქტია ალგორითმების ეფექტურობა დიდი რაოდენობით მონაცემებზე.
ბმულის ანალიზის ალგორითმების შედეგი, მაგალითად, აპრიორის ალგორითმი, არის მოცემული სანდოობით შესწავლილი ობიექტების ბმული წესების მოძიება, მაგალითად, 80%.
გეოლოგიაში, ეს ალგორითმები შეიძლება გამოვიყენოთ მინერალების საძიებო ანალიზში, მაგალითად, როგორ არის დაკავშირებული A ფუნქცია B და C მახასიათებლებთან.
თქვენ შეგიძლიათ იპოვოთ ასეთი გადაწყვეტილებების კონკრეტული მაგალითები ჩვენს ბმულებზე:
საცალო ვაჭრობაში, Apriori ალგორითმი ან მათი მოდიფიკაციები საშუალებას გაძლევთ გამოიკვლიოთ სხვადასხვა პროდუქტის ურთიერთობა, მაგალითად, სუნამოების (პარფიუმერია - ლაქი - ტუში და ა.შ.) ან სხვადასხვა ბრენდის საქონლის გაყიდვისას.
საიტის ყველაზე საინტერესო სექციების ანალიზი ასევე შეიძლება ეფექტურად განხორციელდეს ასოციაციების წესების გამოყენებით.
ასე რომ, ნახეთ ჩვენი შემდეგი ვიდეო.
ვიდეო 5. ასოციაციის წესები
JavaScript გამორთულია თქვენს ბრაუზერში
მოდით მოვიყვანოთ მონაცემთა მოპოვების აპლიკაციის მაგალითები კონკრეტულ სფეროებში.
ონლაინ ვაჭრობა:
საცალო ვაჭრობა: გააანალიზეთ მომხმარებლის ინფორმაცია საკრედიტო ბარათების, ფასდაკლების ბარათების და სხვათა საფუძველზე.
ტიპიური საცალო ამოცანები მოგვარებულია მონაცემთა მოპოვების ინსტრუმენტებით:
სატელეკომუნიკაციო სექტორი ხსნის შეუზღუდავ შესაძლებლობებს მონაცემთა მოპოვების მეთოდების, ასევე თანამედროვე დიდი მონაცემთა ტექნოლოგიების გამოყენებისთვის:
დაზღვევა:
მონაცემთა მოპოვების პრაქტიკული გამოყენება და კონკრეტული პრობლემების გადაჭრა წარმოდგენილია ჩვენს შემდეგ ვიდეოში.
ვებინარი 1. ვებინარი "მონაცემთა მოპოვების პრაქტიკული ამოცანები: პრობლემები და გადაწყვეტილებები"
JavaScript გამორთულია თქვენს ბრაუზერშივებინარი 2. ვებინარი "მონაცემთა მოპოვება და ტექსტის მოპოვება: რეალური პრობლემების გადაჭრის მაგალითები"
JavaScript გამორთულია თქვენს ბრაუზერში
თქვენ შეგიძლიათ მიიღოთ უფრო ღრმა ცოდნა მონაცემთა მოპოვების მეთოდოლოგიისა და ტექნოლოგიის შესახებ StatSoft კურსებზე.