I dagens artikel vill jag beröra ett så enormt ämne som Vanliga uttryck... Jag tror att alla vet att ämnet regexes (som reguljära uttryck kallas på slang) är enormt i volymen av ett inlägg.
Till att börja med finns det flera smaker av reguljära uttryck:
1. Traditionella reguljära uttryck(de är också grundläggande, grundläggande och grundläggande reguljära uttryck(BRE))
- syntaxen för dessa uttryck bedöms vara föråldrad, men ändå är den fortfarande utbredd och används av många UNIX-verktyg
- Grundläggande reguljära uttryck inkluderar följande metatecken (se deras betydelse nedan):
- \ (\) - original för () (i utökat)
- \ (\) - original för () (i utökat)
- \n, var n- nummer från 1 till 9
- Funktioner för att använda dessa metatecken:
- En asterisk måste följa ett uttryck som matchar ett enda tecken. Exempel: *.
- Uttryck \( blockera\) * bör anses ogiltig. I vissa fall matchar den noll eller fler upprepningar av strängen. blockera... I andra matchar den strängen blockera* .
- Inom en teckenklass ignoreras i allmänhet specialteckens betydelser. Speciella fall:
- För att lägga till ett ^-tecken till en uppsättning får det inte placeras först där.
- För att lägga till en symbol - till en uppsättning måste den placeras där först eller sist. Till exempel:
- DNS-namnmönster, som kan innehålla bokstäver, siffror, minus och avgränsningsperiod: [-0-9a-zA-Z.];
- alla tecken utom minus och siffra: [^ -0-9].
- För att lägga till tecknet [eller] till setet måste det placeras där först. Till exempel:
- matchar], [, a eller b.
2. Utökade reguljära uttryck(dom är utökade reguljära uttryck(ERE))
- Syntaxen för dessa uttryck är densamma som för huvuduttrycken, förutom:
- Tog bort användningen av snedstreck för () och () metatecken.
- Omvänt snedstreck framför en metatecken upphäver dess speciella betydelse.
- Förkastade teoretiskt oregelbunden konstruktion \ n .
- Lade till metatecken +,? , | ...
3. Perl-kompatibla reguljära uttryck(dom är Perl-kompatibla reguljära uttryck(PCRE))
- har en rikare och samtidigt förutsägbar syntax än till och med POSIX ERE, därför används den ofta av applikationer.
Vanliga uttryck Bestå av mallar, eller snarare sätta ett mönster Sök. Mallen består från regler sökningar, som är sammansatta av tecken och metatecken.
Sök regler definieras av följande operationer:
Uppräkning |
Vertikal streck (|) separerar acceptabla alternativ, kan vi säga - logiskt ELLER. Till exempel "grå | grå" matchar grå eller grå.
Gruppering eller fackförening ()
Runda fästen används för att definiera operatörernas omfattning och prioritet. Till exempel är "grå | grå" och "gr (a | e) y" olika mönster, men de beskriver båda en uppsättning som innehåller grå och grå.
Kvantifiering ()? * +
Kvantifierare efter att en karaktär eller grupp bestämmer hur många gånger tidigare uttryck kan förekomma.
allmänt uttryck kan upprepningar vara från m till n inklusive.
allmänt uttryck, m eller fler repetitioner.
allmänt uttryck, inte mer än n repetitioner.
slätn upprepningar.
Frågetecken innebär att 0 eller 1 gånger, samma som {0,1} ... Till exempel "colou? R" matchar och Färg, och Färg.
Stjärna innebär att 0, 1 eller valfritt nummer en gång ( {0,} ). Till exempel "go * gle" matchar ggla, gogle, Google och så vidare.
Ett plus innebär att minst 1 en gång ( {1,} ). Till exempel "go + gle" matchar gogle, Google etc. (men inte ggla).
Den specifika syntaxen för dessa reguljära uttryck är implementeringsberoende. (det vill säga i grundläggande reguljära uttryck symboler (och)- kom undan med ett snedstreck)
Metakaraktärer, i enkla termer är dessa symboler som inte motsvarar deras verkliga betydelse, det vill säga en symbol. (punkt) är inte en punkt, utan vilket tecken som helst, etc. vänligen bekanta dig med metakaraktärerna och deras betydelser:
| . | motsvarar ett vilken karaktär som helst |
| [något] | Överensstämmer någon singel ett tecken inom parentes. I det här fallet: Tecknet "-" tolkas bokstavligt endast om det finns omedelbart efter öppningen eller före den avslutande parentesen: eller [-abc]. Annars anger det ett teckenintervall. Matchar till exempel "a", "b" eller "c". matchar gemener i det latinska alfabetet. Dessa beteckningar kan och kombineras: matchar a, b, c, q, r, s, t, u, v, w, x, y, z. För att matcha tecknen "[" eller "]" räcker det att den avslutande parentesen var det första tecknet efter det inledande tecknet: matchar "]", "[", "a" eller "b". Om värdet inom hakparenteser föregås av en ^, så matchar uttryckets värde enda tecken bland dessa som inte står inom parentes... Till exempel matchar [^ abc] alla andra tecken än "a", "b" eller "c". [^ a-z] matchar alla tecken utom latinska gemener. |
| ^ | Matchar början av texten (eller början av valfri rad i linjeläge). |
| $ | Matchar slutet av texten (eller slutet av valfri rad i inline-läge). |
| \(\) eller () | Deklarerar ett "markerat underuttryck" (grupperat uttryck) som kan användas senare (se nästa element: \ n). Det "markerade underuttrycket" är också ett "block". Till skillnad från andra operatörer kräver den här (i traditionell syntax) ett omvänt snedstreck, i utökad och Perl behövs inte \ -. |
| \n | Var n- detta är ett tal från 1 till 9; motsvarar n det markerade underuttrycket (till exempel (abcd) \ 0, det vill säga abcd-tecken är markerade med noll). Denna konstruktion är teoretiskt oregelbunden, accepterades det inte i den utökade syntaxen för reguljära uttryck. |
| * |
Ett uttryck som omges av "\ (" och "\)" följt av "*" bör anses vara ogiltigt. I vissa fall matchar den noll eller fler förekomster av strängen som omges av parentes. I andra matchar det uttrycket inom parentes, givet "*"-tecknet. |
| \{x,y\} | Matchar det senare ( den kommande) till ett block som inträffar åtminstone x och inte mer y en gång. Till exempel, "a \ (3,5 \)" matchar "aaa", "aaaa" eller "aaaaa". Till skillnad från andra operatörer kräver den här (i traditionell syntax) ett snedstreck. |
| .* | Beteckning av valfritt antal tecken mellan två delar av ett reguljärt uttryck. |
Metatecken hjälper oss att använda olika matchningar. Men hur representerar man en metatecken med ett vanligt tecken, det vill säga tecknet [(hakparentes) med värdet på hakparentesen? Bara:
- måste föregås ( skydda) metatecken (. * + \? ()) omvänt snedstreck. Till exempel \. eller \[
För att förenkla definitionen av vissa teckenuppsättningar kombinerades de till den så kallade. karaktärsklasser och kategorier. POSIX har standardiserat deklarationen av vissa klasser och kategorier av symboler, som visas i följande tabell:
| POSIX klass | liknande | beteckning |
| [: övre:] | versaler | |
| [: lägre:] | gemener | |
| [:alfa:] | versaler och gemener | |
| [: alnum:] | siffror, versaler och gemener | |
| [:siffra:] | tal | |
| [: xdigit:] | hexadecimala siffror | |
| [: punkt:] | [.,!?:…] | punkter |
| [: blank:] | [\t] | space och TAB |
| [: Plats:] | [\ t \ n \ r \ f \ v] | hoppa över tecken |
| [: cntrl:] | kontrollsymboler | |
| [: Graf:] | [^ \ t \ n \ r \ f \ v] | skriva ut symboler |
| [: print:] | [^ \ t \ n \ r \ f \ v] | skriva ut och hoppa över tecken |
I regex finns ett sådant koncept som:
Girighet regex
Jag ska försöka beskriva det så tydligt som möjligt. Låt oss säga att vi vill hitta alla HTML-taggar i viss text. Efter att ha lokaliserat uppgiften vill vi hitta de värden som ligger mellan< и >, tillsammans med samma parenteser. Men vi vet att taggarna har olika längd och själva taggarna, minst 50 stycken. För att lista dem alla är det en alltför tidskrävande uppgift att omsluta dem i metatecken. Men vi vet att vi har ett uttryck * (Prick asterisk) som kännetecknar valfritt antal tecken i strängen. Med hjälp av detta uttryck kommer vi att försöka hitta i texten (
Så, Så här skapar du en RAID-nivå 10/50 på en LSI MegaRAID-kontroller (gäller även för: Intel SRCU42x, Intel SRCS16):
) alla värden mellan< и >... Som ett resultat kommer ALLA linjer att matcha detta uttryck. varför, eftersom regexet är GIRIG och försöker fånga ALLA antal tecken däremellan< и >, respektive hela raden, startande < p> Så... och slut ...> kommer att tillhöra denna regel!Förhoppningsvis är detta ett exempel på vad girighet är. För att bli av med denna girighet kan du gå på följande väg:
- ta hänsyn till symbolerna, inte matchar det önskade mönstret (till exempel:<[^>] *> för ovanstående fall)
- bli av med girighet genom att lägga till en icke-girig kvantifieringsdefinition:
- *? - "inte girig" ("lat") motsvarighet *
- +? - "inte girig" ("lat") motsvarande +
- (n,)? - "inte girig" ("lat") motsvarande (n,)
- *? - "inte girig" ("lat") motsvarighet. *
Jag vill komplettera allt ovanstående med den utökade syntaxen för reguljära uttryck:
POSIX reguljära uttryck liknar traditionell Unix-syntax, men med tillägg av några metatecken:
Ett plus indikerar att tidigare symbol eller grupp kan upprepas en eller flera gånger... Till skillnad från en asterisk krävs minst en upprepning.
Frågetecken gör tidigare tecken eller grupp valfritt. Med andra ord, på motsvarande rad, det kan vara frånvarande eller närvarande slät ett en gång.
Vertikal stång separerar alternativa reguljära uttryck. En symbol definierar två alternativ, men det kan finnas fler av dem, det räcker med att använda fler vertikala streck. Kom ihåg att den här operatorn använder så mycket av uttrycket som möjligt. Av denna anledning används den alternativa operatorn oftast inom parentes.
Användningen av omvända snedstreck har också tagits bort: \ (... \) blir (...) och \ (... \) blir (...).
I slutet av inlägget, här är några exempel på hur man använder regex:
$ katt text1 1 äpple 2 päron 3 banan $ grep p text1 1 äpple 2 päron $ grep ärttext1 2 päron $ grep "p *" text1 1 äpple 2 päron 3 banan $ grep "pp *" text1 1 äpple 2 päron $ grep " x "text1 $ grep" x * "text1 1 äpple 2 päron 3 banan $ katt text1 | grep "l \ | n" 1 äpple 3 banan $ echo -e "hitta en \ n * här" | grep "\ *" * här $ grep "pp \ +" text1 # rader som innehåller ett p och 1 eller fler p 1 äpple $ grep "pl \? e" text1 1 äpple 2 päron $ grep "pl \? e" text1 # pe med eventuellt tecken l 1 äpple 2 päron $ grep "s. * r" text1 # p, i rader som innehåller r 2 päron $ grep "a .." text1 # rader med a följt av minst 2 tecken 1 äpple 3 banan $ grep "\ (en \) \ +" text1 # Sök efter fler repetitioner en 3 banan $ grep "an \ (an \) \ +" text1 # sök efter 2 repetitioner en 3 banan $ grep "" text1 # sökrader med 3 eller p 1 äpple 2 päron 3 banan $ echo -e "hitta en \ n * här \ n någonstans." | grep "[. *]" * här någonstans. $ # Söker efter tecken 3 till 7 $ echo -e "123 \ n456 \ n789 \ n0" | grep "" 123 456 789 $ # Letar efter en siffra utan bokstäverna n och r till slutet av raden $ grep "[[: siffra:]] [^ nr] * $" text1 1 apple $ sed -e "/ \ (a . * a \) \ | \ (s. * p \) / s / a / A / g "text1 # ersätt a med A på alla rader där a kommer efter a eller p kommer efter p 1 Äpple 2 päron 3 bAnAnA $ sed -e "/ ^ [^ lmnXYZ] * $ / s / öra / varje / g" text1 # ersätt öra med varje på rader som inte börjar med lmnXYZ 1 äpple 2 persika 3 banan $ echo "Först. En fras. Detta är en mening." | \ # Ersätt det sista ordet i en mening med LAST WORLD. > sed -e "s / [^] * \ ./ SISTA ORD./g" Först. ETT SISTA ORD. Detta är ett SISTA ORD.
Bakgrund och källa: inte alla som måste använda reguljära uttryck förstår helt hur de fungerar och hur man skapar dem. Jag tillhörde också denna grupp - jag letade efter exempel på reguljära uttryck som passade mina uppgifter, försökte korrigera dem vid behov. För mig förändrades allt radikalt efter att ha läst boken. Linux Command Line (Andra Internet Edition) författaren William E. Shotts, Jr. I den anges principerna för arbetet med reguljära uttryck så tydligt att jag efter att ha läst lärt mig att förstå dem, skapa reguljära uttryck av vilken komplexitet som helst och nu använder jag dem när det behövs. Detta material är en översättning av den del av kapitlet som ägnas åt reguljära uttryck. Detta material är avsett för absoluta nybörjare som inte alls förstår hur reguljära uttryck fungerar, men som har en aning om hur de fungerar. Förhoppningsvis hjälper den här artikeln dig att göra samma genombrott som hjälpte mig. Om materialet som beskrivs här inte är nytt för dig, prova artikeln Regular Expressions och grep-kommandot för mer information om grep-alternativ och ytterligare exempel.
Hur reguljära uttryck används
Textdata spelar en viktig roll i alla Unix-liknande system som Linux. Texten är bland annat utdata av konsolprogram, och konfigurationsfiler, rapporter m.m. Vanliga uttryckär (kanske) ett av de svåraste begreppen för att arbeta med text, eftersom de innebär en hög abstraktionsnivå. Men tiden för att studera dem kommer att löna sig med ränta. Att veta hur man använder reguljära uttryck kan hjälpa dig att göra fantastiska saker, även om deras fulla värde kanske inte är direkt uppenbart.
Den här artikeln kommer att leda dig genom användningen av reguljära uttryck i kombination med kommandot grep... Men deras tillämpning är inte begränsad bara till detta: reguljära uttryck stöds av andra Linux-kommandon, många programmeringsspråk, de används i konfigurationen (till exempel i inställningarna för mod_rewrite-regler i Apache), och även vissa GUI-program låter dig ange regler för sökning / kopiera / ta bort från stöd för reguljära uttryck. Även i det populära kontorsprogrammet Microsoft Word kan du använda reguljära uttryck och jokertecken för att hitta och ersätta text.
Vad är reguljära uttryck?
Enkelt uttryckt är ett reguljärt uttryck en stenografi, en symbolisk notation för ett mönster som man söker efter i en text. Reguljära uttryck stöds av många kommandoradsverktyg och de flesta programmeringsspråk och används för att hjälpa dig att lösa textmanipuleringsproblem. Men (som om deras komplexitet inte räcker för oss) är inte alla reguljära uttryck desamma. De varierar något från verktyg till verktyg och från programmeringsspråk till språk. För vår diskussion kommer vi att begränsa oss till de reguljära uttryck som beskrivs i POSIX-standarden (som kommer att täcka de flesta kommandoradsverktyg), i motsats till många programmeringsspråk (främst Perl) som använder lite större och rikare uppsättningar notationer.
grep
Huvudprogrammet vi kommer att använda för reguljära uttryck är vår gamla vän. Namnet "grep" kommer faktiskt från frasen "global reguljärt uttryck print", så vi kan se att grep har något att göra med reguljära uttryck. I huvudsak söker grep i textfiler efter text som matchar det angivna regexp och skriver ut valfri rad som innehåller matchningen till standardutdata.
grep kan söka efter text mottagen i standardinmatning, till exempel:
Ls / usr / bin | grep zip
Detta kommando listar filerna i katalogen / usr / bin vars namn innehåller delsträngen "zip".
Grep kan söka efter text i filer.
Syntax för allmän användning:
Grep [alternativ] regex [fil ...]
- regexär ett reguljärt uttryck.
- [fil…]- en eller flera filer där sökningen med reguljära uttryck kommer att utföras.
[alternativ] och [fil ...] kan saknas.
En lista över de vanligaste grep-alternativen:
| Alternativ | Beskrivning |
|---|---|
| -jag | Ignorera fall. Gör ingen skillnad mellan stora och små tecken. Den kan också ställas in med alternativet --ignorera fall. |
| -v | Invertera match. Vanligtvis skriver grep ut rader som innehåller en matchning. Det här alternativet gör att grep skriver ut varje rad som inte matchar. Du kan också använda --invertera-match. |
| -c | Skriv ut antalet matchningar (eller felmatchningar om alternativet anges -v) istället för själva strängarna. Kan även specificeras med optionen --räkna. |
| -l | Istället för själva raderna, skriv ut namnet på varje fil som innehåller matchningen. Kan specificeras med tillval --filer-med-matchningar. |
| -L | Som ett alternativ -l men skriver bara ut filnamn som inte innehåller matchningar. Ett annat alternativnamn --filer-utan matchning. |
| -n | Lägger till ett radnummer i filen i början av varje matchad rad. Ett annat alternativnamn --linje nummer. |
| -h | För att söka i flera filer, dämpa utmatningen av filnamnet. Du kan också ange alternativet --inget-filnamn. |
För att utforska grep mer fullständigt, låt oss skapa några textfiler att söka efter:
Ls / bin> dirlist-bin.txt ls / usr / bin> dirlist-usr-bin.txt ls / sbin> dirlist-sbin.txt ls / usr / sbin> dirlist-usr-sbin.txt ls dirlist * .txt dirlist -bin.txt dirlist-sbin.txt dirlist-usr-bin.txt dirlist-usr-sbin.txt
Vi kan göra en enkel sökning genom vår lista med filer så här:
Grep bzip dirlist * .txt dirlist-bin.txt: bzip2 dirlist-bin.txt: bzip2recover
I det här exemplet söker grep alla listade filer efter bzip-strängen och hittar två matchningar, båda i filen dirlist-bin.txt. Om vi bara är intresserade av listan över filer som innehåller matchningar, och inte de matchande raderna i sig, kan vi ange alternativet -l:
Grep -l bzip dirlist * .txt dirlist-bin.txt
Omvänt, om vi bara ville se en lista över filer som inte innehöll matchningar, kunde vi göra så här:
Grep -L bzip dirlist * .txt dirlist-sbin.txt dirlist-usr-bin.txt dirlist-usr-sbin.txt
Om det inte finns någon utdata hittades inte filerna som matchar villkoren.
Metatecken och bokstaver
Även om detta kanske inte verkar självklart, använder våra grep-sökningar alltid reguljära uttryck, om än mycket enkla. Det reguljära uttrycket "bzip" betyder att en matchning kommer att inträffa (det vill säga att strängen anses lämplig) endast om raden i filen innehåller minst fyra tecken och att det någonstans i strängen finns tecknen "b", "z " , "I" och "p" är i den ordningen, utan några andra tecken emellan. Tecknen i "bzip"-strängen är bokstavliga ord, dvs. bokstavliga symboler som de motsvarar dem själva. Förutom bokstavliga ord kan reguljära uttryck även inkludera metatecken som används för att specificera mer komplexa matchningar. Reguljära uttrycksmetakaraktärer består av följande:
^ $ . { } - ? * + () | \Alla andra karaktärer anses vara bokstavliga. Omvänt snedstreck kan ha olika betydelser. Den används i flera fall för att skapa metasekvenser och tillåter också att metakaraktärer undkomms och behandlas som bokstavliga snarare än metakarakterer.
Notera: som vi kan se är många av regex-metakaraktärerna också skal-meningsfulla (utför expansion) karaktärer. När du anger ett reguljärt uttryck som innehåller kommandoradsmetatecken, är det absolut nödvändigt att du anger det inom citattecken, annars kommer skalet att tolka dem annorlunda och bryta ditt kommando.
Vilken karaktär som helst
Den första metakaraktären som vi börjar bekanta oss med är pricksymbol vilket betyder "vilken karaktär som helst". Om vi inkluderar det i regexet kommer det att matcha vilket tecken som helst för den karaktärspositionen. Exempel:
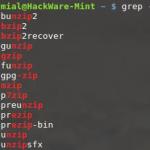
Grep -h ".zip" dirlist * .txt bunzip2 bzip2 bzip2recover gunzip gzip funzip gpg-zip mzip p7zip preunzip prezip prezip-bin unzip unzipsfx

Vi letade efter valfri rad i våra filer som matchar det reguljära uttrycket ".zip". Ett par intressanta punkter bör noteras i de erhållna resultaten. Observera att zip-programmet inte hittades. Detta beror på att inkludering av punktmetatecken i vårt reguljära uttryck ökade längden som krävs för att matcha till fyra tecken, och eftersom namnet "zip" bara innehåller tre matchar det inte. Dessutom, om någon av filerna på våra listor innehöll filtillägget .zip, skulle de också anses vara giltiga, eftersom punkttecknet i filtillägget också matchar villkoret "alla tecken".
Ankare
Caret karaktären ( ^ ) och dollartecken ( $ ) beaktas i reguljära uttryck ankare... Det betyder att de bara matchar om det regex finns i början av raden ( ^ ) eller i slutet av raden ( $ ):
Grep -h "^ zip" dirlist * .txt zip zipcloak zipdetails zipgrep zipinfo zipnote zipsplit grep -h "zip $" dirlist * .txt gunzip gzip funzip gpg-zip mzip p7zip preunzip prezip prezip packa upp zip grep-$ " * .txt zip

Här tittade vi igenom fillistorna efter "zip"-strängen som finns i början av raden, i slutet av raden, såväl som på raden där den skulle vara både i början och slutet (det vill säga, hela raden skulle bara innehålla "zip" ). Observera att det reguljära uttrycket " ^$ "(Början och slutet mellan vilka det inte finns något) kommer att matcha tomma rader.
En liten lyrisk utvikning: assistent för att lösa korsord
Även med vår för närvarande begränsade kunskap om reguljära uttryck kan vi göra något användbart.
Om du någonsin har löst korsord, då var du tvungen att lösa problem som "vilket fembokstavsord, där den tredje bokstaven är" j ", och den sista bokstaven är" r ", vilket betyder ...". Denna fråga kan vara tankeväckande. Visste du att Linux har en ordbok? Och han är. Titta i / usr / share / dict katalogen, där kan du hitta en eller flera ordböcker. Ordböckerna som publiceras där är bara långa listor med ord, en per rad, ordnade i alfabetisk ordning. På mitt system innehåller ordboksfilen 99 171 ord. För att söka efter möjliga svar på ovanstående korsordsfråga kan vi göra så här:
Grep -i "^ .. j.r $" / usr / share / dict / amerikansk-engelska Major major
Med detta regex kan vi hitta alla ord i vår ordboksfil som är fem bokstäver långa, har "j" i tredje positionen och "r" i sista positionen.
I exemplet användes en engelsk ordboksfil eftersom den finns på systemet som standard. Efter att tidigare ha laddat ner motsvarande ordbok kan du göra liknande sökningar med ord på kyrilliska eller från andra tecken.
Uttryck för parentes och karaktärsklasser
Förutom att matcha vilket tecken som helst på en given position i vårt regex använder vi också uttryck inom hakparenteser, kan vi matcha ett enstaka tecken från den angivna teckenuppsättningen. Med uttryck inom hakparenteser kan vi ange vilken teckenuppsättning som ska matcha (inklusive tecken som annars skulle tolkas som metatecken). I det här exemplet använder du en uppsättning av två tecken:
Grep -h "zip" dirlist * .txt bzip2 bzip2recover gzip
vi hittar alla rader som innehåller strängarna "bzip" eller "gzip".
En uppsättning kan innehålla valfritt antal tecken, och metatecken förlorar sin speciella betydelse när de placeras inom hakparenteser. Det finns dock två fall där metatecken som används inom hakparenteser har olika betydelser. Den första är careten ( ^ ), som används för att indikera negation; den andra är ett streck ( - ), som används för att ange ett antal tecken.
Negation
Om det första tecknet i uttrycket inom hakparenteser är en indikator ( ^ ), så accepteras resten av tecknen som en uppsättning tecken som inte ska finnas i den givna teckenpositionen. Låt oss göra detta genom att modifiera vårt tidigare exempel:
Grep -h "[^ bg] zip" dirlist * .txt bunzip2 gunzip funzip gpg-zip mzip p7zip preunzip prezip prezip-bin unzip unzipsfx

Med negation aktiverad fick vi en lista över filer som innehåller strängen "zip" föregås av vilket tecken som helst förutom "b" eller "g". Observera att dragkedjan inte hittades. Den negerade teckenuppsättningen kräver fortfarande tecknet på den givna positionen, men tecknet får inte vara en del av den inverterade teckenuppsättningen.
Ett vagntecken förnekas endast om det är det första tecknet inom ett uttryck inom parentes; annars förlorar den sitt speciella syfte och blir en vanlig karaktär från uppsättningen.
Traditionella teckenintervall
Om vi vill konstruera ett reguljärt uttryck som måste hitta varje fil i vår lista som börjar med en stor bokstav, kan vi göra följande:
Grep -h "^" dirlist * .txt MAKEDEV GET HEAD POST VBoxClient X X11 Xorg ModemManager NetworkManager VBoxControl VBoxService
Summan av kardemumman är att vi har placerat alla 26 versaler i uttrycket inom hakparenteser. Men tanken på att skriva ut dem alla är inte entusiastisk, så det finns ett annat sätt:
Grep -h "^" dirlist * .txt

Genom att använda ett intervall på 3 tecken kan vi förkorta en post på 26 bokstäver. Alla teckenintervall kan uttryckas på detta sätt, inklusive flera intervall samtidigt, till exempel detta uttryck, som matchar alla filnamn som börjar med bokstäver och siffror:
Grep -h "^" dirlist * .txt
I teckenintervall ser vi att bindestrecket behandlas på ett speciellt sätt, så hur kan vi inkludera bindestrecket i uttrycket inom hakparenteserna? Genom att göra det till det första tecknet i uttrycket. Låt oss titta på två exempel:
Grep -h "" dirlist * .txt
Detta kommer att matcha alla filnamn som innehåller en stor bokstav. Vart i:
Grep -h "[-AZ]" dirlist * .txt
kommer att matcha alla filnamn som innehåller ett bindestreck eller ett versaler "A" eller ett versalt "Z".
Reguljära uttryck är ett mycket kraftfullt verktyg för mönstermatchning, manipulering och modifiering av strängar som kan användas för en mängd olika uppgifter. Här är de viktigaste:
- Kontrollera textinmatning;
- Sök och ersätt text i en fil;
- Batch byta namn på filer;
- Interaktion med tjänster som Apache;
- Kontrollera ett snöre mot ett mönster.
Det här är inte en komplett lista, det finns mycket mer du kan göra med reguljära uttryck. Men för nya användare kan de verka för komplicerade, eftersom ett speciellt språk används för att bilda dem. Men med tanke på de möjligheter som det ger, bör Linux reguljära uttryck vara kända och användas av varje systemadministratör.
I den här artikeln går vi igenom bash reguljära uttryck för nybörjare så att du kan förstå alla funktioner i det här verktyget.
Det finns två typer av tecken som kan användas i reguljära uttryck:
- vanliga bokstäver;
- metatecken.
Vanliga tecken är bokstäver, siffror och skiljetecken som utgör vilken sträng som helst. Alla texter är sammansatta av bokstäver och du kan använda dem i reguljära uttryck för att hitta önskad position i texten.
Metakaraktärer är något annat, de är det som ger kraft åt reguljära uttryck. Med metatecken kan du göra mycket mer än att söka efter ett enda tecken. Du kan söka efter kombinationer av tecken, använda ett dynamiskt antal tecken och välja intervall. Alla specialtecken kan delas in i två typer, det är ersättningstecken som ersätter vanliga tecken, eller operatorer som anger hur många gånger ett tecken kan upprepas. Syntaxen för reguljära uttryck kommer att se ut så här:
vanlig_karaktär special character_operator
special_replacement_character special character_operator
- - bokstavliga specialtecken börjar med ett snedstreck, och det används också om du behöver använda ett specialtecken i form av ett skiljetecken;
- ^ - indikerar början av raden;
- $ - indikerar slutet av raden;
- * - indikerar att föregående tecken kan upprepas 0 eller fler gånger;
- + - indikerar att det föregående tecknet ska upprepas mer än en eller flera gånger;
- ? - det föregående tecknet kan förekomma noll eller en gång;
- (n)- indikerar hur många gånger (n) som ska upprepas föregående tecken;
- (N, n)- det föregående tecknet kan upprepas från N till n gånger;
- . - vilket tecken som helst utom radmatning;
- - alla tecken som anges inom parentes;
- x | y- symbol x eller symbol y;
- [^ az]- alla andra tecken än de som anges inom parentes;
- - valfritt tecken från det angivna intervallet;
- [^ a-z]- alla tecken som inte finns i intervallet;
- b- betecknar en ordgräns med ett mellanslag;
- B- betyder att tecknet måste finnas i ett ord, till exempel, ux matchar uxb eller smoking, men matchar inte Linux;
- d- betyder att symbolen är en siffra;
- D- icke-digitala tecken;
- n- radmatningskaraktär;
- s- ett av tecknen mellanslag, mellanslag, tab, och så vidare;
- S- vilket tecken som helst utom ett mellanslag;
- t- tabellkaraktär;
- v- vertikal tab-tecken;
- w- alla alfabetiska tecken, inklusive understreck;
- W- alla alfabetiska tecken utom understreck;
- uXXX- Unicdoe-symbol.
Det är viktigt att notera att ett snedstreck måste användas före de bokstavliga specialtecknen för att indikera att specialtecknet är nästa. Motsatsen är också sant, om du vill använda ett specialtecken som används utan snedstreck som ett vanligt tecken, så måste du lägga till ett snedstreck.
Du vill till exempel söka efter raden 1+ 2 = 3 i texten. Om du använder den här strängen som ett reguljärt uttryck hittar du inget, eftersom systemet tolkar plustecknet som ett specialtecken som säger att föregående enhet ska upprepas en eller flera gånger. Så det måste escapes: 1 + 2 = 3. Utan escape, skulle vårt regex bara matcha strängen 11 = 3 eller 111 = 3, och så vidare. Du behöver inte sätta en rad före lika, eftersom det inte är ett specialtecken.
Exempel på användning av reguljära uttryck
Nu när vi har täckt grunderna och du vet hur allt fungerar, återstår det att konsolidera kunskapen om linux grep reguljära uttryck i praktiken. Två mycket användbara specialtecken är ^ och $, som anger början och slutet av en rad. Vi vill till exempel få alla användare registrerade i vårt system vars namn börjar med s. Sedan kan det reguljära uttrycket tillämpas "^ S"... Du kan använda kommandot egrep:
egrep "^ s" / etc / passwd
Om vi vill välja rader efter det sista tecknet på raden kan vi använda $ för detta. Låt oss till exempel välja alla systemanvändare, inget skal, poster om sådana användare slutar med false:
egrep "false $" / etc / passwd
För att visa användarnamn som börjar med s eller d, använd ett uttryck så här:
egrep "^" / etc / passwd
Samma resultat kan erhållas genom att använda tecknet "|". Det första alternativet är mer lämpligt för intervall, och det andra används oftare för vanliga eller / eller:
egrep "^" / etc / passwd
Låt oss nu välja alla användare vars namn är mer än tre tecken. Användarnamnet slutar med ett kolon. Vi kan säga att det kan innehålla alla alfabetiska tecken, som måste upprepas tre gånger, före kolon:
egrep "^ w (3):" / etc / passwd
Slutsatser
Vi har täckt Linux reguljära uttryck i den här artikeln, men det var bara grunderna. Om du gräver lite djupare kommer du att upptäcka att det finns mycket mer intressanta saker du kan göra med det här verktyget. Den tid som ägnas åt att lära sig reguljära uttryck kommer definitivt att vara värt det.
Som avslutning, en föreläsning från Yandex om reguljära uttryck:
Vanligt uttryck- ett textmönster som består av en kombination av bokstäver, siffror och specialtecken, så kallade metatecken. En nära kusin till reguljära uttryck är jokerteckenuttryck som vanligtvis används i filhantering. Reguljära uttryck används främst för textjämförelse och sökning. Används flitigt för att analysera syntax.
UNIX-användare är bekanta med reguljära uttryck från grep, sed, awk (eller gawk) och ed. Med hjälp av dessa program eller deras analoger kan du försöka verifiera exemplen nedan. Textredigerare som (X) Emacs och vi använder också mycket reguljära uttryck. Den kanske mest kända och bredaste användningen av reguljära uttryck förekommer i Perl-språket. Det är svårt för en mjukvaruutvecklare och systemadministratör att klara sig utan kunskap om reguljära uttryck.
Metakaraktärer
Strängar kan alltså bestå av bokstäver, siffror och metatecken. Metatecken är:
\ | () { } ^ $ * + ? . < >
Metatecken kan spela följande roller i ett reguljärt uttryck:
kvantifierare
påstående;
grupptecken;
alternativ;
sekvens tecken
Kvantifierare
Metatecken * (asterisk) ersätter 0 eller fler tecken. Metatecken + (plus) ersätter 1 eller fler tecken. Metakaraktär. (punkt) ersätter exakt 1 godtyckligt tecken. Metkaraktär? (frågetecken) ersätter 0 eller 1 tecken. Skillnaden i användningen av * och + är sådan att en fråga för att hitta en sträng med * kommer att returnera alla strängar, inklusive tomma, och en fråga med + endast resulterar i strängar som innehåller tecknet c.
Tomma rader följer följande konventioner: En tom rad innehåller en och endast en tom rad; en icke-tom rad innehåller tomma rader före varje tecken och även i slutet av raden.
Reguljära uttryck använder också konstruktionen (n, m), vilket innebär att tecknet före konstruktionen förekommer n till m gånger i strängen. Att utelämna talet m betyder oändlighet. De där. specialfall av konstruktionen är följande poster: (0,), (1,) och (0,1). Den första matchar *, den andra matchar metatecken + och den tredje matchar? ... Dessa likheter är lätta att erhålla från definitionen av motsvarande kvantifierare. Dessutom innebär konstruktionen (n) att symbolen förekommer exakt n gånger.
I samband med användningen av några skiljetecken och matematiska symboler som metatecken har ytterligare ett metatecken \ (omvänt snedstreck, snedstreck) införts, som när det skrivs före metateckenet förvandlar det senare till ett vanligt tecken. De där. ? är en kvantifierare och \? - frågetecken.
Grupper
De ovan beskrivna kvantifierarna verkar, som redan nämnts, på tecknet närmast dem till vänster (den sista föregående). Men denna begränsning gör att du kan kringgå grupperna i vars beteckning metatecken (och) används. Dessa tecken extraherar ett underuttryck från ett uttryck, som sedan kombineras till en grupp, på vilken en kvantifierare sedan tillämpas.
Exempel:
betyder (eller ersätter)
Ho ho ho ho ho ho ho hoho
Kapsling av deluttryck är möjlig, d.v.s. kortare deluttryck kan extraheras från ett deluttryck.
Alternativ
Bildas med hjälp av metatecken | (vertikal stapel) som anger ett logiskt "eller".
Exempel: kor med reguljära uttryck (a | s | e | y | oops | oyu)? anger alla möjliga deklinationer av ordet "ko" i singular för kasus.
Påståenden
Metatecken är markerade, som betecknar speciella objekt - nolllängdssträngar som används för att bestämma platsen för texten som föregår eller följer dem. Sådana objekt kallas uttalanden. Följande påståenden finns i reguljära uttryck:
^ början av raden $ slutet av raden< начало слова >slutet av ordetExempel: det reguljära uttrycket $ The matchar strängen som börjar med The.
Obs: Vanliga tecken kan ses som påståenden som inte är lika långa.
Sekvenser
En speciell konstruktion, innesluten i [och] metatecken (hakparenteser), låter dig lista de varianter av tecken som kan förekomma i det reguljära uttrycket på en given plats, och kallas en sekvens. Inom hakparenteser behandlas alla metatecken som enkla symboler, och symboler - (minus) och ^ får nya betydelser: den första låter dig specificera en kontinuerlig sekvens av tecken mellan de två angivna, och den andra ger ett logiskt "inte" ( negation). De enklaste exemplen att överväga är:
någon av de små latinska bokstäverna:
latinska alfanumeriska tecken (a till z, A till Ö och 0 till 9):
icke-latinska alfanumeriska tecken:
[^ a-zA-Z0-9]
vilket ord som helst (utan bindestreck, matematiska symboler och siffror):
<+>
För korthet och enkelhet introduceras följande förkortningar:
\ d en siffra (dvs matchar ett uttryck); \ D är inte en siffra (dvs [^ 0-9]); \ w latinskt ord (alfanumeriskt); \ W är en sekvens av tecken utan mellanslag som inte är ett latinskt alfanumeriskt ord ([^ a-zA-Z0-9]); \ s tomt utrymme [\ t \ n \ r \ f], dvs mellanslag, flikar osv. \ S är ett icke-tomt spann ([^ \ t \ n \ r \ f]).Förhållande med jokertecken
Varje användare är förmodligen bekant med jokertecken. Ett exempel på ett jokerteckenuttryck är * .jpg, som anger alla filer med filtillägget jpg. Hur skiljer sig reguljära uttryck från jokertecken? Skillnaderna kan sammanfattas i tre regler för att konvertera ett godtyckligt jokerteckenuttryck till ett reguljärt uttryck:
Ersatt av.*
Byta ut? på.
Byt ut alla karaktärer som matchar metakaraktärer med deras omvänt snedstreckade varianter.
I ett reguljärt uttryck är det faktiskt meningslöst att skriva * och ger en tom sträng, eftersom betyder att den tomma strängen upprepas hur många gånger som helst. Och här: * (Upprepa ett godtyckligt tecken så många gånger du vill, inklusive 0) sammanfaller exakt i betydelse med tecknet * i uppsättningen jokertecken.
Det reguljära uttrycket som matchar * .jpg kommer att se ut så här: * \. Jpg. Till exempel matchar jokerteckensekvenserna ez * .pp två ekvivalenta reguljära uttryck, ez. * \. Pp och ez. * \. (Cpp | hpp).
Exempel på reguljära uttryck
E-post i formatet [e-postskyddad]
+(\.+)*@+(\.+)+
E-post i formatet "Ivan Ivanov
("? +"? [\ t] *) + \<+(\.+)*@+(\.+)+\>
Kontrollera webbprotokollet i URL:en (http: //, ftp: // eller https: //)
+://
Vissa C / C ++ kommandon och direktiv:
^ # inkluderar [\ t] + [<"][^>"] + [">] - inkluderar direktiv
//.+$ - kommentar på en rad
/ \ * [^ *] * \ * / - kommentera flera rader
-? + \. + - flyttalnummer
0x + är ett hexadecimalt tal.
Och här, till exempel, programmet för att hitta ordet ko:
grep -E "ko | vache" *> / dev / null && echo "Hittade en ko"Här används alternativet -E för att aktivera utökat syntaxstöd för reguljära uttryck.
Denna text är baserad på en artikel av Jan Borsodi från filen HOWTO-regexps.htm
Ett kontinuerligt uttryck är ett mönster som beskriver en uppsättning strängar. Reguljära uttryck är konstruerade på samma sätt som aritmetiska uttryck, med olika operatorer för att kombinera mindre uttryck.
Kontinuerliga uttryck (engelska reguljära uttryck, förkortat RegExp, RegEx, jarg. Regexps eller regexes) är ett system för att analysera textfragment enligt en formaliserad mall, baserat på systemet med skrivmönster för sökning. Mönstret definierar sökregeln, på ryska klickas det också ibland på "mönster", "mask". Reguljära uttryck fick ett genombrott inom elektronisk innehållsbehandling i slutet av 1900-talet. De representeras av utvecklingen av jokertecken.
Konstanta uttryck används nu av många textredigerare och verktyg för att hitta och ändra text baserat på utvalda regler. Nästan många programmeringsspråk stöder reguljära uttryck för att manipulera strängar. Till exempel har Java, .NET Framework, Perl, PHP, JavaScript, Python och andra inbyggt stöd för konstanta uttryck. En uppsättning verktyg (inklusive sed-editorn och grep-filtret) som av UNIX-distributioner anses vara ett av de ursprungliga hjälpte till att popularisera konceptet med reguljära uttryck.
Ett av de mer användbara och funktionsrika kommandona i Linux-terminalen är "grep"-brigaden. Grep är en akronym som står för "globalt reguljärt uttryck print" (det vill säga "sök överallt efter strängar som motsvarar ett konstant uttryck och skriv ut dem").
Det betyder att du kan använda grep för att se om din inmatning matchar ett givet mönster. I sin enklaste form används grep för att hitta matchningar för bokstavsmönster i en textfil. Detta betyder att om grep skaffar ett sökord, kommer det att skriva ut varje rad i filen som lagrar det ordet.
Syftet med grep är att söka efter strängar enligt ett reguljärt uttrycksvillkor. Det finns ändringar i det klassiska grepet - egrep, fgrep, rgrep. Alla är finjusterade för specifika ändamål, medan greps funktioner täcker all funktionalitet. Det enklaste exemplet på att använda ett kommando är att mata ut en sträng som matchar ett mönster från en fil. Exempel vi vill hitta raden som lagrar 'användare' i filen /etc/mysql/my.cnf. För att göra detta kommer vi att använda följande kommando:
Grep-användare /etc/mysql/my.cnf
Grep kan helt enkelt söka efter ett specifikt ord:
Grep Hej ./example.cpp
Eller en sträng, men i det här fallet måste den omges av citattecken:
Grep "Hello world" ./example.cpp
Dessutom är alternativen till programmet egrep och fgrep, som är samma som grep -E respektive grep -F. Alternativen egrep och fgrep är föråldrade, men fungerar för bakåtkompatibilitet. Det rekommenderas att använda grep -E och grep -F istället för de föråldrade alternativen.
Kommandot grep matchar källfilernas rader mot ett mönster, detta grundläggande reguljära uttryck. Om inga filer anges används standardinmatning. Som vanligt kopieras varje framgångsrikt matchad rad till standardutdata; om
källfilerna lite innan den hittade raden får filnamnet. Grundläggande kontinuerliga uttryck (uttryck som har teckensträngar som sin betydelse och använder en begränsad uppsättning alfanumeriska och specialtecken) accepteras som mallar.
Använder egrep i Linux
Egrep eller grep -E är en annan version av grep eller Extended grep. Den här versionen av grep är utmärkt och snabb när det gäller att söka efter ett regexmönster, eftersom den behandlar metatecken som de är och inte ersätter dem som strängar. Egrep använder ERE eller Extended Extended Expression.
egrep är ett avskalat anrop till grep med -E-växeln. Det skiljer sig från grep i förmågan att använda utökade kontinuerliga uttryck med POSIX-teckenklasser. Problemet uppstår ofta med att hitta ord eller representationer som tillhör samma typ, men med möjliga variationer i stavningen, såsom datum, filnamn med viss filändelse och standardnamn, e-postadresser. Å andra sidan finns det uppgifter för att hitta väldefinierade ord som kan ha olika former, eller en sökning som utesluter enskilda tecken eller klasser av tecken.
För dessa sanningsändamål har vissa system skapats baserat på beskrivningen av text med hjälp av mallar. Konstanta uttryck rankas också bland sådana system. Två mycket användbara specialtecken är ^ och $, som anger början och slutet av en rad. Vi vill till exempel få alla användare registrerade i vårt system vars namn börjar med s. Sedan kan det reguljära uttrycket "^ s" användas. Du kan använda egrep-brigaden:
Egrep "^ s" / etc / passwd
Det är möjligt att söka igenom flera filer och i så fall visas filnamnet framför raden.
Egrep -i Hej ./example.cpp ./example2.cpp
Och följande fråga visar all kod, exklusive rader som endast innehåller kommentarer:
Egrep -v ^ / ./example.cpp
Som egrep, även om du inte undviker metatecken, kommer kommandot att behandla dem som specialtecken och ersätta dem med deras speciella betydelse istället för att behandla dem som en del av en sträng.
Använder fgrep på Linux
Fgrep eller Fixed grep eller grep -F är en annan version av grep som behövs när det gäller att söka på en hel rad istället för ett vanligt koncept, eftersom det inte känner igen reguljära uttryck eller metatecken. För att söka efter en rad direkt, välj den här versionen av grep.
Fgrep letar efter en komplett sträng och känner inte igen specialtecken som en del av ett kontinuerligt uttryck, oavsett om tecknen är escaped eller inte.
Fgrep -C 0 "(f | g) ile" check_file fgrep -C 0 "\ (f \ | g \) ile" check_file
Använder sed på Linux
sed (från engelska Stream Editor) är en strömmande textredigerare (liksom ett programmeringsspråk) som använder olika fördefinierade texttransformationer till en sekventiell ström av text. Sed kan kasseras som grep, som matar ut rader som följer mönstret av ett grundläggande regex:
Sed -n / Hej / p ./example.cpp
Kan användas för att ta bort rader (ta bort alla tomma rader):
Sed / ^ $ / d ./example.cpp
Huvudverktyget för att arbeta med sed är ett uttryck som:
Sed s / lookup_expression / what_replace / filnamn
Så, ett exempel, om du kör kommandot:
Sed s / int / long / ./example.cpp
Skillnaderna mellan "grep", "egrep" och "fgrep" diskuteras ovan. Oavsett skillnaderna i uppsättningen av vanliga representationer som används och exekveringshastigheten förblir kommandoradsalternativen desamma för alla tre versioner av grep.