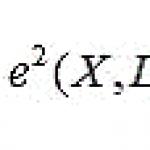1. Direct use of the data, or data storage.
In this case, the initial data is stored in an explicitly detailed form and is directly used at stages and / or parsing exceptions... The problem with this group of methods is that when using them, it can be difficult to analyze very large databases.
Methods of this group: cluster analysis, nearest neighbor method, k-nearest neighbor method, reasoning by analogy.
2. Identification and use of formalized patterns, or distillation templates.
With technology distillation templates one sample (template) of information is extracted from the initial data and transformed into some formal constructions, the form of which depends on the Data Mining method used. This process is carried out at the stage free search, the first group of methods does not have this stage in principle. In stages predictive modeling and parsing exceptions results of stage are used free search, they are much more compact than the databases themselves. Let us recall that the constructions of these models can be interpreted by the analyst or untracked ("black boxes").
Methods in this group: logical methods; visualization methods; cross-tabulation methods; methods based on equations.
Logical methods, or methods of logical induction, include: fuzzy queries and analyzes; symbolic rules; decision trees; genetic algorithms.
The methods of this group are, perhaps, the most interpretable - they formalize the found patterns, in most cases, in a fairly transparent form from the user's point of view. The resulting rules can include continuous and discrete variables. It should be noted that decision trees can be easily converted to symbolic rulesets by generating one rule along the path from the root of the tree to its terminal top... Decision trees and rules are actually different ways of solving one problem and differ only in their capabilities. In addition, the implementation of the rules is carried out by slower algorithms than the induction of decision trees.
Cross-tabulation methods: agents, Bayesian (trust) networks, cross-tabular visualization. The last method does not quite correspond to one of the properties of Data Mining - independent search patterns analytical system. However, the provision of information in the form of cross tables ensures the implementation of the main task of Data Mining - the search for patterns, therefore this method can also be considered one of the Data Mining methods.
Equation-based methods.
The methods of this group express the revealed patterns in the form of mathematical expressions - equations. Therefore, they can only work with numeric variables, and variables of other types must be coded accordingly. This somewhat limits the application of the methods of this group, nevertheless, they are widely used in solving various problems, especially forecasting problems.
The main methods of this group: statistical methods and neural networks
Statistical methods are most often used to solve forecasting problems. There are many methods of statistical data analysis, among them, for example, correlation-regression analysis, correlation of time series, identifying trends in time series, harmonic analysis.
Another classification divides the whole variety of Data Mining methods into two groups: statistical and cybernetic methods. This partitioning scheme is based on different approaches to teaching mathematical models.
It should be noted that there are two approaches to classifying statistical methods as Data Mining. The first of them contrasts statistical methods and Data Mining, its supporters consider classical statistical methods to be a separate direction of data analysis. According to the second approach, statistical methods of analysis are part of the Data Mining mathematical toolkit. Most reputable sources take the second approach.
In this classification, two groups of methods are distinguished:
- statistical methods based on the use of averaged accumulated experience, which is reflected in retrospective data;
- cybernetic methods, which include many heterogeneous mathematical approaches.
The disadvantage of such a classification: both statistical and cybernetic algorithms in one way or another rely on the comparison of statistical experience with the results of monitoring the current situation.
The advantage of this classification is its convenience for interpretation - it is used to describe the mathematical tools of the modern approach to knowledge extraction from arrays of initial observations (operational and retrospective), i.e. in Data Mining tasks.
Let's take a closer look at the groups presented above.
Statistical data mining methods
The methods represent four interrelated sections:
- preliminary analysis of the nature of statistical data (testing hypotheses of stationarity, normality, independence, homogeneity, assessment of the form of the distribution function, its parameters, etc.);
- identifying links and patterns(linear and nonlinear regression analysis, correlation analysis, etc.);
- multivariate statistical analysis (linear and nonlinear discriminant analysis, cluster analysis, component analysis, factor analysis and etc.);
- dynamic models and time series forecast.
The arsenal of statistical methods Data Mining is classified into four groups of methods:
- Descriptive analysis and description of the initial data.
- Relationship analysis (correlation and regression analysis, factor analysis, analysis of variance).
- Multivariate statistical analysis (component analysis, discriminant analysis, multivariate regression analysis, canonical correlations, etc.).
- Time series analysis ( dynamic models and forecasting).
Cybernetic Methods of Data Mining
The second direction of Data Mining is a set of approaches united by the idea of computer mathematics and the use of the theory of artificial intelligence.
data mining) and on "rough" exploratory analysis, which forms the basis of online analytical processing (OnLine Analytical Processing, OLAP), while one of the main provisions of Data Mining is the search for non-obvious patterns... Data Mining tools can find such patterns on their own and also independently form hypotheses about relationships. Since it is the formulation of a hypothesis regarding dependencies that is the most difficult task, the advantage of Data Mining in comparison with other methods of analysis is obvious.Most statistical methods to identify relationships in data use the concept of averaging over a sample, which leads to operations on non-existent values, while Data Mining operates on real values.
OLAP is more suited to understanding historical data, Data Mining relies on historical data to answer questions about the future.
Data Mining Technology Perspectives
Data Mining's potential gives the green light to push the boundaries of technology. With regard to the prospects for Data Mining, the following directions of development are possible:
- identification of the types of subject areas with the corresponding heuristics, the formalization of which will facilitate the solution of the corresponding Data Mining problems related to these areas;
- creation of formal languages and logical means, with the help of which reasoning will be formalized and the automation of which will become a tool for solving Data Mining problems in specific subject areas;
- Creation of Data Mining methods that can not only extract patterns from data, but also form some theories based on empirical data;
- overcoming a significant gap between the capabilities of Data Mining tools and theoretical advances in this area.
If we consider the future of Data Mining in the short term, then it is obvious that the development of this technology is most directed towards areas related to business.
In the short term, Data Mining products can become as common and essential as email and, for example, be used by users to find the lowest prices for a particular product or the cheapest tickets.
In the long term, the future of Data Mining is truly exciting - it can be a search by intelligent agents for both new treatments for various diseases, and a new understanding of the nature of the universe.
However, Data Mining is fraught with potential danger - after all, an increasing amount of information is becoming available through the worldwide network, including private information, and more and more knowledge can be obtained from it:
Not so long ago, the largest online store "Amazon" was at the center of a scandal over the patent "Methods and systems for helping users to buy goods", which is nothing more than another Data Mining product designed to collect personal data about store visitors. The new methodology makes it possible to predict future requests based on the facts of purchases, as well as draw conclusions about their purpose. The purpose of this technique is, as mentioned above, to obtain as much information as possible about clients, including of a private nature (gender, age, preferences, etc.). In this way, data is collected about the privacy of store buyers, as well as their family members, including children. The latter is prohibited by the legislation of many countries - the collection of information about minors is possible there only with the permission of the parents.
Research notes that there are both successful solutions using Data Mining and bad experiences with this technology. The areas where Data Mining technology is most likely to be successful have the following features:
- require knowledge-based solutions;
- have a changing environment;
- have accessible, sufficient and meaningful data;
- provide high dividends from the right decisions.
Existing approaches to analysis
For a long time, the Data Mining discipline was not recognized as a full-fledged independent field of data analysis, sometimes it is called the "backyard of statistics" (Pregibon, 1997).
To date, several points of view on Data Mining have been determined. Supporters of one of them consider it a mirage, distracting attention from classical analysis.
Ministry of Education and Science of the Russian Federation
Federal State Budgetary Educational Institution of Higher Professional Education
"NATIONAL RESEARCH TOMSK POLYTECHNICAL UNIVERSITY"
Institute of Cybernetics
Direction Informatics and computer engineering
Department of VT
Test
in the discipline informatics and computer engineering
Topic: Data Mining Methods
Introduction
Data Mining. Basic concepts and definitions
1 Steps in the data mining process
2 Components of mining systems
3 Methods of data mining in Data Mining
Data Mining Methods
1 Derivation of association rules
2 Neural network algorithms
3 Nearest Neighbor and k-Nearest Neighbor Methods
4 Decision trees
5 Clustering algorithms
6 Genetic algorithms
Applications
Data Mining Tool Manufacturers
Criticism of methods
Conclusion
Bibliography
Introduction
The result of the development of information technology is a colossal amount of data accumulated in electronic form, growing at a rapid pace. Moreover, data, as a rule, have a heterogeneous structure (texts, images, audio, video, hypertext documents, relational databases). The data accumulated over a long period of time can contain patterns, trends and relationships, which are valuable information in planning, forecasting, decision-making, and process control. However, a person is physically unable to efficiently analyze such volumes of heterogeneous data. Methods of traditional mathematical statistics have long claimed to be the main tool for data analysis. However, they do not allow synthesizing new hypotheses, but can only be used to confirm previously formulated hypotheses and “rough” exploratory analysis, which forms the basis of online analytical processing (OLAP). Often, it is the formulation of a hypothesis that turns out to be the most difficult task when conducting analysis for subsequent decision-making, since not all patterns in the data are obvious at first glance. Therefore, data mining technologies are regarded as one of the most important and promising topics for research and application in the information technology industry. In this case, data mining refers to the process of determining new, correct and potentially useful knowledge based on large amounts of data. Thus, MIT Technology Review described Data Mining as one of ten emerging technologies that will change the world.
1. Data Mining. Basic concepts and definitions
Data Mining is a process of detecting previously unknown, non-trivial, practically useful and accessible interpretation of knowledge in "raw" data, which is necessary for making decisions in various spheres of human activity.
The essence and purpose of Data Mining technology can be formulated as follows: it is a technology that is designed to search large amounts of data for non-obvious, objective and useful in practice patterns.
Non-obvious patterns are patterns that cannot be detected by standard methods of information processing or by expert advice.
Objective regularities should be understood as regularities that fully correspond to reality, in contrast to expert opinion, which is always subjective.
This data analysis concept assumes that:
§ data may be inaccurate, incomplete (contain gaps), contradictory, heterogeneous, indirect, and at the same time have gigantic volumes; therefore, understanding data in specific applications requires significant intellectual effort;
§ the algorithms for data analysis themselves may have "elements of intelligence", in particular, the ability to learn from precedents, that is, to draw general conclusions based on private observations; the development of such algorithms also requires significant intellectual effort;
§ The processes of processing raw data into information, and information into knowledge cannot be performed manually, and require automation.
The Data Mining technology is based on the concept of patterns (patterns) reflecting fragments of multidimensional relationships in data. These patterns represent patterns inherent in subsamples of data that can be compactly expressed in a human-readable form.
The search for patterns is carried out by methods that are not limited by the framework of a priori assumptions about the structure of the sample and the type of distributions of the values of the analyzed indicators.
An important feature of Data Mining is the non-standard and non-obviousness of the sought patterns. In other words, Data Mining tools differ from statistical data processing tools and OLAP tools in that instead of checking the interdependencies assumed in advance by users, they are able to find such interdependencies on their own based on the available data and build hypotheses about their nature. There are five standard types of patterns identified by Data Mining methods:
· Association - a high probability of the connection of events with each other. An example of an association is items in a store that are often purchased together;
· Sequence - a high probability of a chain of events related in time. An example of a sequence is a situation where, within a certain period of time after the acquisition of one product, another will be purchased with a high degree of probability;
· Classification - there are signs that characterize the group to which this or that event or object belongs;
· Clustering - a pattern similar to classification and different from it in that the groups themselves are not specified - they are detected automatically during data processing;
· Temporary patterns - the presence of patterns in the dynamics of the behavior of certain data. A typical example of a temporal pattern is seasonal fluctuations in demand for certain goods or services.
1.1 Steps in the data mining process
Traditionally, the following stages are distinguished in the data mining process:
1. Study of the subject area, as a result of which the main goals of the analysis are formulated.
2. Collection of data.
Data preprocessing:
a. Data cleaning - elimination of inconsistencies and random "noise" from the original data
b. Data Integration is the consolidation of data from multiple possible sources into a single repository. Data transformation. At this stage, the data is converted to a form suitable for analysis. Data aggregation, attribute sampling, data compression, and dimensionality reduction are commonly used.
4. Data analysis. Within this stage, mining algorithms are applied to extract patterns.
5. Interpretation of the found patterns. This step can include visualizing the extracted patterns, identifying really useful patterns based on some utility function.
Use of new knowledge.
1.2 Components of mining systems
Typically, data mining systems have the following main components:
1. Database, data warehouse or other information repository. It can be one or more databases, data warehouse, spreadsheets, other kinds of repositories that can be cleaned up and integrated.
2. Database server or data warehouse. The specified server is responsible for extracting essential data based on the user's request.
Knowledge base. It is domain knowledge that indicates how to search and evaluate the usefulness of the resulting patterns.
Knowledge mining service. It is an integral part of the data mining system and contains a set of functional modules for tasks such as characterization, finding associations, classification, cluster analysis and variance analysis.
Pattern evaluation module. This component calculates measures of interest or utility of patterns.
Graphical user interface. This module is responsible for communication between the user and the data mining system, visualization of patterns in various forms.
1.3 Methods of data mining in Data Mining
Most of the analytical methods used in Data Mining technology are well-known mathematical algorithms and methods. New in their application is the possibility of their use in solving certain specific problems, due to the emerging capabilities of hardware and software. It should be noted that most of the Data Mining methods were developed within the framework of the theory of artificial intelligence. Let's consider the most widely used methods:
Conclusion of association rules.
2. Neural network algorithms, the idea of which is based on an analogy with the functioning of nerve tissue and lies in the fact that the initial parameters are considered as signals that are transformed in accordance with the existing connections between "neurons", and the response of the entire network is considered as the response resulting from the analysis on the original data.
Selection of a close analogue of the initial data from the existing historical data. Also called the "nearest neighbor" method.
Decision trees are a hierarchical structure based on a set of questions that require a “Yes” or “No” answer.
Cluster models are used to group similar events into groups based on the similar values of several fields in a dataset.
In the next chapter, we will describe the above methods in more detail.
2. Data Mining Methods
2.1 Inference of association rules
Association rules are rules of the form "if ... then ...". Searching for such rules in a dataset reveals hidden relationships in seemingly unrelated data. One of the most frequently cited examples of the search for association rules is the problem of finding stable relationships in the shopping cart. The challenge is to determine which items are being purchased by customers together so that marketers can properly place those items in the store to increase sales.
Association rules are defined as statements of the form (X1, X2,…, Xn) -> Y, where it is assumed that Y can be present in a transaction, provided that X1, X2,…, Xn are present in the same transaction. It should be noted that the word "may" implies that the rule is not an identity, but only holds with some probability. In addition, Y can be a set of items, rather than just one item. The probability of finding Y in a transaction in which there are elements X1, X2,…, Xn is called confidence. The percentage of transactions containing a rule out of the total number of transactions is called support. The level of confidence that a rule must exceed is called interestingness.
There are different types of association rules. In their simplest form, association rules only report the presence or absence of an association. Such rules are called Boolean Association Rule. An example of such a rule would be: "Customers who buy yoghurt also buy low-fat butter."
Rules that bring multiple association rules together are called Multilevel or Generalized Association Rules. When constructing such rules, items are usually grouped according to a hierarchy, and searches are conducted at the highest conceptual level. For example, "customers who buy milk also buy bread." In this example, milk and bread contain a hierarchy of different types and brands, but searching at the bottom level will not find interesting rules.
A more complex type of rule is Quantitative Association Rules. This type of rule is searched for using quantitative (for example, price) or categorical (for example, gender) attributes, and is defined as (
The above rule types do not address the fact that transactions are, by their very nature, time-dependent. For example, searching before a product is listed for sale or after it has disappeared from the market will adversely affect the support threshold. With this in mind, the concept of the attribute lifetime in Temporal Association Rules search algorithms has been introduced.
The problem of finding association rules can be generally decomposed into two parts: searching for frequently occurring sets of elements, and generating rules based on the found frequently occurring sets. For the most part, previous research has followed these directions and expanded them in various directions.
Since the advent of the Apriori algorithm, this algorithm has been the most commonly used in the first step. Many improvements, for example, in speed and scalability, are aimed at improving the Apriori algorithm, at correcting its erroneous property of generating too many candidates for the most common sets of elements. Apriori generates itemsets using only the large itemsets found in the previous step, without re-examining transactions. The modified AprioriTid algorithm improves Apriori by only using the database on the first pass. The calculations in the subsequent steps only use the data generated in the first pass, which is much smaller than the original database. This leads to tremendous productivity gains. A further improved version of the algorithm, called AprioriHybrid, can be obtained by using Apriori on the first few passes, and then, on later passes, when the kth candidate sets can already be entirely allocated in the computer's memory, switch to AprioriTid.
Further efforts to improve the Apriori algorithm are related to the parallelization of the algorithm (Count Distribution, Data Distribution, Candidate Distribution, etc.), its scaling (Intelligent Data Distribution, Hybrid Distribution), the introduction of new data structures, such as trees of frequently occurring elements (FP-growth ).
The second step is mostly authentic and interesting. New modifications add the dimension, quality and temporal support described above to the traditional Boolean rule rules. An evolutionary algorithm is often used to find the rules.
2.2 Neural network algorithms
Artificial neural networks appeared as a result of the application of a mathematical apparatus to the study of the functioning of the human nervous system in order to reproduce it. Namely: the ability of the nervous system to learn and correct errors, which should make it possible to simulate, albeit rather crudely, the work of the human brain. The main structural and functional part of the neural network is the formal neuron, shown in Fig. 1, where x0, x1, ..., xn are the components of the vector of input signals, w0, w1, ..., wn are the values of the weights of the input signals of the neuron, and y is the output signal of the neuron.
Rice. 1. Formal neuron: synapses (1), adder (2), transducer (3).
A formal neuron consists of 3 types of elements: synapses, adder and transducer. A synapse characterizes the strength of the connection between two neurons.
The adder adds the input signals pre-multiplied by the corresponding weights. The converter implements the function of one argument - the output of the adder. This function is called the activation function or the transfer function of the neuron.
The formal neurons described above can be combined in such a way that the output signals of some neurons are input to others. The resulting set of interconnected neurons are called artificial neural networks (ANNs), or, in short, neural networks.
There are three general types of neurons, depending on their position in the neural network:
Input neurons, which receive input signals. Such neurons, neurons, as a rule, have one input with a unit weight, there is no bias, and the value of the output of the neuron is equal to the input signal;
Output neurons (output nodes), the output values of which represent the resulting output signals of the neural network;
Hidden neurons, which do not have direct connections with the input signals, while the values of the output signals of the hidden neurons are not the output signals of the ANN.
According to the structure of interneuronal connections, two classes of ANN are distinguished:
ANNs of direct propagation, in which the signal propagates only from input neurons to output neurons.
Recurrent ANN - ANN with feedback. In such ANNs, signals can be transmitted between any neurons, regardless of their location in the ANN.
There are two general approaches to teaching ANN:
Learning with a teacher.
Learning without a teacher.
Supervised learning involves the use of a predefined set of teaching examples. Each example contains a vector of input signals and a corresponding vector of reference output signals, which depend on the task at hand. This set is called a training set or training set. The training of the neural network is aimed at such a change in the weights of the ANN connections, in which the value of the ANN output signals differs as little as possible from the required values of the output signals for a given vector of input signals.
In unsupervised learning, the weights of connections are adjusted either as a result of competition between neurons, or taking into account the correlation of the output signals of neurons between which there is a connection. In the case of unsupervised learning, the training sample is not used.
Neural networks are used to solve a wide range of tasks, such as planning payloads for space shuttles and predicting exchange rates. However, they are not often used in data mining systems due to the complexity of the model (knowledge recorded as the weights of several hundred interneural connections are completely beyond analysis and interpretation by humans) and the long training time on a large training sample. On the other hand, neural networks have such advantages for use in data analysis tasks as resistance to noisy data and high accuracy.
2.3 Nearest Neighbor and k-Nearest Neighbor Methods
The nearest neighbor algorithm and k-nearest neighbor algorithm (KNN) are based on feature similarity. The nearest neighbor algorithm selects an object among all known objects that is as close as possible (using the metric of the distance between objects, for example, Euclidean) to a new previously unknown object. The main problem with the nearest neighbor method is its sensitivity to outliers in the training data.
The described problem can be avoided by the KNN algorithm, which distinguishes among all observations already k-nearest neighbors similar to a new object. Based on the classes of the nearest neighbors, a decision is made regarding the new object. An important task of this algorithm is to select the coefficient k - the number of records that will be considered similar. A modification of the algorithm, in which the contribution of a neighbor is proportional to the distance to the new object (the method of k-weighted nearest neighbors) allows to achieve greater classification accuracy. The k nearest neighbors method also allows us to estimate the forecast accuracy. For example, all k nearest neighbors have the same class, then the probability that the checked object will have the same class is very high.
Among the features of the algorithm, it is worth noting the resistance to anomalous outbursts, since the probability of such a record falling into the number of k-nearest neighbors is small. If this happened, then the influence on voting (especially weighted) (for k> 2) is also likely to be insignificant, and, therefore, the influence on the classification result will also be small. Also, the advantages are simple implementation, ease of interpretation of the result of the algorithm, the possibility of modifying the algorithm by using the most appropriate combination functions and metrics, which allows you to adjust the algorithm for a specific task. The KNN algorithm also has a number of disadvantages. First, the dataset used for the algorithm must be representative. Second, the model cannot be separated from the data: all examples must be used to classify a new example. This feature severely limits the use of the algorithm.
2.4 Decision trees
By the term "decision trees" is meant a family of algorithms based on the representation of classification rules in a hierarchical, sequential structure. This is the most popular class of algorithms for solving data mining problems.
A family of algorithms for constructing decision trees makes it possible to predict the value of a parameter for a given case based on a large amount of data on other similar cases. Usually algorithms of this family are used to solve problems that allow dividing all the source data into several discrete groups.
When algorithms for constructing decision trees are applied to a set of input data, the result is displayed in the form of a tree. Such algorithms allow for several levels of such a division, dividing the resulting groups (tree branches) into smaller ones based on other features. The division continues until the values that are supposed to be predicted become the same (or, in the case of a continuous value of the predicted parameter, close) for all obtained groups (leaves of the tree). It is these values that are used to make predictions based on this model.
The operation of algorithms for constructing decision trees is based on the application of methods of regression and correlation analysis. One of the most popular algorithms in this family is CART (Classification and Regression Trees), based on dividing data in a tree branch into two child branches; in this case, the further division of one or another branch depends on how much of the initial data is described by this branch. Several other similar algorithms allow you to split a branch into more child branches. In this case, the division is made on the basis of the highest correlation coefficient for the described branch of data between the parameter according to which the division occurs and the parameter that must be predicted in the future.
The popularity of the approach is associated with clarity and clarity. But decision trees are fundamentally unable to find the “best” (most complete and accurate) rules in the data. They implement the naive principle of sequential viewing of features and actually find parts of real patterns, creating only the illusion of a logical conclusion.
2.5 Clustering algorithms
Clustering is the task of breaking down a set of objects into groups called clusters. The main difference between clustering and classification is that the list of groups is not clearly specified and is determined during the operation of the algorithm.
The application of cluster analysis in general is reduced to the following stages:
· Selection of a sample of objects for clustering;
· Determination of the set of variables by which the objects in the sample will be evaluated. If necessary, normalize the values of variables;
· Calculation of values of the measure of similarity between objects;
· Application of the method of cluster analysis to create groups of similar objects (clusters);
· Presentation of analysis results.
After obtaining and analyzing the results, it is possible to adjust the selected metric and clustering method until the optimal result is obtained.
Among clustering algorithms, hierarchical and flat groups are distinguished. Hierarchical algorithms (also called taxonomy algorithms) build not one partition of a sample into disjoint clusters, but a system of nested partitions. Thus, the output of the algorithm is a tree of clusters, the root of which is the entire sample, and the leaves are the smallest clusters. Flat algorithms build one partition of objects into disjoint clusters.
Another classification of clustering algorithms is into clear and fuzzy algorithms. Clear (or non-overlapping) algorithms assign a cluster number to each sample object, that is, each object belongs to only one cluster. Fuzzy (or overlapping) algorithms associate each object with a set of real values that show the degree of the object's relation to clusters. Thus, each object belongs to each cluster with some probability.
Among hierarchical clustering algorithms, there are two main types: bottom-up and top-down algorithms. Top-down algorithms work on the top-down principle: first, all objects are placed in one cluster, which is then split into smaller and smaller clusters. Bottom-up algorithms are more common, which at the beginning of work place each object in a separate cluster, and then combine the clusters into larger and larger ones until all objects in the sample are contained in one cluster. Thus, a system of nested partitions is constructed. The results of such algorithms are usually presented in the form of a tree.
The disadvantage of hierarchical algorithms is the system of full partitions, which may be redundant in the context of the problem being solved.
Consider now flat algorithms. The simplest among this class are the squared error algorithms. The clustering problem for these algorithms can be considered as constructing an optimal partitioning of objects into groups. In this case, the optimality can be defined as the requirement to minimize the mean square error of the partition:
 ,
,
where c j - "center of mass" of the cluster j(point with average values of characteristics for a given cluster).
The most common algorithm in this category is the k-means method. This algorithm builds a given number of clusters located as far apart as possible. The operation of the algorithm is divided into several stages:
Randomly choose k points that are the initial "centers of mass" of the clusters.
2. Assign each object to the cluster with the nearest "center of mass".
If the criterion for stopping the algorithm is not satisfied, return to item 2.
As a criterion for stopping the operation of the algorithm, the minimum change in the root mean square error is usually chosen. It is also possible to stop the operation of the algorithm if at step 2 there were no objects moved from cluster to cluster. The disadvantages of this algorithm include the need to specify the number of clusters for partitioning.
The most popular fuzzy clustering algorithm is the c-means algorithm. It is a modification of the k-means method. Algorithm steps:
1. Choose an initial fuzzy partition n objects on k clusters by choosing the membership matrix U size n x k.
2. Using the matrix U, find the value of the fuzzy error criterion:
 ,
,
where c k - "center of mass" of a fuzzy cluster k:
3. Regroup objects in order to decrease this value of the fuzzy error criterion.
4. Return to step 2 until the matrix changes U will not become insignificant.
This algorithm may not work if the number of clusters is unknown in advance, or it is necessary to unambiguously assign each object to one cluster.
The next group of algorithms are algorithms based on graph theory. The essence of such algorithms is that a selection of objects is represented in the form of a graph G = (V, E), the vertices of which correspond to objects, and the edges have a weight equal to the "distance" between the objects. The advantages of graph clustering algorithms are clarity, relative ease of implementation and the possibility of making various improvements based on geometric considerations. The main algorithms are the algorithm for extracting connected components, the algorithm for constructing the minimum spanning tree, and the layer-by-layer clustering algorithm.
To select a parameter R usually a histogram of pairwise distance distributions is plotted. In problems with a well-pronounced cluster structure of data, the histogram will have two peaks - one corresponds to intra-cluster distances, the second - to inter-cluster distances. Parameter R is selected from the zone of the minimum between these peaks. At the same time, it is rather difficult to control the number of clusters using the distance threshold.
The minimum spanning tree algorithm first constructs the minimum spanning tree on the graph and then sequentially removes the edges with the highest weight. The layer-by-layer clustering algorithm is based on the selection of connected components of the graph at a certain level of distances between objects (vertices). Distance level is set by distance threshold c... For example, if the distance between objects, then.
The layer-by-layer clustering algorithm forms a sequence of graph subgraphs G that reflect hierarchical relationships between clusters:
![]() ,
,
where G t = (V, E t )
- graph at the level with t, ![]() ,
,
with t is the t-th threshold of the distance, m is the number of hierarchy levels,
G 0 = (V, o), o is the empty set of graph edges obtained for t 0 = 1,
G m = G, that is, a graph of objects without restrictions on the distance (the length of the edges of the graph), since t m = 1.
By changing the distance thresholds ( with 0 , …, with m), where 0 = with 0 < with 1 < …< with m = 1, it is possible to control the depth of the hierarchy of the resulting clusters. Thus, the layer-by-layer clustering algorithm is capable of creating both flat and hierarchical data partitioning.
Clustering allows you to achieve the following goals:
· Improves understanding of data by identifying structural groups. Dividing the sample into groups of similar objects makes it possible to simplify further data processing and decision-making by applying its own analysis method to each cluster;
· Allows you to compactly store data. To do this, instead of storing the entire sample, you can leave one typical observation from each cluster;
· Detection of new atypical objects that were not included in any cluster.
Typically, clustering is used as an aid to data analysis.
2.6 Genetic algorithms
Genetic algorithms are among the universal optimization methods that allow solving problems of various types (combinatorial, general problems with and without restrictions) and of varying degrees of complexity. At the same time, genetic algorithms are characterized by the possibility of both single-criteria and multi-criteria search in a large space, the landscape of which is not smooth.
This group of methods uses an iterative process of evolution of the sequence of generations of models, including the operations of selection, mutation and crossing. At the beginning of the algorithm, the population is formed randomly. To assess the quality of coded solutions, the fitness function is used, which is necessary to calculate the fitness of each individual. According to the results of the assessment of individuals, the most adapted of them are selected for crossing. As a result of crossing selected individuals by using the genetic crossing-over operator, offspring are created, the genetic information of which is formed as a result of the exchange of chromosomal information between parent individuals. The created offspring form a new population, and some of the offspring mutate, which is expressed in a random change in their genotypes. The stage that includes the sequence "Population estimation" - "Selection" - "Crossing" - "Mutation" is called a generation. Population evolution consists of a sequence of such generations.
The following algorithms for selecting individuals for crossing are distinguished:
· Panmixia. Both individuals that make up the parental pair are randomly selected from the entire population. Any individual can become a member of several pairs. This approach is universal, but the efficiency of the algorithm decreases with an increase in the population size.
· Selection. Individuals with at least average fitness can become parents. This approach provides faster convergence of the algorithm.
· Inbreeding. The method is based on the formation of a couple based on close relationship. Here, kinship is understood as the distance between the members of the population, both in the sense of the geometric distance of individuals in the parameter space and the Heming distance between genotypes. Therefore, a distinction is made between genotypic and phenotypic inbreeding. The first member of the pair for crossing is chosen at random, and the second, with a greater probability, will be the individual as close to him as possible. Inbreeding can be characterized by the property of concentration of search in local nodes, which actually leads to the division of the population into separate local groups around areas of the landscape suspicious of extremum.
· Outbreeding. Formation of a pair based on distant relationship, for the most distant individuals. Outbreeding is aimed at preventing the convergence of the algorithm to already found solutions, forcing the algorithm to look for new, unexplored areas.
Algorithms for forming a new population:
· Selection with displacement. Of all individuals with the same genotypes, preference is given to those whose fitness is higher. Thus, two goals are achieved: the best found solutions with different chromosome sets are not lost; sufficient genetic diversity is constantly maintained in the population. Displacement forms a new population of far-flung individuals, instead of individuals grouping around the current solution found. This method is used for multi-extreme tasks.
· Elite selection. Elite selection methods ensure that the best members of the population are guaranteed to survive. At the same time, some of the best individuals pass into the next generation without any changes. The rapid convergence afforded by elite selection can be compensated for by an appropriate parental selection method. In this case, outbreeding is often used. It is this combination of "outbreeding - elite selection" that is one of the most effective.
· Tournament selection. Tournament selection implements n tournaments to select n individuals. Each tournament is built on a sample of k elements from the population, and the selection of the best individual among them. The most common tournament selection with k = 2.
One of the most popular applications of genetic algorithms in the field of Data Mining is the search for the most optimal model (search for an algorithm that matches the specifics of a particular area). Genetic algorithms are primarily used to optimize neural network topology and weights. However, it is also possible to use them as an independent tool.
3. Areas of application
Data Mining technology has a really wide range of applications, being, in fact, a set of universal tools for analyzing data of any type.
Marketing
One of the earliest areas where data mining technologies were applied was marketing. The task that started the development of Data Mining methods is called shopping basket analysis.
This task is to identify the products that buyers seek to purchase together. Knowledge of the shopping basket is necessary for advertising campaigns, the formation of personal recommendations for customers, the development of a strategy for creating stocks of goods and methods of their layout in sales areas.
Also in marketing, such tasks are solved as determining the target audience of a particular product for its more successful promotion; a study of time patterns that helps businesses make inventory decisions; creation of predictive models, which allows enterprises to recognize the nature of the needs of various categories of customers with certain behavior; predicting customer loyalty, which allows you to identify in advance the moment the customer leaves when analyzing his behavior and, possibly, prevent the loss of a valuable customer.
Industry
One of the important directions in this area is monitoring and quality control, where using analysis tools it is possible to predict equipment failure, the appearance of malfunctions, and plan repair work. Predicting the popularity of certain characteristics and knowing which characteristics are usually ordered together helps to optimize production, orienting it to the real needs of consumers.
Medicine
In medicine, data analysis is also used quite successfully. An example of tasks is the analysis of examination results, diagnostics, comparison of the effectiveness of treatment methods and drugs, analysis of diseases and their distribution, identification of side effects. Data Mining technologies such as association rules and sequential patterns have been successfully used to identify links between drug intake and side effects.
Molecular genetics and genetic engineering
Perhaps the most acute and at the same time clear task of discovering patterns in experimental data is in molecular genetics and genetic engineering. Here it is formulated as a definition of markers, which are understood as genetic codes that control certain phenotypic characteristics of a living organism. Such codes can contain hundreds, thousands or more related elements. The result of the analytical analysis of the data is also the relationship between changes in the DNA sequence of a person and the risk of developing various diseases, discovered by genetic scientists.
Applied chemistry
Data Mining methods are also used in the field of applied chemistry. Here the question often arises of elucidating the features of the chemical structure of certain compounds that determine their properties. This problem is especially relevant in the analysis of complex chemical compounds, the description of which includes hundreds and thousands of structural elements and their bonds.
Fighting crime
Data Mining tools have been used relatively recently in ensuring security, however, practical results have already been obtained confirming the effectiveness of data mining in this area. Swiss scientists have developed a system for analyzing protest activity in order to predict future incidents and a system for tracking emerging cyber threats and the actions of hackers in the world. The latter system allows predicting cyber threats and other information security risks. Also, Data Mining methods are successfully used to detect credit card fraud. By analyzing past transactions that later turned out to be fraudulent, the bank identifies some stereotypes of such fraud.
Other applications
· Risk analysis. For example, by identifying combinations of factors associated with paid claims, insurers can reduce their liability losses. There is a well-known case when a large insurance company in the United States discovered that the amounts paid on the statements of people who are married were twice the amount paid on the statements of single people. The company has responded to this new knowledge by revising its general discount policy for family customers.
· Meteorology. Weather forecasting using neural networks, in particular, self-organizing Kohonen maps are used.
· Personnel policy. Analysis tools help HR services to select the most successful candidates based on the analysis of their resume data, to model the characteristics of ideal employees for a particular position.
4. Producers of Data Mining Tools
Data Mining tools traditionally belong to expensive software products. Therefore, until recently, the main consumers of this technology were banks, financial and insurance companies, large trading enterprises, and the main tasks requiring the use of Data Mining were the assessment of credit and insurance risks and the development of marketing policy, tariff plans and other principles of working with clients. In recent years, the situation has undergone certain changes: relatively inexpensive Data Mining tools and even free distribution systems have appeared on the software market, which made this technology available for small and medium-sized businesses.
Among the paid tools and data analysis systems, the leaders are SAS Institute (SAS Enterprise Miner), SPSS (SPSS, Clementine) and StatSoft (STATISTICA Data Miner). Quite well-known are solutions from Angoss (Angoss KnowledgeSTUDIO), IBM (IBM SPSS Modeler), Microsoft (Microsoft Analysis Services) and (Oracle) Oracle Data Mining.
The choice of free software is also varied. There are both universal analysis tools, such as JHepWork, KNIME, Orange, RapidMiner, and specialized tools, for example, Carrot2 - a framework for clustering text data and search results, Chemicalize.org - a solution in the field of applied chemistry, NLTK (Natural Language Toolkit) natural language processing tool.
5. Criticism of methods
Data Mining results largely depend on the level of data preparation, and not on the "miraculous capabilities" of some algorithm or set of algorithms. About 75% of the work on Data Mining consists of collecting data, which is done even before the use of analysis tools. Illiterate use of tools will lead to a senseless waste of the company's potential, and sometimes millions of dollars.
According to Herb Edelstein, a world renowned expert in Data Mining, Data Warehousing and CRM: “A recent study by Two Crows showed that Data Mining is still in its early stages. Many organizations are interested in this technology, but only a few are actively implementing such projects. We managed to find out another important point: the process of implementing Data Mining in practice turns out to be more complicated than expected. The teams were carried away by the myth that Data Mining tools are easy to use. It is assumed that it is enough to run such a tool on a terabyte database, and useful information will immediately appear. In fact, a successful Data Mining project requires an understanding of the essence of the activity, knowledge of data and tools, as well as the process of data analysis. " Thus, before using the Data Mining technology, it is necessary to carefully analyze the limitations imposed by the methods and the critical issues associated with it, as well as soberly assess the capabilities of the technology. Critical issues include the following:
1. Technology cannot provide answers to questions that have not been asked. It cannot replace the analyst, but only provides him with a powerful tool to facilitate and improve his work.
2. The complexity of the development and operation of the Data Mining application.
Since this technology is a multidisciplinary field, to develop an application that includes Data Mining, it is necessary to involve specialists from different fields, as well as to ensure their high-quality interaction.
3. User qualifications.
Different Data Mining tools have different degrees of user friendliness and require certain user qualifications. Therefore, the software must correspond to the user's training level. The use of Data Mining should be inextricably linked with the improvement of the user's qualifications. However, there are currently few Data Mining specialists who are well versed in business processes.
4. Extraction of useful information is impossible without a good understanding of the essence of the data.
Careful model selection and interpretation of the dependencies or patterns that are found are required. Therefore, working with such tools requires close collaboration between the subject matter expert and the Data Mining tool specialist. Standing models must be intelligently integrated into business processes in order to be able to evaluate and update models. Recently, Data Mining systems have been shipped as part of data warehouse technology.
5. Complexity of data preparation.
Successful analysis requires high-quality data preprocessing. According to analysts and database users, the preprocessing process can take up to 80% of the entire Data Mining process.
Thus, in order for the technology to work for itself, it will take a lot of effort and time, which are spent on preliminary data analysis, model selection and its correction.
6. A large percentage of false, unreliable or useless results.
With the help of Data Mining technologies, you can find really very valuable information that can give a significant advantage in further planning, management, and decision-making. However, the results obtained using Data Mining methods quite often contain false and meaningless conclusions. Many experts argue that Data Mining tools can produce a huge amount of statistically unreliable results. To reduce the percentage of such results, it is necessary to check the adequacy of the obtained models on test data. However, it is impossible to completely avoid false conclusions.
7. High cost.
A quality software product is the result of significant effort on the part of the developer. Therefore, Data Mining software is traditionally considered an expensive software product.
8. Availability of sufficient representative data.
Data Mining tools, unlike statistical ones, theoretically do not require a strictly defined amount of historical data. This feature can cause the detection of inaccurate, false models and, as a result, the adoption of incorrect decisions based on them. It is necessary to control the statistical significance of the discovered knowledge.
neural network algorithm clustering data mining
Conclusion
A brief description of the spheres of application is given and criticism of the Data Mining technology and the opinion of experts in this area are given.
Listliterature
1. Han and Micheline Kamber. Data Mining: Concepts and Techniques. Second Edition. - University of Illinois at Urbana-Champaign
Berry, Michael J. A. Data mining techniques: for marketing, sales, and customer relationship management - 2nd ed.
Siu Nin Lam. Discovering Association Rules in Data Mining. - Department of Computer Science University of Illinois at Urbana-Champaign
Send your good work in the knowledge base is simple. Use the form below
Students, graduate students, young scientists who use the knowledge base in their studies and work will be very grateful to you.
Similar documents
- analysis of customer trajectories from visiting a website to purchasing goods
- evaluation of service efficiency, analysis of failures due to lack of goods
- linking goods that are interesting to visitors
- shopping basket analysis;
- creating predictive models and classification models of buyers and purchased goods;
- creating customer profiles;
- CRM, assessment of customer loyalty of different categories, planning of loyalty programs;
- time series research and time dependences, highlighting seasonal factors, evaluating the effectiveness of promotions on a large range of real data.
- customer classification based on key characteristics of calls (frequency, duration, etc.), SMS frequency;
- identifying customer loyalty;
- definition of fraud, etc.
- risk analysis... By identifying combinations of factors associated with paid claims, insurers can reduce their liability losses. There is a known case when an insurance company found that the amounts paid on the claims of people who are married were twice the amount paid on the claims of single people. The company has responded by revising its family discount policy.
- fraud detection... Insurance companies can reduce fraud by looking for specific stereotypes in claims that characterize the relationship between lawyers, doctors and claimants.
Classification of DataMining tasks. Creation of reports and totals. Data Miner features in Statistica. Classification, clustering and regression problem. Analysis tools Statistica Data Miner. The essence of the problem is the search for association rules. Survival predictor analysis.
term paper, added 05/19/2011
Description of the functionality of the Data Mining technology as a process for detecting unknown data. Study of systems of inference of associative rules and mechanisms of neural network algorithms. Description of clustering algorithms and areas of application of Data Mining.
test, added 06/14/2013
Basics for clustering. Using Data Mining as a way to "discover knowledge in databases". Choice of clustering algorithms. Retrieving data from the database storage of the remote workshop. Clustering students and tasks.
term paper added on 07/10/2017
Data mining, developmental history of data mining and knowledge discovery. Technological elements and methods of data mining. Steps in knowledge discovery. Change and deviation detection. Related disciplines, information retrieval and text extraction.
report added on 06/16/2012
Analysis of the problems arising from the application of clustering methods and algorithms. Basic algorithms for clustering. RapidMiner software as an environment for machine learning and data analysis. Assessment of the quality of clustering using Data Mining methods.
term paper, added 10/22/2012
Improvement of data recording and storage technologies. Specificity of modern requirements for information data processing. The concept of patterns reflecting fragments of multidimensional relationships in data at the heart of modern Data Mining technology.
test, added 09/02/2010
Analysis of the use of neural networks for predicting the situation and making decisions in the stock market using the Trajan 3.0 neural network modeling software package. Conversion of primary data, tables. Ergonomic program evaluation.
thesis, added 06/27/2011
Difficulties in using evolutionary algorithms. Building computing systems based on the principles of natural selection. Disadvantages of genetic algorithms. Examples of evolutionary algorithms. Directions and sections of evolutionary modeling.
We welcome you to the Data Mining Portal - a unique portal dedicated to modern Data Mining methods.
Data Mining technologies are a powerful tool of modern business intelligence and data mining for discovering hidden patterns and building predictive models. Data Mining or knowledge mining is based not on speculative reasoning, but on real data.

Rice. 1. Scheme of Data Mining application
Problem Definition - Statement of the problem: data classification, segmentation, building predictive models, forecasting.
Data Gathering and Preparation - Data collection and preparation, cleaning, verification, deletion of duplicate records.
Model Building - Model building, accuracy assessment.
Knowledge Deployment - Application of a model to solve a given problem.
Data Mining is used to implement large-scale analytical projects in business, marketing, the Internet, telecommunications, industry, geology, medicine, pharmaceuticals and other fields.
Data Mining allows you to start the process of finding significant correlations and connections as a result of sifting through a huge array of data using modern methods of pattern recognition and the use of unique analytical technologies, including decision trees and classifications, clustering, neural network methods, and others.
A user who first discovered the technology of data mining is amazed at the abundance of methods and effective algorithms that allow finding approaches to solving difficult problems associated with the analysis of large amounts of data.
In general, Data Mining can be characterized as a technology designed to search in large amounts of data. unobvious, objective and practically useful patterns.
Data Mining is based on efficient methods and algorithms developed for the analysis of unstructured data of large volume and dimension.
The key point is that high-volume, high-dimensional data appears to be devoid of structure and connections. The goal of data mining technology is to identify these structures and find patterns where, at first glance, chaos and arbitrariness reign.
Here is a current case study of data mining applications in the pharmaceutical and drug industries.
Drug interactions are a growing problem facing modern healthcare.
Over time, the number of prescribed drugs (over-the-counter and all kinds of supplements) increases, making it more and more likely that drug interactions can cause serious side effects that doctors and patients are unaware of.
This area belongs to postclinical research, when a drug has already been launched on the market and is being used intensively.
Clinical trials relate to the assessment of the effectiveness of a drug, but do not take into account the interactions of this drug with other drugs on the market.
Researchers at Stanford University in California examined the Food and Drug Administration (FDA) database of drug side effects and found that two commonly used drugs - the antidepressant paroxetine and pravastatin, used to lower cholesterol levels - increase risk of developing diabetes if used together.
A study conducting a similar analysis based on FDA data identified 47 previously unknown adverse interactions.
This is remarkable, with the caveat that many of the negative effects reported by patients go unrecognized. This is where online search can do its best.
Upcoming Data Mining courses at StatSoft Data Analysis Academy in 2020
We start our acquaintance with Data Mining using the wonderful videos of the Academy of Data Analysis.
Be sure to watch our videos, and you will understand what Data Mining is!
Video 1. What is Data Mining?
Video 2. Overview of data mining methods: decision trees, generalized predictive models, clustering and much more
JavaScript is disabled in your browser
Before starting a research project, we must organize the process of obtaining data from external sources, now we will show how this is done.
The video will introduce you to the unique technology STATISTICA In-place database processing and data mining connection with real data.
Video 3. The order of interaction with databases: graphical interface for building SQL queries In-place database processing technology
JavaScript is disabled in your browser
We now look at interactive drilling technologies that are effective in exploration data analysis. The term drilling itself reflects the connection between Data Mining technology and geological exploration.
Video 4. Interactive Drilling: Exploration and Graphical Techniques for Interactive Data Exploration
JavaScript is disabled in your browser
Now we will get acquainted with the analysis of associations (association rules), these algorithms allow you to find relationships that exist in real data. The key point is the efficiency of algorithms on large amounts of data.
The result of link analysis algorithms, for example, the Apriori algorithm, is the finding of link rules for the objects under study with a given reliability, for example, 80%.
In geology, these algorithms can be used in exploratory analysis of minerals, for example, how feature A is associated with features B and C.
You can find specific examples of such solutions by following our links:
In retail, the Apriori algorithm or their modifications allow you to investigate the relationship of various products, for example, when selling perfumes (perfume - varnish - mascara, etc.) or goods of different brands.
The analysis of the most interesting sections on the site can also be effectively carried out using the rules of associations.
So, check out our next video.
Video 5. Association rules
JavaScript is disabled in your browser
Let's give examples of Data Mining application in specific areas.
Online commerce:
Retail: Analyze customer information based on credit cards, discount cards, and more.
Typical retail tasks solved by Data Mining tools:
The telecommunications sector opens up unlimited opportunities for the application of data mining methods, as well as modern big data technologies:
Insurance:
The practical application of data mining and solving specific problems is presented in our next video.
Webinar 1. Webinar "Practical Data Mining Tasks: Problems and Solutions"
JavaScript is disabled in your browserWebinar 2. Webinar "Data Mining and Text Mining: Examples of Solving Real Problems"
JavaScript is disabled in your browser
You can get a deeper knowledge of the methodology and technology of data mining at StatSoft courses.