В днешната статия искам да засегна такава огромна тема като Регулярни изрази... Мисля, че всеки знае, че темата за регулярните изрази (както регулярните изрази се наричат на жаргон) е огромна в обема на една публикация.
Като начало има няколко вида регулярни изрази:
1. Традиционни регулярни изрази(те също са основни, основни и основни регулярни изрази(BRE))
- синтаксисът за тези изрази е дефиниран като остарял, но въпреки това все още е широко разпространен и използван от много помощни програми на UNIX
- Основните регулярни изрази включват следните метасимволи (вижте значенията им по-долу):
- \ (\) - оригинал за () (разширено)
- \ (\) - оригинал за () (разширено)
- \н, където н- номер от 1 до 9
- Характеристики на използването на тези метазнаци:
- След израза, който съответства на един знак, трябва да има звездичка. Пример: *.
- Израз \( блок\) * трябва да се счита за невалиден. В някои случаи съответства на нула или повече повторения на низа. блок... В други съвпада с низа блок* .
- В рамките на клас символи, специалните знаци обикновено се игнорират. Специални случаи:
- За да добавите знак ^ към набор, той не трябва да се поставя първи там.
- За да добавите символ - към набор, той трябва да бъде поставен там първи или последен. Например:
- Шаблон на DNS име, който може да включва букви, цифри, минус и разделителна точка: [-0-9a-zA-Z.];
- всеки знак с изключение на минус и цифра: [^ -0-9].
- За да добавите знака [или] към набора, той трябва да бъде поставен първо там. Например:
- съвпадения], [, a или b.
2. Разширени регулярни изрази(те са разширени регулярни изрази(ERE))
- Синтаксисът за тези изрази е същият като за основните изрази, с изключение на:
- Премахнато е използването на обратна наклонена черта за метасимволите () и ().
- Обратната наклонена черта пред метазнака отменя специалното му значение.
- Отхвърлено теоретично нередовенстроителство \ н .
- Добавени са метазнаците +,? , | ...
3. Perl съвместими регулярни изрази(те са Perl-съвместими регулярни изрази(PCRE))
- имат по-богат и в същото време предсказуем синтаксис дори от POSIX ERE, поради което често се използва от приложения.
Регулярни изрази се състои отшаблони, или по-скоро задайте моделТърсене. Шаблонът се състоиот правилатърсения, които се състоят от символии метазнаци.
Правила за търсенедефинирани от следното операции:
Изброяване |
Вертикална лента (|)разделя валидните опции, можем да кажем – логическо ИЛИ. Например „сиво | сиво“ съвпада сивоили сиво.
Групиране или обединение ()
Кръгли скобисе използват за определяне на обхвата и приоритета на операторите. Например, "сиво | сиво" и "gr (a | e) y" са различни модели, но и двете описват набор, съдържащ сивои сиво.
Количествено определяне ()? * +
Кванторслед знак или група определя колко пъти предиможе да се появи израз.
общ израз, повторенията могат да бъдат от m до n включително.
общ израз, m или повече повторения.
общ израз, не повече от n повторения.
гладкаn повторения.
Въпросителен знакозначава 0 или 1пъти, същото като {0,1} ... Например, "colou? R" съвпада и цвят, и цвят.
звездаозначава 0, 1 или произволно числоведнъж ( {0,} ). Например "go * gle" съвпада ggle, очила, googleи т.н.
Плюсозначава поне 1веднъж ( {1,} ). Например "go + gle" съвпада очила, googleи др. (но не ggle).
Специфичният синтаксис за тези регулярни изрази зависи от реализацията. (тоест в основни регулярни изразисимволи ( и )- избяга с обратна наклонена черта)
Метазнаци, по-просто казано, това са символи, които не отговарят на реалното им значение, тоест символ. (точка) не е точка, а всеки един знак и т.н. моля, запознайте се с метазнаците и техните значения:
| . | съответства на единвсеки герой |
| [нещо] | Съобразява се с всеки единиченсимвол, затворен в скоби. В този случай: Знакът "-" се тълкува буквално само ако се намира непосредствено след отварящата или преди затварящата скоба: или [-abc]. В противен случай той обозначава диапазон от знаци. Например, съвпада с „a“, „b“ или „c“. съвпада с малки букви на латинската азбука. Тези обозначения могат и се комбинират: съвпадат с a, b, c, q, r, s, t, u, v, w, x, y, z. За да съвпаднат знаците "[" или "]", е достатъчно, че затварящата скоба е първият знак след началния знак: съвпада с "]", "[", "a" или "b". Ако стойността в квадратни скоби е предшествана от ^, тогава стойността на израза съвпада единичен знакизмежду тези които не са в скоби... Например, [^ abc] съответства на всеки знак, различен от "a", "b" или "c". [^ a-z] съответства на всеки знак, различен от малките букви на латиница. |
| ^ | Съвпада с началото на текста (или с началото на всеки ред, ако е режим на ред). |
| $ | Съвпада с края на текста (или края на който и да е ред, ако е в режим на линия). |
| \(\) или () | Декларира "маркиран подизраз" (групиран израз), който може да се използва по-късно (вижте следващия елемент: \ н). "Маркираният подизраз" също е "блок". За разлика от други оператори, този (в традиционния синтаксис) изисква обратна наклонена черта, в разширения и Perl \ - не е необходим. |
| \н | Където н- това е число от 1 до 9; съответства на н th маркиран подизраз (например (abcd) \ 0, тоест символите abcd са маркирани с нула). Тази конструкция е теоретично нередовен, не беше прието в разширения синтаксис на регулярен израз. |
| * |
Израз, затворен в "\ (" и "\)", последван от "*", трябва да се счита за невалиден. В някои случаи съвпада с нула или повече срещания на низа, който е затворен в скоби. В други съвпада с израза, затворен в скоби, като се има предвид знака "*". |
| \{х,г\} | Съвпада с последното ( предстоящото) до възникнал блок поне хи не повече гведнъж. Например „a \ (3,5 \)“ съвпада с „aaa“, „aaaa“ или „aaaaa“. За разлика от други оператори, този (в традиционния синтаксис) изисква обратна наклонена черта. |
| .* | Обозначаване на произволен брой от произволни знаци между две части на регулярен израз. |
Метазнаците ни помагат да използваме различни съвпадения. Но как да представите метазнак с обикновен знак, тоест знака [(квадратна скоба) със стойността на квадратната скоба? Просто:
- трябва да се предхожда ( щит) метазнак (. * + \? ()) обратна наклонена черта. Например \. или \[
За да се опрости дефиницията на някои набори от символи, те бяха комбинирани в т.нар. класове и категории символи. POSIX стандартизира декларирането на определени класове и категории символи, както е показано в следната таблица:
| POSIX клас | по същия начин | обозначаване |
| [: горен:] | главни букви | |
| [: нисък:] | малки букви | |
| [: алфа:] | главни и малки букви | |
| [: възпитаник:] | цифри, главни и малки букви | |
| [: цифра:] | числа | |
| [: xdigit:] | шестнадесетични цифри | |
| [: punct:] | [.,!?:…] | препинателни знаци |
| [: празно:] | [\ T] | пространство и TAB |
| [: пространство:] | [\ t \ n \ r \ f \ v] | пропускане на знаци |
| [: ctrl:] | контролни символи | |
| [: графика:] | [^ \ t \ n \ r \ f \ v] | печат на символи |
| [: печат:] | [^ \ t \ n \ r \ f \ v] | печат и пропускане на знаци |
В регулярния израз има такова нещо като:
Редовен израз на алчността
Ще се опитам да го опиша възможно най-ясно. Да приемем, че искаме да намерим всички HTML тагове в някакъв текст. След като локализирахме задачата, искаме да намерим стойностите, затворени между тях< и >, заедно със същите тези скоби. Но знаем, че етикетите са с различна дължина, а самите етикети са най-малко 50. Да ги изброим всички, затварянето им в метасимволи е твърде времеемка задача. Но ние знаем, че имаме израз * (звездичка с точка), който характеризира произволен брой от всякакви знаци в низа. Използвайки този израз, ще се опитаме да намерим в текста (
Така, Как да създадете ниво на RAID 10/50 на LSI MegaRAID контролер (валиден и за: Intel SRCU42x, Intel SRCS16):
) всички стойности между тях< и >... В резултат на това ВСИЧКИ редове ще съответстват на този израз. защо, защото регулярният израз е АЛЧЕН и се опитва да улови ВСЯКАКЪВ брой знаци между тях< и >, съответно, цялата линия, като се започне < p> Така че...и край ...> ще принадлежи на това правило!Дано това е пример за това какво е алчност. За да се отървете от тази алчност, можете да отидете по следния път:
- вземете предвид символите, несъответстващ на желания модел (например:<[^>] *> за горния случай)
- отървете се от алчността, като добавите дефиниция на неалчен квантор:
- *? - "не алчен" ("мързелив") еквивалент *
- +? - "не алчен" ("мързелив") еквивалент +
- (н,)? - "не алчен" ("мързелив") еквивалентно на (n,)
- . *? - "не алчен" ("мързелив") еквивалент. *
Искам да допълня всичко по-горе с разширения синтаксис на регулярен израз:
POSIX регулярните изрази са подобни на традиционния синтаксис на Unix, но с добавяне на някои метасимволи:
Плюспоказва, че предишенсимвол или групаможе да се повтори един или повече пъти... За разлика от звездичка, е необходимо поне едно повторение.
Въпросителен знакправи предишензнак или група по избор. С други думи, в съответния ред, то може да отсъства или присъствагладка единведнъж.
Вертикална лентаразделя алтернативни регулярни изрази. Един символ определя две алтернативи, но може да има повече от тях, достатъчно е да използвате повече вертикални ленти. Не забравяйте, че този оператор използва възможно най-голяма част от израза. Поради тази причина алтернативният оператор най-често се използва в скоби.
Използването на обратна наклонена черта също е премахнато: \ (... \) става (...) и \ (... \) става (...).
В края на публикацията ето няколко примера за използване на регулярни изрази:
$ cat text1 1 ябълка 2 круша 3 банан $ grep p text1 1 ябълка 2 круша $ grep грах text1 2 круша $ grep "p *" text1 1 ябълка 2 круша 3 банан $ grep "pp *" text1 1 ябълка 2 круша $ grep " x "text1 $ grep" x * "text1 1 ябълка 2 круша 3 банан $ котка text1 | grep "l \ | n" 1 ябълка 3 банан $ echo -e "намерете \ n * тук" | grep "\ *" * тук $ grep "pp \ +" text1 # редове, съдържащи едно p и 1 или повече p 1 ябълка $ grep "pl \? e" text1 1 ябълка 2 круша $ grep "pl \? e" text1 # pe с възможен знак l 1 ябълка 2 круша $ grep "p. * r" text1 # p, в редове, съдържащи r 2 круша $ grep "a .." text1 # редове с a последван от поне 2 знака 1 ябълка 3 банан $ grep "\ (an \) \ +" text1 # Търсене за повече повторения an 3 banana $ grep "an \ (an \) \ +" text1 # търсене за 2 повторения an 3 banana $ grep "" text1 # търсене на редове с 3 или p 1 ябълка 2 круша 3 банан $ echo -e "намерете \ n * тук \ nнякъде." | grep "[. *]" * тук някъде. $ # Търси символи от 3 до 7 $ echo -e "123 \ n456 \ n789 \ n0" | grep "" 123 456 789 $ # Търсим цифра, последвана от без букви n и r до края на реда $ grep "[[: цифра:]] [^ nr] * $" text1 1 ябълка $ sed -e "/ \ (a . * a \) \ | \ (p. * p \) / s / a / A / g "text1 # заменете a с A във всички редове, където a идва след a или p идва след p 1 ябълка 2 круша 3 bAnAnA $ sed -e "/ ^ [^ lmnXYZ] * $ / s / ухо / всеки / g" text1 # заменете ухото с всяко на редове, които не започват с lmnXYZ 1 ябълка 2 праскова 3 банан $ echo "Първо Фраза. Това е изречение." | \ # Заменете последната дума в изречение с ПОСЛЕДЕН СВЯТ. > sed -e "s / [^] * \ ./ ПОСЛЕДНА ДУМА./g" Първо. ПОСЛЕДНА ДУМА. Това е ПОСЛЕДНА ДУМА.
Предистория и източник:не всеки, който трябва да използва регулярни изрази, разбира напълно как работят и как да ги създава. Аз също принадлежах към тази група - търсех примери за регулярни изрази, които отговарят на задачите ми, опитвах се да ги коригирам, ако е необходимо. За мен всичко се промени коренно след като прочетох книгата. Командният ред на Linux (второ интернет издание)автора Уилям Е. Шотс младшиВ него принципите на работа на регулярните изрази са изложени толкова ясно, че след като прочетох, се научих да ги разбирам, да създавам регулярни изрази с всякаква сложност и сега ги използвам, когато е необходимо. Този материал е превод на частта от главата, посветена на регулярните изрази. Този материал е предназначен за абсолютно начинаещи, които изобщо не разбират как работят регулярните изрази, но имат някаква представа как работят. Надявам се тази статия да ви помогне да направите същия пробив, който помогна на мен. Ако материалът тук не е нищо ново за вас, опитайте статията Редовни изрази и командата grep за повече подробности относно опциите grep и допълнителни примери.
Как се използват регулярните изрази
Текстовите данни играят важна роля във всички Unix-подобни системи като Linux. Освен всичко друго, текстът е изходът на конзолни програми и конфигурационни файлове, отчети и т.н. Регулярни изразиса (може би) една от най-трудните концепции за работа с текст, тъй като включват високо ниво на абстракция. Но времето, прекарано в изучаването им, ще се изплати с лихва. Знанието как да използвате регулярни изрази може да ви помогне да правите невероятни неща, въпреки че пълната им стойност може да не е очевидна веднага.
Тази статия ще ви преведе през използването на регулярни изрази във връзка с командата grep... Но тяхното приложение не се ограничава само до това: регулярните изрази се поддържат от други команди на Linux, много езици за програмиране, те се използват в конфигурацията (например в настройките на правилата mod_rewrite в Apache), а също и някои програми с GUI ви позволяват да задайте правила за търсене / копиране / изтриване от поддръжка на регулярни изрази. Дори в популярната офис програма Microsoft Word можете да използвате регулярни изрази и заместващи знаци, за да намерите и замените текст.
Какво представляват регулярните изрази?
С прости думи, регулярният израз е стенография, символна нотация за шаблон, който се търси в текст. Регулярните изрази се поддържат от много инструменти на командния ред и повечето езици за програмиране и се използват, за да ви помогнат да решите проблеми с манипулирането на текст. Въпреки това (сякаш тяхната сложност не е достатъчна за нас), не всички регулярни изрази са еднакви. Те се различават леко от инструмент до инструмент и от език за програмиране. За нашата дискусия ще се ограничим до регулярните изрази, описани в стандарта POSIX (който ще покрива повечето инструменти на командния ред), за разлика от много езици за програмиране (най-вече Perl), които използват малко по-големи и по-богати набори от нотации.
grep
Основната програма, която ще използваме за регулярни изрази, е нашият стар приятел. Името "grep" всъщност идва от фразата "глобален печат на регулярен израз", така че можем да видим, че grep има нещо общо с регулярните изрази. По същество grep търси текстови файлове за текст, който съответства на посочения редовен израз и отпечатва всеки ред, който съответства на посочения низ, към стандартния изход.
grep може да търси текст, получен при стандартен вход, например:
Ls / usr / bin | grep zip
Тази команда ще изброи файловете в директорията /usr/bin, чиито имена съдържат подниз "zip".
Grep може да търси текст във файлове.
Общ синтаксис на употреба:
Grep [опции] регулярен израз [файл ...]
- регулярен изразе регулярен израз.
- [файл...]- един или повече файлове, в които ще се извърши търсенето на регулярен израз.
[опции] и [файл ...] може да липсват.
Списък с най-често използваните grep опции:
| Вариант | Описание |
|---|---|
| -i | Пренебрегвайте главните букви. Не правете разлика между големи и малки знаци. Може да се настрои и с опцията --игнориране-регистр. |
| -v | Обърнете съвпадение. Обикновено grep отпечатва редове, които съдържат съвпадение. Тази опция кара grep да отпечатва всеки ред, който не съвпада. Можете също да използвате --invert-match. |
| -° С | Отпечатайте броя на съвпаденията (или несъответствията, ако е посочена опцията -v) вместо самите низове. Може да се посочи и с опцията --броя. |
| -л | Вместо самите редове, отпечатайте името на всеки файл, който съдържа съвпадението. Може да се посочва по опция --файлове-със-съвпадения. |
| -Л | Като опция -лно отпечатва само имена на файлове, които не съдържат съвпадения. Друго име на опция --файлове-без съвпадение. |
| -н | Добавя номер на ред във файла в началото на всеки съвпадащ ред. Друго име на опция --номер-ред. |
| -h | За да търсите в множество файлове, потиснете извеждането на името на файла. Можете също да посочите опцията --без име на файл. |
За да изследваме grep по-пълно, нека създадем няколко текстови файлове, които да търсим:
Ls / bin> dirlist-bin.txt ls / usr / bin> dirlist-usr-bin.txt ls / sbin> dirlist-sbin.txt ls / usr / sbin> dirlist-usr-sbin.txt ls dirlist * .txt dirlist -bin.txt dirlist-sbin.txt dirlist-usr-bin.txt dirlist-usr-sbin.txt
Можем да направим просто търсене в нашия списък с файлове като този:
Grep bzip dirlist * .txt dirlist-bin.txt: bzip2 dirlist-bin.txt: bzip2recover
Този пример grep търси всички изброени файлове за bzip низа и намира две съвпадения, и двете във файла dirlist-bin.txt. Ако се интересуваме само от списъка с файлове, съдържащи съвпадения, а не от самите съвпадащи редове, можем да посочим опцията -л:
Grep -l bzip dirlist * .txt dirlist-bin.txt
Обратно, ако искаме само да видим списък с файлове, които не съдържат съвпадения, можем да направим това:
Grep -L bzip dirlist * .txt dirlist-sbin.txt dirlist-usr-bin.txt dirlist-usr-sbin.txt
Ако няма изход, тогава файловете, които отговарят на условията, не са открити.
Метасимволи и литерали
Въпреки че това може да не изглежда очевидно, нашите grep търсения винаги използват регулярни изрази, макар и много прости. Регулярният израз "bzip" означава, че ще има съвпадение (тоест низът ще се счита за подходящ) само ако редът във файла съдържа поне четири знака и че някъде в низа има знаци "b", "z " , "I" и "p" са в този ред, без други знаци между тях. Знаците в низа "bzip" са литерали, т.е. буквални символикакто отговарят на себе си. В допълнение към литералите, регулярните изрази също могат да включват метазнацикоито се използват за определяне на по-сложни съвпадения. Метазнаците с регулярна експресия се състоят от следното:
^ $ . { } - ? * + () | \Всички останали знаци се считат за буквални. Обратната наклонена черта може да има различни значения. Използва се в няколко случая за създаване мета последователностии също така позволява метасимволите да бъдат екранирани и третирани като литерали, а не като метасимволи.
Забележка:както виждаме, много от метасимволите на регулярните изрази също са символи със значение на обвивката (извършващи разширяване). Когато указвате регулярен израз, съдържащ метасимволи от командния ред, е задължително да го поставите в кавички, в противен случай шелът ще ги интерпретира по различен начин и ще наруши вашата команда.
Всеки герой
Първият метазнак, с който започваме запознанството си е символ на точкакоето означава "всякакъв символ". Ако го включим в регулярния израз, той ще съответства на всеки знак за позицията на този знак. пример:
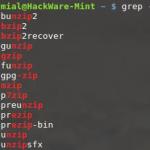
Grep -h ".zip" dirlist * .txt bunzip2 bzip2 bzip2recover gunzip gzip funzip gpg-zip mzip p7zip preunzip prezip prezip-bin разархивирайте unzipsfx

Потърсихме всеки ред в нашите файлове, който съответства на регулярния израз ".zip". В получените резултати трябва да се отбележат няколко интересни точки. Моля, имайте предвид, че zip програмата не беше намерена. Това е така, защото включването на метасимвола точка в нашия регулярен израз увеличи дължината, необходима за съвпадение до четири знака, и тъй като името "zip" съдържа само три, то не съвпада. Освен това, ако някой от файловете в нашите списъци съдържа разширение на файла .zip, те също ще се считат за валидни, тъй като знакът точка в разширението на файла също отговаря на условието „всякои знаци“.
Котви
Знакът на карета ( ^ ) и знак за долар ( $ ) се разглеждат в регулярни изрази котви... Това означава, че те съвпадат само ако регулярният израз е намерен в началото на реда ( ^ ) или в края на реда ( $ ):
Grep -h "^ zip" dirlist * .txt zip zipcloak zipdetails zipgrep zipinfo zipnote zipsplit grep -h "zip $" dirlist * .txt gunzip gzip funzip gpg-zip mzip p7zip preunzip unzip prezip zip zip zip zip zip.

Тук разгледахме списъците с файлове за реда "zip", разположен в началото на реда, в края на реда, както и в реда, където той би бил както в началото, така и в края (т.е. целият ред ще съдържа само "zip"). Имайте предвид, че регулярният израз " ^$ „(Началото и краят, между които няма нищо) ще съвпадат с празни редове.
Малко лирично отклонение: помощник за решаване на кръстословици
Дори и с ограничените ни в момента познания за регулярните изрази, можем да направим нещо полезно.
Ако някога сте правили кръстословици, тогава трябваше да решавате задачи като "каква дума от пет букви, където третата буква е" j ", а последната буква е" r ", което означава ...". Този въпрос може да предизвика размисъл. Знаете ли, че има речник на Linux? И той е. Погледнете в директорията / usr / share / dict, там можете да намерите един или повече речници. Публикуваните там речници са само дълги списъци с думи, по една на ред, подредени по азбучен ред. В моята система речниковият файл съдържа 99 171 думи. За да потърсим възможни отговори на горния въпрос кръстословица, можем да направим това:
Grep -i "^ .. j.r $" / usr / share / dict / американски-английски Основна специалност
Използвайки този регулярен израз, можем да намерим всички думи в нашия речников файл, които са дълги пет букви, имат "j" на третата позиция и "r" на последната позиция.
Примерът използва английски речников файл, тъй като той присъства в системата по подразбиране. След като предварително сте изтеглили съответния речник, можете да правите подобни търсения на думи на кирилица или от всякакви други знаци.
Изрази в скоби и класове на знаци
В допълнение към съвпадението на всеки знак на дадена позиция в нашия регулярен израз, ние също използваме изрази в квадратни скоби, можем да съпоставим единичен знак от посочения набор от знаци. С изрази в квадратни скоби можем да посочим набора от знаци, който да съответства (включително знаци, които иначе биха били интерпретирани като метазнаци). В този пример, използвайки набор от два знака:
Grep -h "zip" dirlist * .txt bzip2 bzip2recover gzip
ще намерим всички редове, съдържащи низовете "bzip" или "gzip".
Наборът може да съдържа произволен брой знаци и метазнаците губят специалното си значение, когато се поставят в квадратни скоби. Има обаче два случая, в които метазнаците, използвани в квадратни скоби, имат различни значения. Първият е каретката ( ^ ), който се използва за обозначаване на отрицание; второто е тире ( - ), който се използва за определяне на диапазон от знаци.
Отрицание
Ако първият знак на израза в квадратни скоби е карета ( ^ ), тогава останалите знаци се приемат като набор от знаци, които не трябва да присъстват в дадена позиция на символа. Нека направим това, като модифицираме предишния ни пример:
Grep -h "[^ bg] zip" dirlist * .txt bunzip2 gunzip funzip gpg-zip mzip p7zip preunzip prezip prezip-bin разархивирайте unzipsfx

С активирано отрицание получихме списък с файлове, които съдържат низа "zip", предшестван от всеки знак с изключение на "b" или "g". Моля, имайте предвид, че ципът не е намерен. Отричаният набор от знаци все още изисква знака на дадената позиция, но знакът не трябва да е член на обърнатия набор от знаци.
Символът за превоз се отрича само ако е първият знак в израза в скоби; в противен случай губи специалното си предназначение и се превръща в обикновен персонаж от набора.
Традиционни знаци
Ако искаме да изградим регулярен израз, който трябва да намери всеки файл в нашия списък, който започва с главна буква, можем да направим следното:
Grep -h "^" dirlist * .txt MAKEDEV ПОЛУЧАВАНЕ НА ГЛАВНА ПУБЛИКАЦИЯ VBoxClient X X11 Xorg ModemManager NetworkManager VBoxControl VBoxService
Изводът е, че поставяме всичките 26 главни букви в израза в квадратни скоби. Но идеята да ги отпечатате всички не е ентусиазирана, така че има друг начин:
Grep -h "^" dirlist * .txt

Използвайки диапазон от 3 знака, можем да съкратим запис от 26 букви. Всеки диапазон от знаци може да бъде изразен по този начин, включително множество диапазони наведнъж, като този израз, който съответства на всички имена на файлове, започващи с букви и цифри:
Grep -h "^" dirlist * .txt
В диапазоните от знаци виждаме, че знакът за тире се третира по специален начин, така че как можем да включим знака тире в израза в квадратните скоби? Като го направи първият знак в израза. Нека разгледаме два примера:
Grep -h "" dirlist * .txt
Това ще съответства на всяко име на файл, съдържащо главна буква. при което:
Grep -h "[-AZ]" dirlist * .txt
ще съответства на всяко име на файл, съдържащо тире или главни букви "A" или главни букви "Z".
Регулярните изрази са много мощен инструмент за съпоставяне на шаблони, манипулиране и модифициране на низове и могат да се използват за различни задачи. Ето основните от тях:
- Проверка на въвеждане на текст;
- Търсене и замяна на текст във файл;
- Пакетно преименуване на файлове;
- Взаимодействие с услуги като Apache;
- Проверка на низ спрямо шаблон.
Това не е пълен списък; има много повече, които можете да направите с регулярните изрази. Но за новите потребители те може да изглеждат твърде сложни, тъй като за тяхното формиране се използва специален език. Но предвид възможностите, които предоставя, регулярните изрази на Linux трябва да бъдат познати и използвани от всеки системен администратор.
В тази статия ще ви преведем през регулярните изрази на bash за начинаещи, за да можете да разберете всички функции на този инструмент.
Има два типа знаци, които могат да се използват в регулярни изрази:
- обикновени писма;
- метазнаци.
Редовните знаци са буквите, цифрите и препинателните знаци, които съставят всеки низ. Всички текстове са съставени от букви и можете да ги използвате в регулярни изрази, за да намерите желаната позиция в текста.
Метасимволите са нещо друго, те дават сила на регулярните изрази. С метазнаците можете да направите много повече от търсене на един символ. Можете да търсите комбинации от знаци, да използвате динамичен брой знаци и да избирате диапазони. Всички специални знаци могат да бъдат разделени на два типа, това са заместващи знаци, които заместват обикновените знаци, или оператори, които показват колко пъти даден знак може да се повтори. Синтаксисът на регулярния израз ще изглежда така:
редовен_символ специален символ_оператор
специален символ_замяна специален символ_оператор
- - буквалните специални знаци започват с обратна наклонена черта и се използва и ако трябва да използвате специален знак под формата на препинателен знак;
- ^ - обозначава началото на реда;
- $ - обозначава края на реда;
- * - показва, че предишният знак може да се повтори 0 или повече пъти;
- + - показва, че предишният знак трябва да се повтори повече от един или повече пъти;
- ? - предишният символ може да се появи нула или един път;
- (н)- показва колко пъти (n) да се повтори предишният знак;
- (N, n)- предишният знак може да се повтори от N до n пъти;
- . - всеки знак с изключение на превод на ред;
- - всеки знак, посочен в скоби;
- х | у- символ x или символ y;
- [^ az]- всеки знак, различен от посочените в скоби;
- - всеки знак от посочения диапазон;
- [^ a-z]- всеки знак, който не е в диапазона;
- б- обозначава граница на думата с интервал;
- Б- означава, че символът трябва да е вътре в дума, например ux съответства на uxb или tuxedo, но не съответства на Linux;
- д- означава, че символът е цифра;
- д- нецифров знак;
- н- символ за подаване на ред;
- с- един от символите интервал, интервал, табулация и т.н.;
- С- всеки знак с изключение на интервал;
- T- табличен характер;
- v- вертикален табулаторен знак;
- w- всеки азбучен знак, включително долна черта;
- У- всеки азбучен знак с изключение на долна черта;
- uXXX- Символ Unicdoe.
Важно е да се отбележи, че наклонената черта трябва да се използва преди специалните символи на литерала, за да се посочи, че специалният знак е следващият. Обратното също е вярно, ако искате да използвате специален знак, който се използва без наклонена черта като обикновен знак, тогава трябва да добавите наклонена черта.
Например, да предположим, че искате да намерите реда 1+ 2 = 3 в текста. Ако използвате този низ като регулярен израз, няма да намерите нищо, защото системата интерпретира плюс като специален символ, който казва, че предишната единица трябва да се повтори един или повече пъти. Така че трябва да се екранира: 1 + 2 = 3. Без екраниране, нашият регулярен израз би съвпадал само с низа 11 = 3 или 111 = 3 и т.н. Не е необходимо да се поставя ред пред равен, защото това не е специален символ.
Примери за използване на регулярни изрази
След като покрихме основите и знаете как работи всичко, остава да консолидираме на практика придобитите знания за регулярните изрази на linux grep. Два много полезни специални символа са ^ и $, които обозначават началото и края на ред. Например, искаме да регистрираме всички потребители в нашата система, чието име започва с s. След това може да се приложи регулярният израз "^ S"... Можете да използвате командата egrep:
egrep "^ s" / etc / passwd
Ако искаме да избираме редове по последния знак в реда, можем да използваме $ за това. Например, нека изберем всички потребители на системата, без shell, записите за такива потребители завършват с false:
egrep "false $" / etc / passwd
За да отпечатате потребителски имена, които започват с s или d, използвайте израз като този:
egrep "^" / etc / passwd
Същият резултат може да се получи с помощта на знака "|". Първият вариант е по-подходящ за диапазони, а вторият се използва по-често за редовни или/или:
egrep "^" / etc / passwd
Сега нека изберем всички потребители, чието име е повече от три знака. Потребителското име завършва с двоеточие. Можем да кажем, че може да съдържа всеки азбучен знак, който трябва да се повтори три пъти преди двоеточие:
egrep "^ w (3):" / etc / passwd
заключения
В тази статия разгледахме регулярните изрази на Linux, но това бяха само основите. Ако се поразровите малко по-дълбоко, ще откриете, че има много по-интересни неща, които можете да правите с този инструмент. Времето, прекарано в изучаване на регулярни изрази, определено ще си заслужава.
В заключение, лекция от Yandex за регулярните изрази:
Редовен израз- текстов модел, състоящ се от комбинация от букви, цифри и специални знаци, известни като метазнаци. Близък братовчед на регулярните изрази са заместващи изрази, които обикновено се използват в управлението на файлове. Регулярните изрази се използват главно за сравнение и търсене на текст. Използва се широко за анализиране на синтаксис.
Потребителите на UNIX са запознати с регулярните изрази от grep, sed, awk (или gawk) и ed. Използвайки тези програми или техните аналози, можете да опитате и да проверите примерите по-долу. Текстови редактори като (X) Emacs и vi също използват силно регулярни изрази. Може би най-известното и най-широко използване на регулярни изрази се среща в езика Perl. За разработчика на софтуер и системния администратор е трудно да се справят без познаване на регулярните изрази.
Метазнаци
И така, низовете могат да бъдат съставени от букви, цифри и метазнаци. Метазнаците са:
\ | () { } ^ $ * + ? . < >
Метазнаците могат да играят следните роли в регулярен израз:
квантор
изявление;
групов знак;
алтернатива;
знак за последователност
Кванторите
Метазнакът * (звездичка) замества 0 или повече знака. Метазнакът + (плюс) замества 1 или повече знака. Метахарактер. (точка) замества точно 1 произволен знак. Метахарактер? (въпросителен знак) замества 0 или 1 знак. Разликата в използването на * и + е такава, че заявка за намиране на низ с * ще върне всички низове, включително празни, а заявка с + ще върне само низове, съдържащи символа c.
Празните редове се подчиняват на следните конвенции: Празен ред съдържа един и само един празен ред; непразен ред съдържа празни редове преди всеки знак, а също и в края на реда.
Регулярните изрази също използват конструкцията (n, m), което означава, че символът, предхождащ конструкцията, се среща от n до m пъти в низа. Пропускането на числото m означава безкрайност. Тези. специални случаи на конструкцията са следните записи: (0,), (1,) и (0,1). Първият съответства на *, вторият съответства на метазнака +, а третият съвпада? ... Тези равенства са лесни за получаване от дефиницията на съответните квантори. Освен това конструкцията (n) означава, че символът се появява точно n пъти.
Във връзка с използването на някои препинателни знаци и математически символи като метасимволи, е въведен допълнителен метазнак \ (обратна наклонена черта, обратна наклонена черта), която при изписване преди метазнака превръща последния в обикновен знак. Тези. ? е квантор, а \? - въпросителен знак.
Групи
Описаните по-горе квантификатори, както вече споменахме, действат върху най-близкия до тях герой вляво (последният предхождащ). Но това ограничение ви позволява да заобиколите групите в обозначението на метасимволите (и). Тези знаци извличат подизраз от израз, групиран в група, към който след това се прилага квантор.
пример:
означава (или замества)
Хо хо хо хо хо хо хохо
Възможно е влагане на подизрази, т.е. по-кратки подизрази могат да бъдат извлечени от подизраз.
Алтернативи
Създаден с помощта на метазнака | (вертикална лента), обозначаваща логическо „или“.
Пример: регулярен израз крави (a | s | e | y | опа | oyu)? посочва всички възможни склонения на думата "крава" в единствено число за падежи.
твърдения
Разпределят се метасимволи, които обозначават специални обекти - низове с нулева дължина, които се използват за определяне на мястото на текста, предхождащ или следващ ги. Такива обекти се наричат изявления. Следните изрази съществуват в регулярни изрази:
^ начало на ред $ край на ред< начало слова >край на думатаПример: регулярният израз $ The съвпада с низа, който започва с The.
Забележка: Редовните знаци могат да се разглеждат като изрази с ненулева дължина.
Последователности
Специална конструкция, затворена в метазнаците [и] (квадратни скоби), ви позволява да изброите вариантите на знаци, които могат да се появят в регулярния израз на дадено място, и се нарича последователност. В квадратните скоби всички метасимволи се третират като прости символи, а символите - (минус) и ^ придобиват нови значения: първият ви позволява да посочите непрекъсната последователност от знаци между двата посочени, а вторият дава логическо "не" ( отрицание). Следните примери са най-лесни за разглеждане:
някоя от малките латински букви:
латински букви и цифри (от a до z, от A до Z и от 0 до 9):
нелатинско-цифров знак:
[^ a-zA-Z0-9]
всяка дума (без тирета, математически символи и числа):
<+>
За краткост и простота се въвеждат следните съкращения:
\ d цифра (т.е. съвпада с израз); \ D не е цифра (т.е. [^ 0-9]); \ w латинска дума (буквено-цифрова); \ W е поредица от знаци без интервали, която не е латинска буквено-цифрова дума ([^ a-zA-Z0-9]); \ s празно пространство [\ t \ n \ r \ f], т.е интервали, табулатори и др. \ S е непразен интервал ([^ \ t \ n \ r \ f]).Връзка с заместващи знаци
Всеки потребител вероятно е запознат със заместващите знаци. Пример за заместващ знак е * .jpg, който обозначава всички файлове с разширение jpg. По какво се различават регулярните изрази от заместващите символи? Разликите могат да бъдат обобщени в три правила за преобразуване на произволен заместващ израз в регулярен израз:
Заменено от.*
Замяна? На.
Заменете всички знаци, които съответстват на метасимволи, с техните варианти с обратна наклонена черта.
Всъщност в регулярен израз писането * е безполезно и дава празен низ, тъй като означава, че празният низ се повтаря произволен брой пъти. И ето. * (Повторете произволен знак колкото пъти искате, включително 0) точно съвпада по значение със знака * в набора от заместващи знаци.
Регулярният израз, съответстващ на * .jpg, ще изглежда така: * \. Jpg. Например последователностите с заместващи знаци ez * .pp съвпадат с два еквивалентни регулярни израза, ez. * \. Pp и ez. * \. (Cpp | hpp).
Примери за регулярни изрази
Имейл във формата [защитен с имейл]
+(\.+)*@+(\.+)+
Имейл във формат „Иван Иванов
("? +"? [\ t] *) + \<+(\.+)*@+(\.+)+\>
Проверка на уеб протокола в URL адреса (http: //, ftp: // или https: //)
+://
Някои C / C ++ команди и директиви:
^ # включва [\ t] + [<"][^>"] + [">] - директива за включване
//.+$ - коментар на един ред
/ \ * [^ *] * \ * / - коментар на няколко реда
-? + \. + - число с плаваща запетая
0x + е шестнадесетично число.
И ето, например, програмата за намиране на думата крава:
grep -E "крава | vache" *> / dev / null && echo "Намерена крава"Тук опцията -E се използва за активиране на разширена поддръжка на синтаксис на регулярни изрази.
Този текст е базиран на статия на Ян Борсоди от файла HOWTO-regexps.htm
Непрекъснат израз е модел, който описва набор от низове. Редовните изрази се конструират подобно на аритметичните изрази, като се използват различни оператори за комбиниране на по-малки изрази.
Непрекъснати изрази (английски регулярни изрази, съкратено RegExp, RegEx, jarg. Regexps или регулярни изрази) е система за разбор на текстови фрагменти според формализиран шаблон, базирана на системата за писане на шаблони за търсене. Шаблонът определя правилото за търсене, на руски също понякога се щраква върху "шаблон", "маска". Регулярните изрази направиха пробив в електронната обработка на съдържание в края на 20-ти век. Те са представени от развитието на заместващи знаци.
Постоянните изрази вече се използват от множество текстови редактори и помощни програми за намиране и модифициране на текст въз основа на избрани правила. Почти много езици за програмиране поддържат регулярни изрази за манипулиране на низове. Например Java, .NET Framework, Perl, PHP, JavaScript, Python и други имат вградена поддръжка за постоянни изрази. Набор от помощни програми (включително sed редактора и grep филтър), считани от UNIX дистрибуциите за едни от най-ранните, помогнаха за популяризирането на концепцията за регулярни изрази.
Една от по-полезните и богати на функции команди в терминала на Linux е бригадата "grep". Grep е съкращение, което означава "глобален печат на регулярен израз" (тоест "търсете навсякъде низове, които съответстват на константен израз, и ги отпечатайте").
Това означава, че можете да използвате grep, за да видите дали въведеното ви съответства на даден модел. В най-простата си форма grep се използва за намиране на съвпадения за буквени шаблони в текстов файл. Това означава, че ако grep получи дума за търсене, той ще отпечата всеки ред във файла, който съхранява тази дума.
Целта на grep е да търси низове според условие за регулярен израз. Има промени в класическия grep - egrep, fgrep, rgrep. Всички те са фино настроени за конкретни цели, докато възможностите на grep припокриват цялата функционалност. Най-простият пример за използване на команда е да изведете низ, който съответства на шаблон от файл. Например искаме да намерим реда, съхраняващ „user“ във файла /etc/mysql/my.cnf. За да направим това, ще използваме следната команда:
Потребител на Grep /etc/mysql/my.cnf
Grep може просто да търси конкретна дума:
Grep Здравейте ./example.cpp
Или низ, но в този случай той трябва да бъде затворен в кавички:
Grep "Здравей свят" ./example.cpp
В допълнение, алтернативите на програмата са egrep и fgrep, които са същите като grep -E и grep -F, съответно. Ароматизаторите egrep и fgrep са отхвърлени, но работят за обратна съвместимост. Препоръчително е да използвате grep -E и grep -F вместо отхвърлените опции.
Командата grep съпоставя редовете на изходните файлове с шаблон, този основен регулярен израз. Ако не са посочени файлове, се използва стандартен вход. Както обикновено, всеки успешно съпоставен ред се копира в стандартен изход; ако
малко изходни файлове, името на файла се отпечатва преди намерения ред. Като шаблони се приемат основни непрекъснати изрази (изрази, които имат символни низове като значение и използват ограничен набор от буквено-цифрови и специални знаци).
Използване на egrep в Linux
Egrep или grep -E е различна версия на grep или Extended grep. Тази версия на grep е отлична и бърза, когато става въпрос за търсене на модел на регулярни изрази, тъй като третира метасимволите такива, каквито са и не ги замества като низове. Egrep използва ERE или Extended Extended Expression.
egrep е съкратено извикване на grep с превключвателя -E. Той се различава от grep по способността да се използват разширени непрекъснати изрази, използващи POSIX символни класове. Проблемът често възниква при намирането на думи или представяния, които принадлежат към един и същи тип, но с възможни вариации в правописа, като дати, фамилни имена на файлове с някакво разширение и стандартно име, имейл адреси. От друга страна има задачи за намиране на добре дефинирани думи, които могат да имат различни форми, или търсене, което изключва отделни знаци или класове знаци.
За тези цели на истината, някои системи са създадени въз основа на описание на текст с помощта на шаблони. Постоянните изрази също се класират сред такива системи. Два много полезни специални символа са ^ и $, които обозначават началото и края на ред. Например, искаме да регистрираме всички потребители в нашата система, чието име започва с s. Тогава може да се приложи регулярният израз "^ s". Можете да използвате бригадата egrep:
Egrep "^ s" / etc / passwd
Възможно е търсене в няколко файла, като в такъв случай името на файла се показва пред реда.
Egrep -i Здравейте ./example.cpp ./example2.cpp
И следната заявка показва целия код, с изключение на редове, съдържащи само коментари:
Egrep -v ^ / ./example.cpp
Като egrep, дори и да не избягвате метасимволите, командата ще ги третира като специални знаци и ще ги замени със специалното им значение, вместо да ги третира като част от низ.
Използване на fgrep в Linux
Fgrep или Fixed grep или grep -F е друга версия на grep, която е необходима, когато става въпрос за търсене на цял ред вместо обикновена концепция, тъй като не разпознава регулярни изрази или метасимволи. За да търсите директно произволен ред, изберете тази версия на grep.
Fgrep търси пълен низ и не разпознава специални символи като част от непрекъснат израз, независимо дали символите са екранирани или не.
Fgrep -C 0 "(f | g) ile" check_file fgrep -C 0 "\ (f \ | g \) ile" check_file
Използване на sed на Linux
sed (от английския Stream EDitor) е поточно текстов редактор (както и език за програмиране), който използва различни предварително дефинирани текстови трансформации в последователен поток от текстови. Sed може да бъде изхвърлен като grep, извеждайки редове, следващи модела на основен регулярен израз:
Sed -n / Здравейте / p ./example.cpp
Може да се използва за изтриване на редове (премахване на всички празни редове):
Sed / ^ $ / d ./example.cpp
Основният инструмент за работа със sed е израз като:
Sed s / lookup_expression / what_replace / filename
И така, примерна, ако изпълните командата:
Sed s / int / long / ./example.cpp
Разликите между "grep", "egrep" и "fgrep" са обсъдени по-горе. Независимо от разликите в набора от използвани регулярни представяния и скоростта на изпълнение, опциите на командния ред остават еднакви и за трите версии на grep.